GPT-4o Audio API: Een verenigd /chat/completions eindpuntextensie die Opus-gecodeerde audio- (en tekst-)invoer accepteert en gesynthetiseerde spraak of transcripties retourneert met configureerbare parameters (model=gpt-4o-audio-preview-<date>, speed, temperature) voor batch- en streaming spraakinteracties.
Basisinformatie over GPT-4o Audio
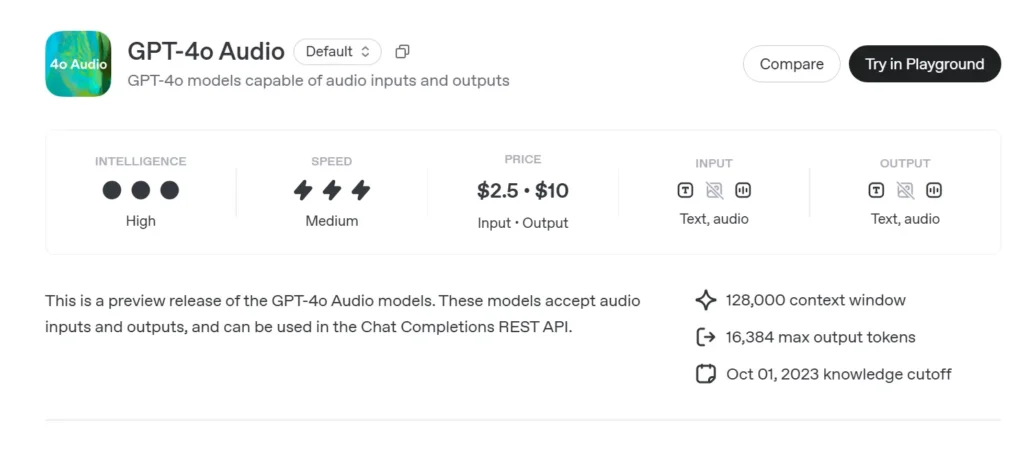
GPT-4o Audiovoorbeeld (gpt-4o-audio-preview-2025-06-03) is de nieuwste van OpenAI spraakgericht groot taalmodel beschikbaar gesteld via de standaard API voor het voltooien van chats in plaats van het Realtime-kanaal met ultralage latentie. Deze variant, gebouwd op dezelfde "omni"-basis als GPT-4o, is gespecialiseerd in spraakinvoer en -uitvoer met hoge getrouwheid voor turn-based conversaties, contentcreatie, toegankelijkheidstools en agent-workflows die geen milliseconde timing vereisen. Het erft alle tekstredeneringssterktes van GPT-4-klasse modellen en voegt er tegelijkertijd aan toe. end-to-end spraak-naar-spraak (S2S) pijpleidingen, deterministisch functie bellenen het nieuwe speed parameter voor het regelen van de spraaksnelheid.
Kernfuncties van GPT-4o Audio
• Geünificeerde spraak-naar-spraakverwerking – Audio wordt direct omgezet in semantisch rijke tokens, beredeneerd en opnieuw gesynthetiseerd zonder externe STT/TTS-diensten, wat resulteert in consistente stemtimbre, prosodie en contextbehoud.
• Verbeterde instructie volgen – Juni-2025 tuning levert +19 pp pass-at-1 bij taken met spraakopdrachten, vergeleken met de GPT-2024o-basislijn van mei 4, waardoor hallucinaties op gebieden als klantenondersteuning en het opstellen van inhoud werden verminderd.
• Stabiele tool-aanroep – De modeluitvoer gestructureerde JSON die voldoet aan het OpenAI-functieaanroepschema, waardoor backend-API's (zoeken, boeken, betalingen) kunnen worden geactiveerd met >95% argumentnauwkeurigheid.
• speed Parameter (0.25–4×) – Ontwikkelaars kunnen de spraakweergave moduleren voor langzaam leren, normale vertelling of snelle “hoorbare skim”-modi, zonder het extern opnieuw synthetiseren van tekst.
• Bewust omgaan met onderbrekingen – Hoewel niet zo latentiegedreven als de Realtime-variant, ondersteunt de preview gedeeltelijke streaming: tokens worden uitgegeven zodra ze zijn berekend, waardoor gebruikers indien nodig eerder kunnen onderbreken.
Technische architectuur van GPT-4o
• Single-Stack Transformator – Zoals alle GPT-4o-derivaten maakt de audiopreview gebruik van een uniforme encoder-decoder waarbij tekst en akoestische tokens door identieke aandachtsblokken gaan, waardoor cross-modale aarding wordt bevorderd.
• Hiërarchische audiotokenisatie – Ruwe 16 kHz PCM → log-mel patches → grove akoestische codes → semantische tokensDeze meertrapscompressie bereikt 40–50× bandbreedtereductie terwijl de nuance behouden blijft en clips van meerdere minuten per contextvenster mogelijk zijn.
• NF4 gekwantiseerde gewichten – De gevolgtrekking wordt gedaan op 4-bits normaal-float precisie, waardoor het GPU-geheugen met de helft wordt verminderd in vergelijking met FP16 en 70+ streaming RTF (real-time factor) op A100-80 GB-knooppunten.
• Streaming Attention & KV-caching – Draaibare inbeddingen met schuifvensters behouden de context gedurende ongeveer 30 seconden spraak, terwijl O(L) geheugengebruik, ideaal voor podcast-editors of hulpmiddelen voor lezen.
Versiebeheer en naamgeving — Preview Track met builds met datumstempel
| Identifier | Kanaal | Doel | Release Date | Stabiliteit |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | API voor het voltooien van chats | Op beurten gebaseerde audio-interacties, agentische taken | Juni 03 2025 | Voorbeschouwing (feedback wordt aangemoedigd) |
Belangrijkste elementen in de naam:
- gpt-4o – Omni-multimodale familie.
- audio – Geoptimaliseerd voor spraaktoepassingen.
- Preview – API-contract kan evolueren; nog niet algemeen beschikbaar.
- 2025-06-03 – Momentopname van training en implementatie voor reproduceerbaarheid.
Hoe GPT-4o Audio API API aanroepen vanuit CometAPI
GPT-4o Audio API API-prijzen in CometAPI:
- Invoertokens: $2 / M tokens
- Uitvoertokens: $8 / M tokens
Vereiste stappen
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
- Haal de url van deze site op: https://api.cometapi.com/
Gebruiksmethoden
- Selecteer de optie "
gpt-4o-audio-preview-2025-06-03"eindpunt om de aanvraag te verzenden en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak. - Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
Voor informatie over Modeltoegang in Comet API, zie API-document.
Voor informatie over de modelprijs in Comet API, zie https://api.cometapi.com/pricing.
API-workflow — Chat-aanvullingen met audio-onderdelen en functie-hooks
- Invoer formaat -
audio/*MIME ofbase64WAV-fragmenten ingebed inmessages[].content. - Uitvoeropties -
•mode: "text"→ pure tekst voor ondertiteling.
•mode: "audio"→ retourneert een streaming Opus- of µ-law-payload met tijdstempels. - Functie-aanroep - Toevoegen
functions:schema; het model zendt uitrole: "function"met JSON-argumenten; de ontwikkelaar voert de toolaanroep uit en stuurt optioneel het resultaat terug. - rate control - Instellen
voice.speed=1.25om het afspelen te versnellen; veilige bereiken 0.25–4.0. - Token-/audiolimieten – 128 k context (~4 min spraak) bij de lancering; 4096 audiotokens / 8192 teksttokens welke het eerst komt.
Voorbeeldcode en API-integratie
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Hoogtepunten:
- model:
"gpt-4o-audio-preview-2025-06-03" - audio sleutel in gebruiker bericht om binaire stroom te verzenden
- snelheid: Bedieningselementen stemsnelheid tussen langzaam (0.5) en snel (2.0)
- temperatuur-: Balansen creativiteit vs consistentie
Technische indicatoren — Latentie, kwaliteit, nauwkeurigheid
| metrisch | Audiovoorbeeld | GPT-4o (alleen tekst) | Delta |
|---|---|---|---|
| Eerste tokenlatentie (1-shot) | 1.2 s avg | 0.35 s | +0.85 s |
| MOS (spraaknatuurlijkheid, 5 pt) | 4.43 | - | - |
| Instructienaleving (spraak) | 92% | 73% | +19 pagina's |
| Nauwkeurigheid van functieaanroep Arg | 95.8% | 87% | +8.8 pagina's |
| Woordfoutpercentage (impliciete STT) | 5.2% | n / a | - |
| GPU-geheugen/stream (A100-80GB) | 7.1 GB | 14 GB (fp16) | −49% |
Benchmarks uitgevoerd via Chat Completions streaming, batchgrootte = 1.
Zie ook GPT-4o Realtime API