

Google DeepMind heeft vandaag aanzienlijke uitbreidingen van zijn Gemini 2.5-familie aangekondigd, met de stabiele releases van Gemini 2.5 Pro en Gemini 2.5 Flash, naast een preview van het gloednieuwe Gemini 2.5 Flash-Lite-model. Deze updates weerspiegelen Googles voortdurende toewijding aan het aanbieden van een scala aan AI-modellen die kosten, snelheid en prestaties in evenwicht brengen voor uiteenlopende workloads.
Stabiele releases: Gemini 2.5 Pro & Flash
Op 17 juni 2025 kondigde Google de algemene beschikbaarheid aan van Gemini 2.5 Pro en Gemini 2.5 Flash. De Pro-variant biedt maximale redeneerkracht en is speciaal ontworpen voor zeer complexe taken zoals geavanceerde codegeneratie, wetenschappelijke analyse en grootschalige datasynthese. Gemini 2.5 Flash daarentegen biedt een middenklasse-optie die geoptimaliseerd is voor dagelijks gebruik dat een lage latentie vereist – ideaal voor chatbots, samenvattingen en grootschalige contentcreatie.
Overzicht: Drie modellen in de Gemini-2.5-familie
| Model | Status | Sterke punten | Ideale gebruiksgevallen |
|---|---|---|---|
| Gemini 2.5 Flash-Lite (voorbeeld) | Voorbeschouwing | Snelst en goedkoopst; multimodaal; controleerbaar redeneren; tool-enabled | Taken met een hoog volume, zoals chatbots, samenvattingen en zoekopdrachten |
| Gemini 2.5 Flash | Stal | Gebalanceerd: lage latentie, goede redenering, multimodaal | Realtime gesprekken, klantenondersteuning |
| Gemini 2.5 Pro | Stal | Meest capabel: diepgaand redeneren, grote context, multimodaal | Onderzoek, complexe codering, wetenschappelijke taken |
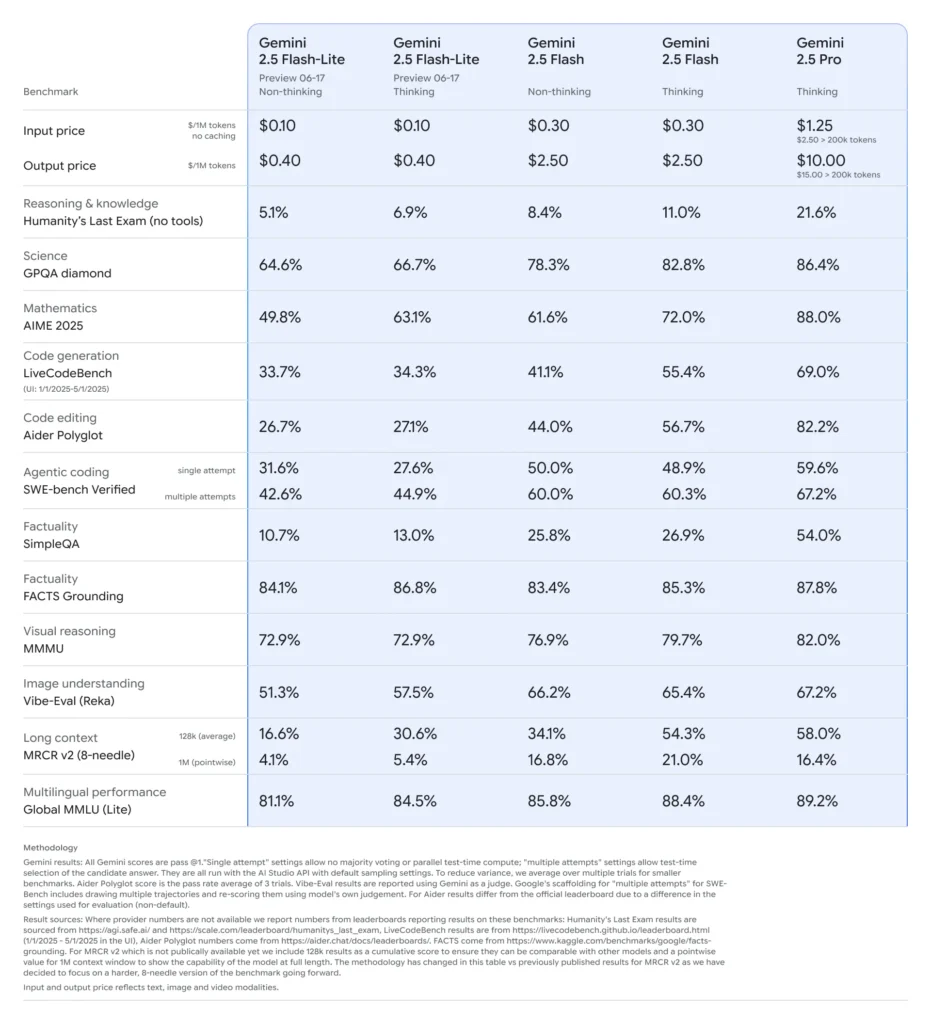
Gemini 2.5 Flash-Lite: Preview Hoogtepunten
Ultralage latentie en kostenbesparingenOntworpen voor grootschalige realtimetoepassingen zoals vertaling, classificatie en samenvatting. Biedt snellere inferentie en lagere kosten per gesprek in vergelijking met zowel 2.0 Flash-Lite als de volledige Flash-versie.
Verbeterde fundamentele prestaties: Overtreft eerdere Flash‑Lite-modellen in benchmarks op het gebied van codegeneratie, logica, wiskunde, multimodaal redeneren en wetenschap.
Kosten en efficiëntie: Flash‑Lite-prijzen (preview): ~$0.10 per 1M input-tokens en ~$0.40 per 1M output-tokens — aanzienlijk goedkoper dan Flash ($0.30/$2.50) en Pro ($1.25/$10).
Volledige Gemini -2.5 mogelijkheden:
- Controleerbaar denkenGebruikers kunnen 'denkbudgetten' (tokenlimieten) instellen om snelheid in te ruilen voor diepgang. Flash‑Lite kan dit indien nodig in- of uitschakelen.
- Multimodale invoer: Ondersteunt tekst, afbeeldingen, audio en video (inclusief clips van een uur), met mogelijkheden om grafieken, gebruikersinterfaces, scènes en samenvattingen van gebeurtenissen te analyseren.
- Tool-integratie: Inclusief Google Zoeken, code-uitvoering en een contextvenster met een miljoen tokens, wat overeenkomt met de mogelijkheden van Flash en Pro.
Positionering op de prijs-prestatiecurve
Google positioneert de hoge snelheid en lage kosten van Flash-Lite als de Pareto-grens, wat betekent dat het een van de meest kostenefficiënte en tegelijkertijd capabele modellen ter wereld is (). In vergelijkende evaluaties, Flash-Lite vertegenwoordigt de beste waarde: slim en toch betaalbaar.
Over Flash en Pro
- Gemini 2.5 Flash: Stabiel, lage latentie, multimodaal denkmodel. Gepositioneerd onder Pro, maar qua capaciteit ongeveer gelijk aan GPT-4o, met superieure snelheid en kostenefficiëntie ().
- Gemini 2.5 Pro: Googles meest geavanceerde model. Bekend om de verwerking van urenlange video/audio, complexe code en wiskunde, en contextueel redeneren. Introduceert ook selectieve "denkbudgetten" en verbeterde codekwaliteit om te dienen als een stabiele vlaggenschip-AI op lange termijn.
Implementatie en prijzen
- beschikbaarheid:Alle drie de modellen zijn toegankelijk via Google AI Studio, Google Cloud Vertex-AIEn Gemini-app .
- Kostenstructuur (Vertex AI-prijzen vanaf 16 juni 2025):
- Pro: $1.25/1M input, $10/1M output (hoger dan 200K tokens)
- flash: $0.15/1M input, $3.50/1M output in de “denk”-modus – en bevat 1,500 gratis geaarde prompts per dag ()
- Flash-Lite (voorbeeld): ~$0.10/$0.40 per 1 miljoen tokens
Beginnen
CometAPI biedt een uniforme REST-interface die honderden AI-modellen samenvoegt onder één consistent eindpunt, met ingebouwd API-sleutelbeheer, gebruiksquota's en factureringsdashboards. Dit in plaats van te jongleren met meerdere leveranciers-URL's en inloggegevens.
Ontwikkelaars hebben toegang tot Gemini 2.5 Flash-Lite (preview) API brengt KomeetAPIDe nieuwste modellen die in dit artikel worden vermeld, gelden vanaf de publicatiedatum van het artikel. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.