

GLM-4.6 is de nieuwste grote release in de GLM-familie van Z.ai (voorheen Zhipu AI): een vierde generatie, grote taal MoE (Mixture-of-Experts)-model afgestemd op agentische workflows, lange-context redeneren en real-world coderingDe release benadrukt de praktische agent/tool-integratie, een zeer grote contextvensteren open-gewicht beschikbaarheid voor lokale implementatie.
Belangrijkste kenmerken
- Lange context - oorspronkelijk 200K-token Contextvenster (uitgebreid van 128K). ()
- Codering en agentcapaciteit — verbeteringen op de markt gebracht voor echte coderingstaken en betere toolaanroeping voor agenten.
- Efficiëntie — gerapporteerd ~30% lager tokenverbruik vs GLM-4.5 op Z.ai's tests.
- Implementatie en kwantificering — kondigde als eerste FP8- en Int4-integratie aan voor Cambricon-chips; native FP8-ondersteuning op Moore Threads via vLLM.
- Modelgrootte en tensortype — gepubliceerde artefacten duiden op een ~357B-parameter model (BF16 / F32 tensoren) op Hugging Face.
Technische details
Modaliteiten en formaten. GLM-4.6 is een alleen tekst LLM (invoer- en uitvoermodaliteiten: tekst). Contextlengte = 200K tokens; maximale output = 128K tokens.
Kwantisering en hardwareondersteuning. Het team rapporteert FP8/Int4-kwantisering op Cambricon-chips en native FP8 uitvoering op Moore Threads GPU's met behulp van vLLM voor inferentie — belangrijk voor het verlagen van inferentiekosten en het mogelijk maken van implementaties in de lokale en binnenlandse cloud.
Tooling en integraties. GLM-4.6 wordt gedistribueerd via de API van Z.ai, netwerken van externe providers (bijv. CometAPI) en geïntegreerd in coderingsagents (Claude Code, Cline, Roo Code, Kilo Code).
Technische details
Modaliteiten en formaten. GLM-4.6 is een alleen tekst LLM (invoer- en uitvoermodaliteiten: tekst). Contextlengte = 200K tokens; maximale output = 128K tokens.
Kwantisering en hardwareondersteuning. Het team rapporteert FP8/Int4-kwantisering op Cambricon-chips en native FP8 uitvoering op Moore Threads GPU's met behulp van vLLM voor inferentie — belangrijk voor het verlagen van inferentiekosten en het mogelijk maken van implementaties in de lokale en binnenlandse cloud.
Tooling en integraties. GLM-4.6 wordt gedistribueerd via de API van Z.ai, netwerken van externe providers (bijv. CometAPI) en geïntegreerd in coderingsagents (Claude Code, Cline, Roo Code, Kilo Code).
Benchmarkprestaties
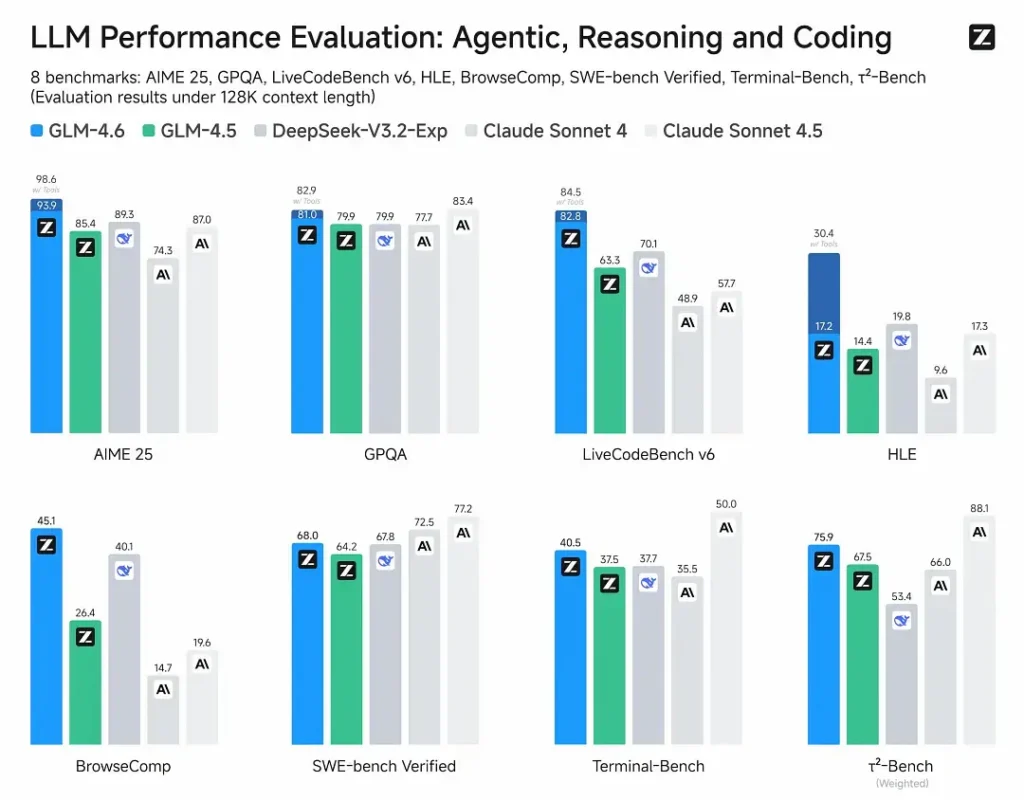
- Gepubliceerde evaluaties: GLM-4.6 werd getest op acht openbare benchmarks die betrekking hadden op agenten, redeneren en coderen en toont duidelijke winst ten opzichte van GLM-4.5Bij door mensen geëvalueerde, real-world coderingstesten (uitgebreide CC-Bench) gebruikt GLM-4.6 ~15% minder tokens vs GLM-4.5 en plaatst een ~48.6% winstpercentage vs Anthropic's Claude Sonnet 4 (bijna gelijk op veel ranglijsten).
- positionering: Uit de resultaten blijkt dat GLM-4.6 kan concurreren met toonaangevende binnenlandse en internationale modellen (geciteerde voorbeelden zijn DeepSeek-V3.1 en Claude Sonnet 4).
Beperkingen en risico's
- Hallucinaties en fouten: Net als alle huidige LLM's kan GLM-4.6 feitelijke fouten bevatten. De documentatie van Z.ai waarschuwt expliciet dat de uitvoer fouten kan bevatten. Gebruikers dienen verificatie en opvraging/RAG toe te passen voor kritieke content.
- Modelcomplexiteit en bedieningskosten: 200K context en zeer grote outputs verhogen de vraag naar geheugen en latentie aanzienlijk en kunnen de kosten voor inferentie verhogen. Om op grote schaal te kunnen werken, is gekwantificeerde/inferentietechniek vereist.
- Domeinhiaten: terwijl GLM-4.6 sterke agent/coderingsprestaties rapporteert, merken sommige openbare rapporten op dat het nog steeds loopt achter op bepaalde versies van concurrerende modellen in specifieke microbenchmarks (bijv. bepaalde coderingsmetrieken versus Sonnet 4.5). Beoordeel per taak voordat u productiemodellen vervangt.
- Veiligheid en beleid: Open gewichten vergroten de toegankelijkheid, maar roepen ook vragen op over beheer (mitigatiemaatregelen, vangrails en red-teaming blijven de verantwoordelijkheid van de gebruiker).
Use cases
- Agentsystemen en toolorkestratie: lange agent-traces, multi-tool-planning, dynamische tool-aanroeping; de agent-afstemming van het model is een belangrijk verkoopargument.
- Assistenten voor programmeren in de echte wereld: multi-turn codegeneratie, codebeoordeling en interactieve IDE-assistenten (geïntegreerd in Claude Code, Cline, Roo Code—per Z.ai). Verbeteringen in de tokenefficiëntie Maak het aantrekkelijk voor ontwikkelaars die intensief gebruikmaken van hun plannen.
- Workflows voor lange documenten: samenvatting, synthese van meerdere documenten, lange juridische/technische beoordelingen vanwege het venster van 200K.
- Contentcreatie en virtuele karakters: Uitgebreide dialogen en consistent persona-onderhoud in scenario's met meerdere beurten.
Hoe GLM-4.6 zich verhoudt tot andere modellen
- GLM-4.5 → GLM-4.6: stapverandering in contextgrootte (128K → 200K) en tokenefficiëntie (~15% minder tokens op CC-Bench); verbeterd gebruik van agenten/tools.
- GLM-4.6 versus Claude Sonnet 4 / Sonnet 4.5: Z.ai rapporteert bijna gelijkheid op verschillende ranglijsten en een winstpercentage van ~48.6% op de CC-Bench real-world coding-taken (d.w.z. een sterke concurrentie, met enkele microbenchmarks waar Sonnet nog steeds de leiding heeft). Voor veel engineeringteams wordt GLM-4.6 gepositioneerd als een kostenefficiënt alternatief.
- GLM-4.6 versus andere lange-contextmodellen (DeepSeek, Gemini-varianten, GPT-4-familie): GLM-4.6 legt de nadruk op grote context- en agent-coderingsworkflows; de relatieve sterkte hangt af van de metriek (tokenefficiëntie/agent-integratie versus nauwkeurigheid van ruwe codesynthese of veiligheidspipelines). Empirische selectie moet taakgestuurd zijn.
Het nieuwste vlaggenschipmodel van Zhipu AI, de GLM-4.6, is uitgebracht: 355B totale parameters, waarvan 32B actief. Overtreft GLM-4.5 op alle kernfuncties.
- Codering: Uitgelijnd met Claude Sonnet 4, het beste in China.
- Context: Uitgebreid naar 200K (van 128K).
- Reden: Verbeterd, ondersteunt het aanroepen van tools tijdens inferentie.
- Zoeken: Verbeterde toolaanroepen en agentprestaties.
- Schrijven: Sluit beter aan bij menselijke voorkeuren qua stijl, leesbaarheid en rollenspel.
- Meertalig: verbeterde vertaling in meerdere talen.
Hoe te bellen GLM-**4.**6 API van CometAPI
GLM‑4.6 API-prijzen in CometAPI, 20% korting op de officiële prijs:
- Invoertokens: $0.64 miljoen tokens
- Uitvoertokens: $2.56/M tokens
Vereiste stappen
- Inloggen cometapi.comAls u nog geen gebruiker bent, registreer u dan eerst.
- Log in op uw CometAPI-console.
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.

Gebruik methode
- Selecteer de optie "
glm-4.6"eindpunt om de API-aanvraag te versturen en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak. - Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
CometAPI biedt een volledig compatibele REST API voor een naadloze migratie. Belangrijke details voor API-document:
- Basis-URL: https://api.cometapi.com/v1/chat/completions
- Modelnamen: "
glm-4.6" - authenticatie:
Bearer YOUR_CometAPI_API_KEYhoofd - Content-Type:
application/json.
API-integratie en voorbeelden
Hieronder is een Python Fragment dat demonstreert hoe GLM-4.6 kan worden aangeroepen via de API van CometAPI. Vervangen <API_KEY> en <PROMPT> overeenkomstig:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Hoofdparameters:
- model: Specificeert de GLM‑4.6-variant
- max_tokens: Regelt de uitvoerlengte
- temperatuur-: Past creativiteit aan vs. determinisme
Zie ook Claude Sonnet 4.5