

OpenAI publiceerde een voorvertoning van het onderzoek gpt-oss-safeguard, een open-gewicht inferentiemodelfamilie die is ontworpen om ontwikkelaars in staat te stellen eigen veiligheidsbeleid op het moment van inferentie. In plaats van een vaste classificator of een black-box moderatie-engine te leveren, zijn de nieuwe modellen verfijnd om reden van een door de ontwikkelaar verstrekt beleid, een gedachteketen (CoT) genereren die hun redenering verklaart, en gestructureerde classificatieresultaten produceren. Gpt-oss-safeguard, aangekondigd als een preview van het onderzoek, wordt gepresenteerd als een paar redeneermodellen.gpt-oss-safeguard-120b en gpt-oss-safeguard-20b—verfijnd op basis van de gpt-oss-familie en expliciet ontworpen om taken voor veiligheidsclassificatie en beleidshandhaving uit te voeren tijdens inferentie.
Wat is gpt-oss-safeguard?
gpt-oss-safeguard is een paar open-gewicht, tekst-alleen redeneermodellen die na-getraind zijn uit de gpt-oss familie om een beleid interpreteren dat in natuurlijke taal is geschreven en tekst labelen volgens dat beleidHet onderscheidende kenmerk is dat het beleid is verstrekt op het moment van afleiding (beleid-als-invoer), niet ingebed in statische classificatorgewichten. De modellen zijn primair ontworpen voor veiligheidsclassificatietaken, zoals moderatie van meerdere beleidsregels, inhoudsclassificatie over meerdere regelgevingsregimes of controles op naleving van beleid.
Waarom deze zaken
Traditionele moderatiesystemen vertrouwen doorgaans op (a) vaste regelsets die gekoppeld zijn aan classificatoren die getraind zijn op gelabelde voorbeelden, of (b) heuristiek/regexes voor trefwoorddetectie. gpt-oss-safeguard probeert het paradigma te veranderen: in plaats van classificatoren opnieuw te trainen telkens wanneer het beleid verandert, levert u een beleidstekst aan (bijvoorbeeld het beleid voor acceptabel gebruik van uw bedrijf, de servicevoorwaarden van het platform of een richtlijn van een toezichthouder) en het model beredeneert of een bepaald stuk content dat beleid schendt. Dit belooft flexibiliteit (beleidswijzigingen zonder opnieuw te trainen) en interpreteerbaarheid (het model geeft zijn redenering weer).
Dit is de kernfilosofie: ‘Het vervangen van memoriseren door redeneren, en gokken door uitleggen.’
Dit vertegenwoordigt een nieuwe fase in de beveiliging van content, waarbij de overgang plaatsvindt van ‘passief regels leren’ naar ‘actief regels begrijpen’.
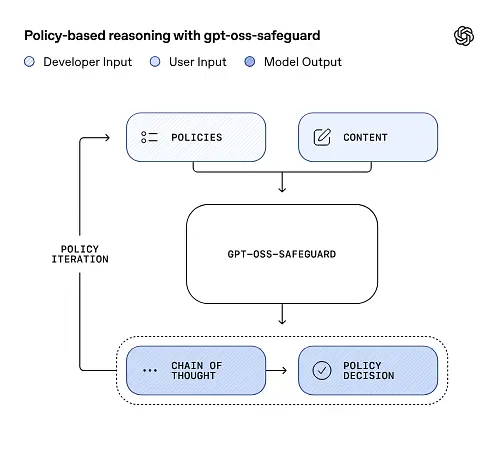
gpt-oss-safeguard kan het door de ontwikkelaars gedefinieerde beveiligingsbeleid rechtstreeks uitlezen en dat beleid volgen om beslissingen te nemen tijdens de inferentie.
Hoe werkt gpt-oss-safeguard?
Beleid-als-input redenering
Op het moment van de inferentie geeft u twee dingen op: de beleidstekst en kandidaat inhoud te labelen. Het model beschouwt het beleid als de primaire instructie en voert vervolgens een stapsgewijze redenering uit om te bepalen of de inhoud is toegestaan, niet is toegestaan of aanvullende moderatiestappen vereist. Bij de inferentie:
- produceert een gestructureerde uitvoer die een conclusie (label, categorie, betrouwbaarheid) bevat en een voor mensen leesbaar redeneerpatroon dat uitlegt waarom die conclusie is getrokken.
- neemt het beleid en de te classificeren inhoud op,
- redeneert intern door de clausules van het beleid met behulp van stappen die lijken op een gedachteketen, en
Bijvoorbeeld:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Het antwoord zal zijn:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Chain-of-Thought (CoT) en gestructureerde outputs
gpt-oss-safeguard kan een volledige CoT-trace genereren als onderdeel van elke inferentie. De CoT is bedoeld om inspecteerbaar te zijn: complianceteams kunnen lezen waarom het model tot een conclusie is gekomen, en engineers kunnen de trace gebruiken om beleidsambiguïteit of modelfalen te diagnosticeren. Het model ondersteunt ook gestructureerde uitgangen—bijvoorbeeld een JSON die een oordeel, overtreden beleidssecties, ernstscore en voorgestelde herstelmaatregelen bevat—waardoor het eenvoudig te integreren is in moderatiepijplijnen.
Instelbare niveaus van ‘redeneerinspanning’
Om de balans te vinden tussen latentie, kosten en grondigheid ondersteunen de modellen configureerbare redeneerinspanningen: laag / gemiddeld / hoogMeer inspanning vergroot de diepgang van de gedachteketen en levert over het algemeen robuustere, maar tragere en duurdere, gevolgtrekkingen op. Dit stelt ontwikkelaars in staat om workloads te sorteren: lage inspanning voor routinematige content en hoge inspanning voor edge cases of content met een hoog risico.
Hoe is de modelstructuur en welke versies bestaan er?
Modelfamilie en afstamming
gpt-oss-safeguard zijn na de training varianten van OpenAI's eerdere gpt-us open modellen. De safeguard-familie omvat momenteel twee uitgebrachte maten:
- gpt-oss-safeguard-120b — een model met 120 miljard parameters, bedoeld voor zeer nauwkeurige redeneertaken, dat nog steeds op een enkele 80 GB GPU wordt uitgevoerd met geoptimaliseerde looptijden.
- gpt-oss-safeguard-20b — een model met 20 miljard parameters, geoptimaliseerd voor goedkopere inferentie en edge- of on-premises omgevingen (kan in sommige configuraties op 16 GB VRAM-apparaten worden uitgevoerd).
Architectuurnotities en runtime-kenmerken (wat u kunt verwachten)
- Actieve parameters per token: De onderliggende gpt-oss-architectuur maakt gebruik van technieken die het aantal per token geactiveerde parameters beperken (een mix van dense en sparse attention/mix-of-experts-stijlontwerp in het bovenliggende gpt-oss).
- In de praktijk past de 120B-klasse op één grote versneller en is de 20B-klasse ontworpen om te werken op 16 GB VRAM-configuraties met geoptimaliseerde looptijden.
Er waren beschermingsmodellen niet getraind met aanvullende biologische of cyberbeveiligingsgegevens, en dat analyses van de ergste misbruikscenario's die zijn uitgevoerd voor de gpt-oss-release, grofweg van toepassing zijn op de safeguard-varianten. De modellen zijn bedoeld voor classificatie in plaats van contentgeneratie voor eindgebruikers.
Wat zijn de doelen van gpt-oss-safeguard?
Doelen
- Beleidsflexibiliteit: laat ontwikkelaars elk beleid in natuurlijke taal definiëren en laat het model dit toepassen zonder aangepaste labelverzameling.
- Uitlegbaarheid: Leg redeneringen bloot, zodat beslissingen gecontroleerd kunnen worden en beleid herhaald kan worden.
- Toegankelijkheid: een open-gewicht alternatief bieden, zodat organisaties lokaal veiligheidsredeneringen kunnen uitvoeren en de interne werking van modellen kunnen inspecteren.
Vergelijking met klassieke classificatoren
Voordelen ten opzichte van traditionele classificatoren
- Geen omscholing voor beleidswijzigingen: Als uw moderatiebeleid verandert, werkt u het beleidsdocument bij in plaats van labels te verzamelen en een classificator opnieuw te trainen.
- Rijkere redenering: CoT-resultaten kunnen subtiele beleidsinteracties onthullen en een verhalende rechtvaardiging bieden die nuttig is voor menselijke beoordelaars.
- Aanpasbaarheid: Één enkel model kan tijdens de inferentie meerdere verschillende beleidsregels tegelijkertijd toepassen.
Nadelen versus traditionele classificatoren
- Prestatielimieten voor sommige taken: Uit de evaluatie van OpenAI blijkt dat Hoogwaardige classificatoren die zijn getraind op tienduizenden gelabelde voorbeelden kunnen gpt-oss-safeguard overtreffen voor gespecialiseerde classificatietaken. Wanneer het doel ruwe classificatienauwkeurigheid is en u gelabelde gegevens hebt, kan een speciale classifier die op die distributie is getraind, beter zijn.
- Latentie en kosten: Redeneren met CoT vergt veel rekenkracht en is langzamer dan met een lichtgewicht classificator. Dit kan pijplijnen die puur op beveiliging zijn gebaseerd, op grote schaal duur maken.
Kortom: gpt-oss-safeguard wordt het beste gebruikt waar beleidsflexibiliteit en controleerbaarheid zijn prioriteiten of wanneer gelabelde gegevens schaars zijn - en als een aanvullende component in hybride pijplijnen, niet noodzakelijkerwijs als een directe vervanging voor een op schaal geoptimaliseerde classificator.
Hoe presteerde gpt-oss-safeguard in de evaluaties van OpenAI?
OpenAI publiceerde de basisresultaten in een technisch rapport van 10 pagina's met een samenvatting van interne en externe evaluaties. Belangrijkste conclusies (geselecteerde, dragende meetgegevens):
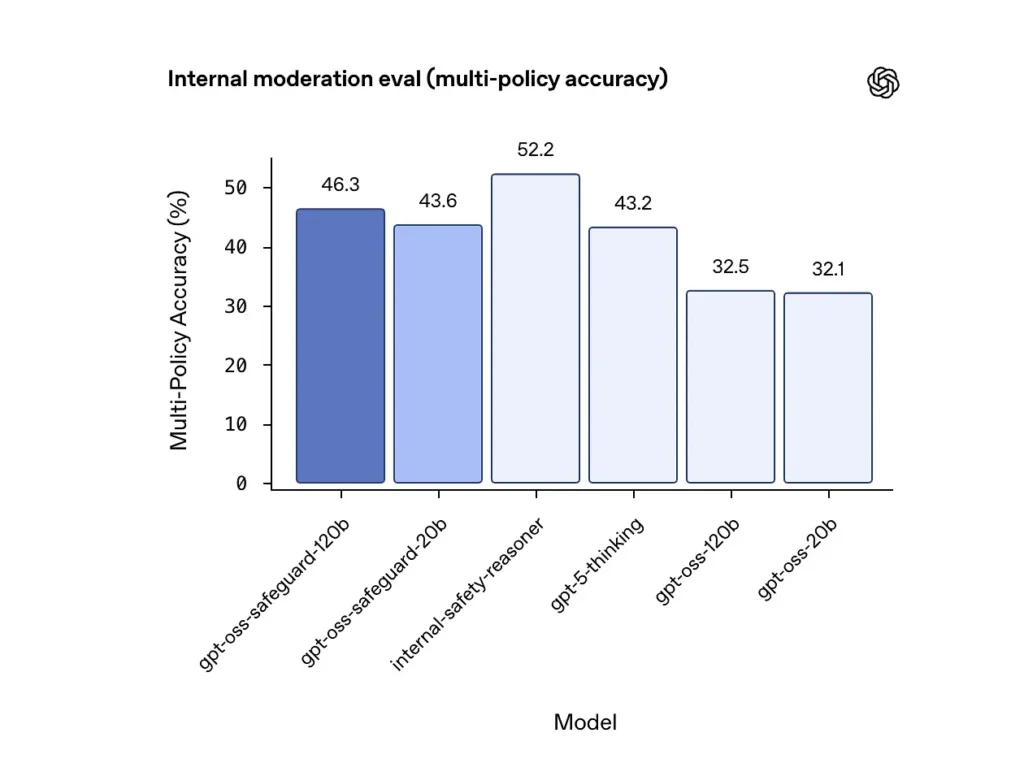
Nauwkeurigheid van meerdere beleidsregels (interne evaluatie)
OpenAI heeft de nauwkeurigheid van meerdere beleidsregels geëvalueerd door het model meervoudig beleidsmaatregelen tegelijkertijd en telt een voorspelling alleen als correct als deze overeenkomt met de gouden labels op de hele allen beleid. Resultaten:
- gpt-oss-safeguard-120b: 46.3% nauwkeurigheid van meerdere beleidsregels
- gpt-oss-safeguard-20b: 43.6%
- Ter vergelijking: gpt-5-denken: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
Het interne "veiligheids-redeneer"-ensemble van OpenAI scoorde 52.2% in dezelfde test. Deze cijfers laten zien dat de safeguard-modellen hun gpt-oss-basismodellen aanzienlijk overtreffen in de multi-policy-taak, en ze overtroffen zelfs de grotere gpt-5-denkbasislijn in de interne multi-policy-metriek.
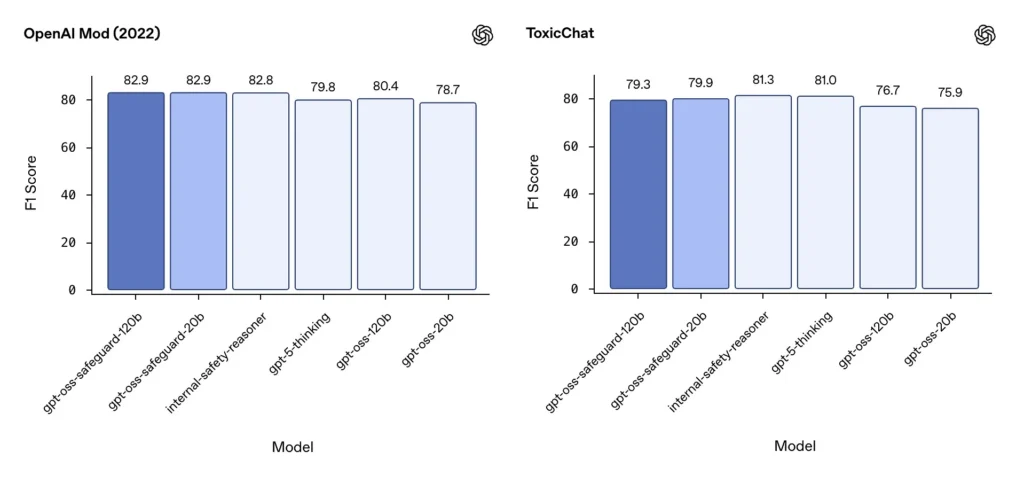
Moderatie F1 (externe benchmarks)
Op de moderatiedataset van OpenAI uit 2022 en de openbare ToxicChat-benchmark behaalden de gpt-oss-safeguard-modellen solide F1-scores:
- OpenAI-mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Deze scores plaatsen gpt-oss-safeguard op een niveau dat dicht bij of iets achterligt bij gespecialiseerde interne OpenAI-systemen op sommige benchmarks, en over het algemeen boven de niet-afgestemde gpt-oss-tegenhangers.
Geobserveerde beperkingen
OpenAI signaleert twee praktische beperkingen:
- Classificatoren die zijn getraind op grote, taakspecifieke gelabelde datasets kunnen nog steeds beter presteren dan beschermingsmodellen wanneer classificatienauwkeurigheid het enige doel is.
- Reken- en latentiekosten: CoT-redenering vergroot de inferentietijd en het rekenverbruik, wat het opschalen naar verkeer op platformniveau bemoeilijkt, tenzij gecombineerd met triageclassificaties en asynchrone pijplijnen.
Meertalige pariteit
gpt-oss-safeguard presteert gelijkwaardig aan de onderliggende gpt-oss-modellen in veel talen in MMMLU-stijltests, wat aangeeft dat de nauwkeurig afgestemde safeguardvarianten een breed redeneervermogen behouden.
Hoe kunnen teams toegang krijgen tot gpt-oss-safeguard en deze implementeren?
OpenAI biedt de gewichten onder Apache 2.0 en koppelt de modellen aan downloads (Hugging Face). Omdat gpt-oss-safeguard een model met open gewichten is, is lokale en zelfbeheerde implementatie mogelijk (aanbevolen voor privacy en maatwerk).
- Modelgewichten downloaden (van OpenAI / Hugging Face) en host ze op uw eigen servers of cloud-VM's. Apache 2.0 staat aanpassing en commercieel gebruik toe.
- Runtime: Gebruik standaard inferentie-runtimes die grote transformermodellen ondersteunen (ONNX Runtime, Triton of geoptimaliseerde runtimes van leveranciers). Community-runtimes zoals Ollama en LM Studio voegen al ondersteuning toe voor gpt-oss-families.
- Hardware: 120B vereist doorgaans GPU's met veel geheugen (bijv. 80GB A100/H100 of multi-GPU sharding), terwijl 20B goedkoper kan worden gebruikt en opties heeft die zijn geoptimaliseerd voor 16GB VRAM-configuraties. Plan de capaciteit voor piekdoorvoer en de kosten voor de evaluatie van meerdere beleidsregels.
Beheerde en externe runtimes
Als het niet praktisch is om uw eigen hardware te gebruiken, KomeetAPI voegt snel ondersteuning toe voor gpt-oss-modellen. Deze platforms bieden mogelijk eenvoudigere schaalbaarheid, maar brengen ook de risico's van blootstelling van gegevens van derden met zich mee. Evalueer privacy, SLA's en toegangscontrole voordat u voor beheerde runtimes kiest.
Effectieve moderatiestrategieën met gpt-oss-safeguard
1) Gebruik een hybride pijplijn (triage → redeneren → beoordelen)
- Triagelaag: Kleine, snelle classificatoren (of regels) filteren triviale gevallen eruit. Dit vermindert de belasting van het dure beveiligingsmodel.
- Beveiligingslaag: Voer gpt-oss-safeguard uit voor dubbelzinnige, risicovolle of controles op meerdere beleidsregels waarbij de nuances van het beleid van belang zijn.
- Menselijke rechtspraak: escaleer randzaken en bezwaren, waarbij CoT wordt opgeslagen als bewijs voor transparantie. Dit hybride ontwerp combineert doorvoer en precisie.
2) Beleidsengineering (geen prompt engineering)
- Behandel beleidsregels als software-artefacten: maak er versies van, test ze tegen datasets en houd ze expliciet en hiërarchisch.
- Schrijf beleid met voorbeelden en tegenvoorbeelden. Voeg indien mogelijk verduidelijkende instructies toe (bijvoorbeeld: "Als de intentie van de gebruiker duidelijk verkennend en historisch is, label dan met X; als de intentie operationeel en realtime is, label dan met Y").
3) Configureer de redeneerinspanning dynamisch
- Gebruik weinig inspanning voor bulkverwerking en hoge inspanning voor gemarkeerde content, oproepen of verticals met een grote impact (juridisch, medisch, financieel).
- Stem drempelwaarden af op basis van feedback van menselijke beoordelingen om de juiste balans tussen kosten en kwaliteit te vinden.
4) Valideer CoT en let op hallucinaties in het redeneren
De CoT is waardevol, maar kan hallucineren: het spoor is een door een model gegenereerde redenering, geen grondwaarheid. Controleer de CoT-uitvoer routinematig; meet detectoren op gehallucineerde citaten of niet-overeenkomende redeneringen. OpenAI documenteert gehallucineerde gedachteketens als een waargenomen uitdaging en suggereert strategieën om deze te beperken.
5) Bouw datasets op basis van systeembewerking
Registreer modelbeslissingen en menselijke correcties om gelabelde datasets te creëren die triageclassificaties kunnen verbeteren of beleidsherzieningen kunnen ondersteunen. Na verloop van tijd vermindert een kleine, hoogwaardige gelabelde dataset plus een efficiënte classificator vaak de afhankelijkheid van volledige CoT-inferentie voor routinematige content.
6) Controleer de rekenkracht en kosten; gebruik asynchrone stromen
Overweeg voor consumentgerichte applicaties met een lage latentie asynchrone veiligheidscontroles met een conservatieve gebruikerservaring op de korte termijn (bijvoorbeeld tijdelijk inhoud verbergen in afwachting van beoordeling) in plaats van synchroon uitgevoerde, intensieve CoT. OpenAI merkt op dat Safety Reasoner intern asynchrone stromen gebruikt om de latentie voor productieservices te beheren.
7) Houd rekening met privacy en de locatie van de implementatie
Omdat gewichten open zijn, kunt u inferentie volledig on-premises uitvoeren om te voldoen aan strikte datagovernance of om de blootstelling aan API's van derden te beperken. Dit is waardevol voor gereguleerde sectoren.
Conclusie:
gpt-oss-safeguard is een praktische, transparante en flexibele tool voor beleidsgestuurde veiligheidsredenering. Het schijnt wanneer je het nodig hebt controleerbare beslissingen gekoppeld aan expliciet beleid, wanneer uw beleid regelmatig verandert, of wanneer u veiligheidscontroles op locatie wilt houden. Het is niet Een wondermiddel dat gespecialiseerde classificatoren met een hoog volume automatisch zal vervangen. Uit OpenAI's eigen evaluaties blijkt dat specifieke classificatoren die getraind zijn op grote gelabelde corpora, deze modellen qua pure nauwkeurigheid voor specifieke taken kunnen overtreffen. Beschouw gpt-oss-safeguard in plaats daarvan als een strategisch onderdeel: de engine voor verklaarbaar redeneren die de kern vormt van een gelaagde veiligheidsarchitectuur (snelle triage → verklaarbaar redeneren → menselijk toezicht).
Beginnen
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
De nieuwste integratie gpt-oss-safeguard zal binnenkort op CometAPI verschijnen, dus blijf op de hoogte! Terwijl we de gpt-oss-safeguard Modelupload afronden, kunnen ontwikkelaars toegang krijgen GPT-OSS-20B API en GPT-OSS-120B API via CometAPI, de nieuwste modelversie wordt altijd bijgewerkt met de officiële website. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!