GPT-4o Realtime API: Een multimodaal streaming-eindpunt met lage latentie waarmee ontwikkelaars gesynchroniseerde tekst-, audio- en beeldgegevens kunnen verzenden en ontvangen via WebRTC of WebSocket (model=gpt-4o-realtime-preview-<date>, stream=true) voor interactieve real-time toepassingen.
Basisgegevens en functies
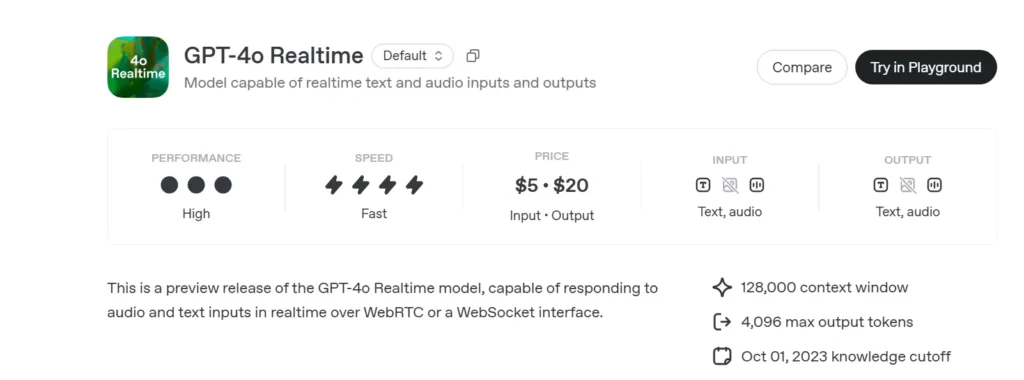
OpenAI's GPT-4o Realtime (model-ID: gpt-4o-realtime-preview-2025-06-03) is het eerste openbaar beschikbare funderingsmodel dat is ontworpen voor end-to-end spraak-naar-spraak (S2S) interactie met sub-seconde latentieDe Realtime-variant, afgeleid van de "omni" GPT-4o-familie, combineert spraakherkenning, natuurlijke taalredenering en neurale tekst-naar-spraak in één netwerk, waardoor ontwikkelaars spraakagenten kunnen bouwen die net zo vloeiend communiceren als mensen. Het model wordt zichtbaar gemaakt via de speciaal ontwikkelde Realtime-API en is nauw geïntegreerd met de nieuwe RealtimeAgent abstractie binnen de Agenten SDK (TypeScript en Python).
Kernfunctieset — End-to-End S2S • Afhandeling van onderbrekingen • Toolaanroepen
• Native spraak-naar-spraak: Audio-invoer wordt verwerkt als continue stromen, intern getokeniseerd, beredeneerd en geretourneerd als gesynthetiseerde spraak. Er zijn geen externe STT/TTS-buffers nodig, waardoor vertragingen van meerdere seconden in de pijplijn worden geëlimineerd.
• Latentie op millisecondeschaal: Architectonische snoei, modeldestillatie en een GPU-geoptimaliseerde serving stack maken het mogelijk ~300–500 ms eerste token latentie in typische cloud-implementaties, benadert dit de normen voor het voeren van gesprekken tussen mensen.
• Robuuste instructies: GPT-4o Realtime is verfijnd op conversatiescripts en functieaanroepsporen en demonstreert een >25% reductie in fouten bij de uitvoering van taken vergeleken met de GPT-2024o-basislijn van mei 4.
• Deterministische gereedschapsaanroeping: Het model produceert gestructureerde JSON die voldoet aan de OpenAI-richtlijnen. functie-aanroepend schema, waardoor deterministische aanroep van back-end API's (boekingssystemen, databases, IoT) mogelijk is. Foutbewuste herhalingen en argumentvalidatie zijn ingebouwd.
• Elegante onderbrekingen: Een realtime stemactiviteitsdetector in combinatie met incrementele decodering stelt de agent in staat om pauzeer de spraak midden in een zin, een onderbreking van de gebruiker verwerken en de reactie naadloos hervatten of opnieuw plannen.
• Configureerbare spraaksnelheid: nieuwe snelheid Met de parameter (0.25–4× realtime) kunnen ontwikkelaars het uitvoertempo aanpassen voor toegankelijkheid of snelle toepassingen.
Technische architectuur — Geünificeerde multimodale transformator
Geünificeerde encoder-decoder: GPT-4o Realtime deelt de omni-architectuur enkelvoudige stapeltransformator Waarin audio, tekst en (toekomstige) visietokens naast elkaar bestaan in één latente ruimte. Laaggewijs adaptieve berekeningen leiden audioframes direct naar latere aandachtsblokken, wat 20-40 ms per passage scheelt.
Hiërarchische audiotokenisatie: Ruwe 16 kHz PCM wordt opgedeeld in log-mel-patches → gekwantiseerd in grofkorrelige akoestische tokens → gecomprimeerd in semantische tokens, waardoor de token per seconde budget zonder de prosodie op te offeren.
Low-Bit Inference Kernels: Uitgerolde gewichten lopen op 4-bits NF4-kwantisering via Triton / TensorRT-LLM-kernels, waardoor de doorvoer ten opzichte van fp16 wordt verdubbeld, terwijl het MOS-kwaliteitsverlies <1 dB blijft.
Streaming Let op: Dankzij de roterende inbedding met schuivend venster en het cachen van sleutel-waarde kan het model de laatste 15 seconden van de audio met O(L)-geheugen opslaan, wat cruciaal is voor dialogen van de duur van een telefoongesprek.
Technische gegevens
- API-versie:
2025-06-03-preview - Transportprotocollen:
- WebRTC: Ultralage latentie (< 80 ms) voor audio-/videostreams aan de clientzijde
- WebSocket: Server-naar-server streaming met een latentie van minder dan 100 ms
- Gegevenscodering:
- Opus codec binnen RTP pakketten voor audio
- H.264 / H.265 frame wrappers voor video
- streaming: Ondersteunt
stream: trueafleveren incrementele gedeeltelijke reacties terwijl tokens worden gegenereerd - Nieuw Stempalet: Introduceert acht nieuwe stemmen—legering, as, ballade, koraal, echo, salie, flikkeringen vers—voor meer expressief, mensachtig interacties ..
Evolutie van GPT-4o Realtime
- mei 2024: GPT-4o Omni debuteert met multimodale ondersteuning voor tekst, audio en beeld.
- 2024 oktober: Realtime-API gaat de private bèta in (
2024-10-01-preview), geoptimaliseerd voor audio met lage latentie. - December 2024: Uitgebreide wereldwijde beschikbaarheid van
gpt-4o-realtime-preview-2024-12-17, Toevoegen snelle caching en nog meer stemmen. - 3 juni 2025: Laatste update (
2025-06-03-preview) rolt verfijnde stempalet en prestatie-optimalisaties.
Benchmarkprestaties
- MMLU: 88.7, waarmee hij de 4 van GPT-86.5 overtrof Enorm multitask-taalbegrip .
- Spraakherkenning: Bereikt toonaangevende woordfoutenpercentages in lawaaierige omgevingen, hoger dan Fluisteren basislijnen.
- Latentietests:
- Eind tot eind (spraak in → tekst uit): 50–80 ms via WebRTC
- Retour-Audio (spraak in → spraak uit): <100 ms .
Technische indicatoren
- Doorvoer:Onderhoud 15 tokens/sec voor tekststromen; 24 kbps Opus voor audio.
- Prijzen:
- Tekst: $5 per 1 miljoen inputtokens; $20 per 1 miljoen outputtokens
- Audio: $100 per 1 M invoertokens; $200 per 1 M uitvoertokens.
- beschikbaarheid: Wereldwijd geïmplementeerd in alle regio's die de Realtime API ondersteunen.
Hoe GPT-4o Realtime API aanroepen vanuit CometAPI
GPT-4o Realtime API-prijzen in CometAPI:
- Invoertokens: $2 / M tokens
- Uitvoertokens: $8 / M tokens
Vereiste stappen
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
- Haal de url van deze site op: https://api.cometapi.com/
Gebruiksmethoden
- Selecteer de optie "
gpt-4o-realtime-preview-2025-06-03"eindpunt om de aanvraag te verzenden en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak. - Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
Voor informatie over Modeltoegang in Comet API, zie API-document.
Voor informatie over de modelprijs in Comet API, zie https://api.cometapi.com/pricing.
Voorbeeldcode en API-integratie
import openai
openai.api_key = "YOUR_API_KEY"
# Establish a Realtime WebRTC connection
connection = openai.Realtime.connect(
model="gpt-4o-realtime-preview-2025-06-03",
version="2025-06-03-preview",
transport="webrtc"
)
# Stream audio frames and receive incremental text
with open("user_audio.raw", "rb") as audio_stream:
for chunk in iter(lambda: audio_stream.read(2048), b""):
result = connection.send_audio(chunk)
print("Assistant:", result)
- Hoofdparameters:
model: “gpt-4o-realtime-preview-2025-06-03”version: “2025-06-03-voorbeschouwing”transport: “webrtc” besteld, minimale latentiestream:truebesteld, incrementele updates
Door te combineren state-of-the-art multimodaal redeneren, een robuust nieuw stempalet, en ultra laag latentie streaming, GPT-4o Realtime (2025-06-03) stelt ontwikkelaars in staat om echt interactieve, spraakzaam AI-toepassingen.
Zie ook o3-Pro API
Veiligheid en naleving
OpenAI levert GPT-4o Realtime met:
• Beveiligingsmaatregelen op systeemniveau: Beleid afgestemd op het weigeren van afgewezen verzoeken (extremisme, illegaal gedrag).
• Realtime-inhoudsfiltering: Classificatoren van minder dan 100 ms screenen zowel de invoer van de gebruiker als de uitvoer van het model voordat ze worden uitgezonden.
• Paden voor menselijke goedkeuring: Wordt geactiveerd bij aanroepen van tools met een hoog risico (betalingen, juridisch advies), waarbij gebruik wordt gemaakt van de nieuwe goedkeuringsprimitieven van de Agents SDK.