
grok-code-fast-1 is xAI's op snelheid gericht, kostenefficiënt agentisch coderingsmodel Ontworpen om IDE-integraties en geautomatiseerde codeeragenten mogelijk te maken. Het benadrukt lage latency, agentisch gedrag (tool-aanroepen, stapsgewijze redeneringssporen) en een compact kostenprofiel voor dagelijkse ontwikkelaarsworkflows.
Belangrijkste kenmerken (in één oogopslag)
- Hoge doorvoer / lage latentie: gericht op zeer snelle tokenuitvoer en snelle voltooiingen voor IDE-gebruik.
- Agentische functieaanroep en tooling: ondersteunt functieaanroepen en externe toolorkestratie (tests uitvoeren, linters, bestanden ophalen) om multi-step coding-agents mogelijk te maken.
- Groot contextvenster: ontworpen om grote codebases en contexten met meerdere bestanden te verwerken (providers vermelden 256k contextvensters in marktplaatsadapters).
- Zichtbare redenering / sporen: Reacties kunnen stapsgewijze redeneersporen bevatten die bedoeld zijn om beslissingen van agenten controleerbaar en debugbaar te maken.
Technische details
Architectuur & training: Volgens xAI is grok-code-fast-1 vanaf nul opgebouwd met een nieuwe architectuur en een pre-trainingscorpus rijk aan programmeerinhoud; het model werd vervolgens na de training gecureerd op basis van hoogwaardige, real-world pull-request/code-datasets. Deze engineering-pipeline is erop gericht om het model praktische interne agentworkflows (IDE + toolgebruik).
Serveren & context: grok-code-fast-1 Typische gebruikspatronen gaan uit van streaming-uitvoer, functieaanroepen en rijke contextinjectie (bestanduploads/-verzamelingen). Verschillende cloudmarktplaatsen en platformadapters bieden al ondersteuning voor grote contexten (256k contexten in sommige adapters).
Gebruiksvriendelijke functies: Zichtbaar redeneringssporen (het model toont de planning/het gebruik van de tools), snelle technische begeleiding en voorbeeldintegraties, en integraties met partners die het product al vroeg op de markt brengen (bijvoorbeeld GitHub Copilot en Cursor).
Benchmarkprestaties (waarop het scoort)
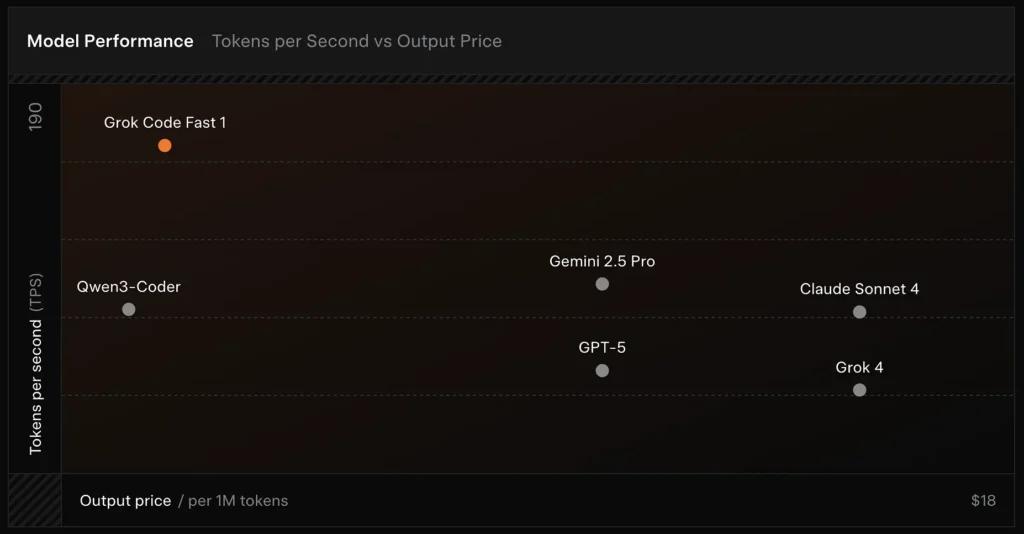
SWE-Bench-geverifieerd: xAI meldt een 70.8% score op hun interne harnas ten opzichte van de SWE-Bench-Verified subset – een benchmark die vaak wordt gebruikt voor het vergelijken van software-engineeringmodellen. Een recente praktische evaluatie rapporteerde een gemiddelde menselijke beoordeling ≈ 7.6 op een gemengde coderingssuite — concurrerend met enkele hoogwaardige modellen (bijv. Gemini 2.5 Pro), maar achterblijvend bij grotere multimodale/"beste redeneer"-modellen zoals Claude Opus 4 en xAI's eigen Grok 4 bij redeneertaken met een hoge moeilijkheidsgraad. Benchmarks laten ook variantie per taak zien: uitstekend voor veelvoorkomende bugfixes en bondige codegeneratie, zwakker voor sommige niche- of bibliotheekspecifieke problemen (Tailwind CSS-voorbeeld).
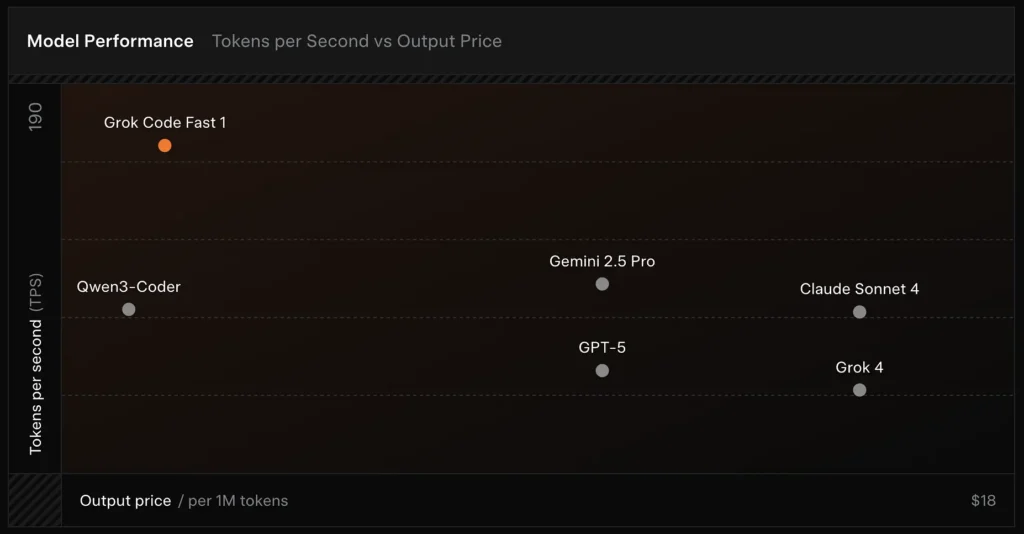
Vergelijking :
- vs Grok 4: Grok-code-fast-1 ruilt een aantal absolute correctheden en diepere redeneringen voor veel lagere kosten en snellere doorvoer; Grok 4 blijft de optie met de hoogste capaciteiten.
- vs Claude Opus / GPT-klasse: Deze modellen worden vaak gebruikt bij complexe, creatieve of moeilijk te begrijpen taken; Grok-code-fast-1 presteert goed bij routinematige ontwikkelaarstaken met een hoog volume, waarbij latentie en kosten van belang zijn.
Beperkingen en risico's
Tot nu toe waargenomen praktische beperkingen:
- Domeinhiaten: prestatiedips bij nichebibliotheken of ongewoon geformuleerde problemen (voorbeelden hiervan zijn Tailwind CSS-randgevallen).
- Redenering-tokenkosten afweging: Omdat het model interne redeneringstokens kan uitzenden, kan zeer agentisch/verbose redeneren de lengte van de inferentie-uitvoer (en de kosten) vergroten.
- Nauwkeurigheid / randgevallen: hoewel Grok-code-fast-1 sterk is in routinematige taken, kan hallucineren of onjuiste code produceren voor nieuwe algoritmen of tegenstrijdige probleemstellingen; het kan slechter presteren dan de beste op redeneren gerichte modellen bij veeleisende algoritmische benchmarks.
Typisch use cases
- IDE-assistentie en rapid prototyping: snelle voltooiingen, incrementeel schrijven van code en interactief debuggen.
- Geautomatiseerde agents/code-workflows: agents die tests orkestreren, opdrachten uitvoeren en bestanden bewerken (bijvoorbeeld CI-helpers, bot-reviewers).
- Dagelijkse technische taken: het genereren van codeskeletten, refactoringen, suggesties voor het oplossen van bugs en multi-file project-scaffolding waarbij een lage latentie de workflow voor ontwikkelaars aanzienlijk verbetert.
Hoe je grok-code-fast-1 API aanroept vanuit CometAPI
grok-code-fast-1 API-prijzen in CometAPI, 20% korting op de officiële prijs:
- Invoertokens: $0.16/M tokens
- Uitvoertokens: $2.0/M tokens
Vereiste stappen
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
Gebruik methode
- Selecteer de optie "
grok-code-fast-1"eindpunt om de API-aanvraag te versturen en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak. - Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
CometAPI biedt een volledig compatibele REST API voor een naadloze migratie. Belangrijke details voor API-document:
- Basis-URL: https://api.cometapi.com/v1/chat/completions
- Modelnamen: "
grok-code-fast-1" - authenticatie: Dragertoken via
Authorization: Bearer YOUR_CometAPI_API_KEYhoofd - Content-Type:
application/json.
API-integratie en voorbeelden
Python-fragment voor een Chatvoltooiing oproep via CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Zie ook Grok 4