
Gemini 2.5 Flash API is het nieuwste multimodale AI-model van Google, ontworpen voor snelle, kostenefficiënte taken met controleerbare redeneermogelijkheden, waardoor ontwikkelaars geavanceerde 'denk'-functies via de Gemini API in of uit kunnen schakelen. De nieuwste modellen zijn gemini-2.5-flash.
Overzicht van Gemini 2.5 Flash
Gemini 2.5 Flash is ontworpen om snelle reacties te leveren zonder in te leveren op de kwaliteit van de output. Het ondersteunt multimodale input, waaronder tekst, afbeeldingen, audio en video, waardoor het geschikt is voor diverse toepassingen. Het model is toegankelijk via platforms zoals Google AI Studio en Vertex AI, en biedt ontwikkelaars de tools die nodig zijn voor naadloze integratie in verschillende systemen.
Basisgegevens (functies)
Gemini 2.5 Flash introduceert verschillende opvallende functionaliteiten die het onderscheiden binnen de Gemini 2.5-familie:
- Hybride redenering:Ontwikkelaars kunnen een denk_budget parameter om nauwkeurig te bepalen hoeveel tokens het model toewijst aan intern redeneren voordat het output genereert.
- Pareto-grens: Gepositioneerd op de optimaal kosten-prestatiepuntFlash biedt de beste prijs-/intelligentieverhouding van 2.5 modellen.
- Multimodale ondersteuning: Processen tekst, afbeeldingen, **video-**en audio op een natuurlijke manier, waardoor rijkere conversatie- en analysemogelijkheden mogelijk worden.
- Context van 1 miljoen tokens:Ongeëvenaarde contextlengte maakt diepgaande analyse en begrip van lange documenten mogelijk in één aanvraag.
Modelversies
Gemini 2.5 Flash is overgegaan naar de volgende sleutel versies:
- gemini-2.5-flash-lite-preview-09-2025: Verbeterde bruikbaarheid van de tool: verbeterde prestaties bij complexe taken met meerdere stappen, met een 5% hogere SWE-Bench Verified-score (van 48.9% naar 54%). Verbeterde efficiëntie: wanneer redenering is ingeschakeld, wordt een hogere kwaliteit output bereikt met minder tokens, wat de latentie en kosten verlaagt.
- Voorbeschouwing 04-17: Vroege toegangsrelease met “denk”-mogelijkheid, beschikbaar via gemini-2.5-flash-preview-04-17.
- Stabiele algemene beschikbaarheid (GA): Vanaf 17 juni 2025 is het stabiele eindpunt gemini-2.5-flits vervangt de preview en zorgt voor betrouwbaarheid op productieniveau zonder API-wijzigingen ten opzichte van de preview van 20 mei.
- Veroudering van Preview: Preview-eindpunten zouden op 15 juli 2025 worden afgesloten. Gebruikers moeten vóór deze datum naar het GA-eindpunt migreren.
Vanaf juli 2025 is Gemini 2.5 Flash nu publiekelijk beschikbaar en stabiel (geen wijzigingen ten opzichte van de gemini-2.5-flash-preview-05-20 ).Als u gebruik maakt van gemini-2.5-flash-preview-04-17De bestaande previewprijzen blijven van kracht tot de geplande stopzetting van het modeleindpunt op 15 juli 2025, waarna het wordt stopgezet. U kunt migreren naar het algemeen beschikbare model.gemini-2.5-flash".
Sneller, goedkoper, slimmer:
- Ontwerpdoelen: lage latentie + hoge doorvoer + lage kosten;
- Algemene versnelling van redeneren, multimodale verwerking en lange teksttaken;
- Het gebruik van tokens wordt met 20-30% verminderd, waardoor de redeneerkosten aanzienlijk worden verlaagd.
Technische specificaties
Input Context Window: Maximaal 1 miljoen tokens, waardoor uitgebreide contextretentie mogelijk is.
Uitvoertokens: Kan maximaal 8,192 tokens per respons genereren.
Ondersteunde modaliteiten: tekst, afbeeldingen, audio en video.
Integratieplatforms: beschikbaar via Google AI Studio en Vertex AI.
Prijzen: Concurrerend token-gebaseerd prijsmodel, wat een kosteneffectieve implementatie mogelijk maakt.
Technische gegevens
Onder de motorkap is Gemini 2.5 Flash een transformator gebaseerd groot taalmodel getraind op een combinatie van web-, code-, beeld- en videogegevens. Sleutel technisch specificaties omvatten:
Multimodale training: Flash is getraind om meerdere modaliteiten op één lijn te brengen en kan tekst naadloos mengen met afbeeldingen, **video-**of audio, handig voor taken zoals het samenvatten van video's of het ondertitelen van audio.
Dynamisch denkproces: Implementeert een interne redeneerlus waarbij het model pakketten en breekt complexe prompts af vóór de uiteindelijke output.
Configureerbare denkbudgettenDe denk_budget kan worden ingesteld vanaf 0 (geen redenering) tot 24,576 tokens, waardoor afwegingen tussen latentie en antwoordkwaliteit mogelijk zijn.
Tool-integratie: Ondersteunt Gronding met Google Zoeken, Code-uitvoering, URL-contexten Functie Bellen, waardoor directe, realistische acties mogelijk worden vanuit natuurlijke taalprompts.
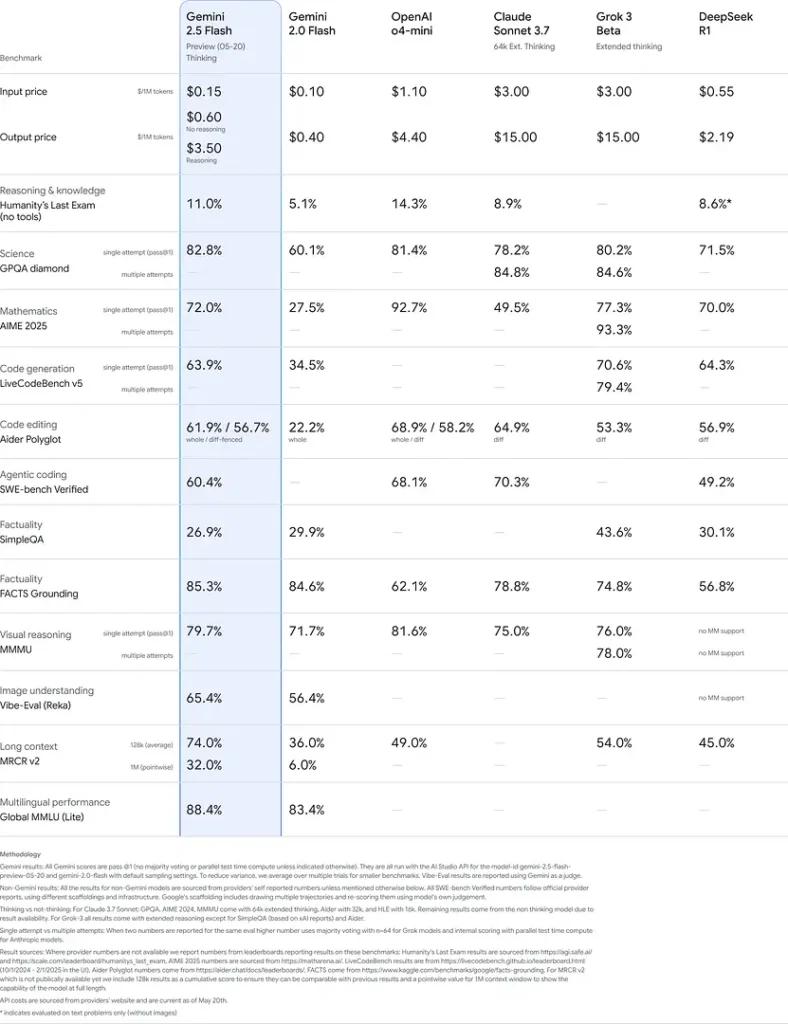
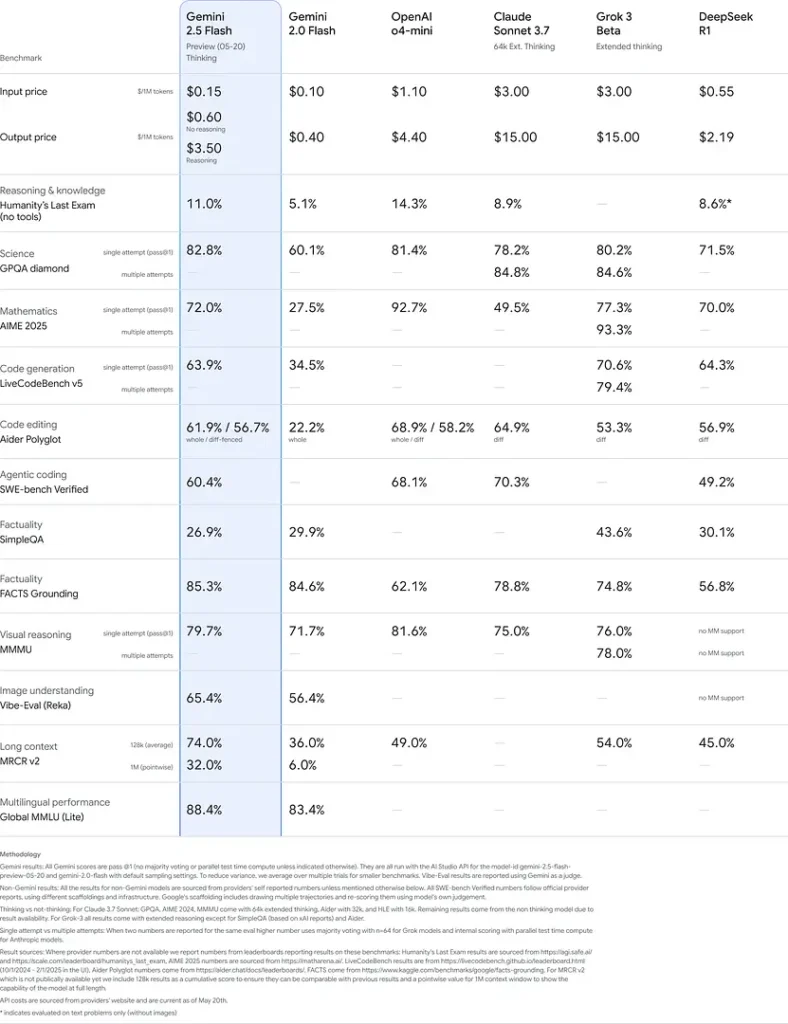
Benchmarkprestaties
Uit strenge evaluaties blijkt dat Gemini 2.5 Flash toonaangevende prestatie:
- LMArena Harde Prompts: Gescoord alleen tweede na 2.5 Pro op de uitdagende Hard Prompts-benchmark, waarbij sterke mogelijkheden voor meerstaps redeneren werden gedemonstreerd.
- MMLU-score van 0.809: Overtreft de gemiddelde modelprestaties met een 0.809 De nauwkeurigheid van MMLU weerspiegelt de brede domeinkennis en het redeneervermogen.
- Latentie en doorvoer: Bereikt 271.4 tokens/sec decoderingssnelheid met een 0.29 s Tijd tot eerste tokenwaardoor het ideaal is voor latentiegevoelige workloads.
- Prijs-prestatieleider: Op $0.26/1 miljoen tokensFlash ondermijnt veel concurrenten, maar evenaart of overtreft ze op belangrijke benchmarks.
Deze resultaten geven aan dat Gemini 2.5 Flash een concurrentievoordeel heeft op het gebied van redeneren, wetenschappelijk inzicht, wiskundige probleemoplossing, codering, visuele interpretatie en meertalige mogelijkheden:
Beperkingen
Hoewel Gemini 2.5 Flash krachtig is, bevat het bepaalde beperkingen:
- Veiligheidsrisico's: Het model kan een “prekerige” toon en kan plausibel klinkende maar onjuiste of bevooroordeelde uitkomsten (hallucinaties) opleveren, met name bij grensgevallen. Strikt menselijk toezicht blijft essentieel.
- Tarieflimieten:API-gebruik wordt beperkt door snelheidslimieten (10 RPM, 250,000 TPM, 250 RPD op standaardlagen), wat van invloed kan zijn op batchverwerking of toepassingen met een hoog volume.
- Inlichtingenafdeling: Hoewel uitzonderlijk geschikt voor een flash model, blijft het minder nauwkeurig dan 2.5 Pro bij de meest veeleisende agenttaken, zoals geavanceerde codering of multi-agentcoördinatie.
- Kostenafwegingen: Hoewel het de beste biedt prijs-prestatie, uitgebreid gebruik van de het denken De modus verhoogt het totale tokenverbruik, waardoor de kosten voor diepgaande redeneeropdrachten toenemen.
Zie ook Gemini 2.5 Pro-API
Conclusie
Gemini 2.5 Flash is een bewijs van Googles toewijding aan het verbeteren van AI-technologieën. Met zijn robuuste prestaties, multimodale mogelijkheden en efficiënte resourcebeheer biedt het een complete oplossing voor ontwikkelaars en organisaties die de kracht van kunstmatige intelligentie (AI) in hun bedrijfsvoering willen benutten.
Hoe te bellen Gemini 2.5 Flash API van CometAPI
Gemini 2.5 Flash API-prijzen in CometAPI, 20% korting op de officiële prijs:
- Invoertokens: $0.24 / M tokens
- Uitvoertokens: $0.96/M tokens
Vereiste stappen
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
- Haal de url van deze site op: https://api.cometapi.com/
Gebruiksmethoden
- Selecteer de optie "
gemini-2.5-flash"eindpunt om de API-aanvraag te versturen en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak. - Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
Voor informatie over het model dat in Comet API is opgenomen, zie https://api.cometapi.com/new-model.
Voor informatie over de modelprijs in Comet API, zie https://api.cometapi.com/pricing.
API-gebruiksvoorbeeld
Ontwikkelaars kunnen interacteren met gemini-2.5-flits via de API van CometAPI, waardoor integratie in verschillende applicaties mogelijk is. Hieronder ziet u een Python-voorbeeld:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Dit script stuurt een prompt naar de Gemini 2.5 Flash modelleert en print de gegenereerde respons, waarbij wordt gedemonstreerd hoe u deze kunt gebruiken Gemini 2.5 Flash voor complexe uitleg.