

GLM-5 is het nieuwe open-weights, agentgerichte foundationmodel van Zhipu AI, gebouwd voor langetermijn-codering en meerstaps‑agents. Het is beschikbaar via diverse gehoste API’s (waaronder CometAPI en provider‑endpoints) en als onderzoeksrelease met code en gewichten; u kunt het integreren via standaard OpenAI‑compatibele REST‑aanroepen, streaming en SDK’s.
Wat is GLM-5 van Z.ai?
GLM-5 is Z.ai’s vijfde‑generatie vlaggenschip‑foundationmodel, ontworpen voor agentic engineering: langetermijnplanning, meerstaps toolgebruik en grootschalig code-/systeemontwerp. Publiek uitgebracht in februari 2026, is GLM-5 een Mixture‑of‑Experts (MoE) model met ~744 miljard totale parameters en een actief parameterset in de 40B‑range per forward‑pass; de architectuur- en trainingskeuzes prioriteren lang‑contextcoherentie, tool‑calling en kostenefficiënte inferentie voor productie‑workloads. Deze ontwerpkeuzes stellen GLM-5 in staat om uitgebreide agentische workflows uit te voeren (bijvoorbeeld: browsen → plannen → code schrijven/testen → itereren) met behoud van context over zeer lange input.
Belangrijkste technische hoogtepunten:
- MoE‑architectuur op ~744B totaal / ~40B actieve parameters; opgeschaalde pretraining (~28.5T tokens gerapporteerd) om de kloof met frontier gesloten modellen te verkleinen.
- Ondersteuning voor lange context en optimalisaties (deep sparse attention, DSA) voor lagere uitrolkosten ten opzichte van naïeve dichte schaling.
- Ingebouwde agentische functies: tool-/functieaanroepen, ondersteuning voor stateful sessies en geïntegreerde outputs (kan
.docx-,.xlsx-,.pdf‑artefacten produceren als onderdeel van agent‑workflows in vendor‑UI’s). - Open‑weights beschikbaarheid (gewichten gepubliceerd op modelhubs) en gehoste toegangsopties (vendor‑API’s, inferentie‑microservices).
Wat zijn de belangrijkste voordelen van GLM-5?
Agentische planning en langetermijngeheugen
De architectuur en afstelling van GLM-5 geven prioriteit aan consistente meerstapsredenering en geheugen over workflows — een voordeel voor:
- autonome agents (CI‑pijplijnen, taakorkestrators),
- grootschalige codegeneratie of refactorings over meerdere bestanden, en
- documentintelligentie die grote histories moet behouden.
Grote contextvensters
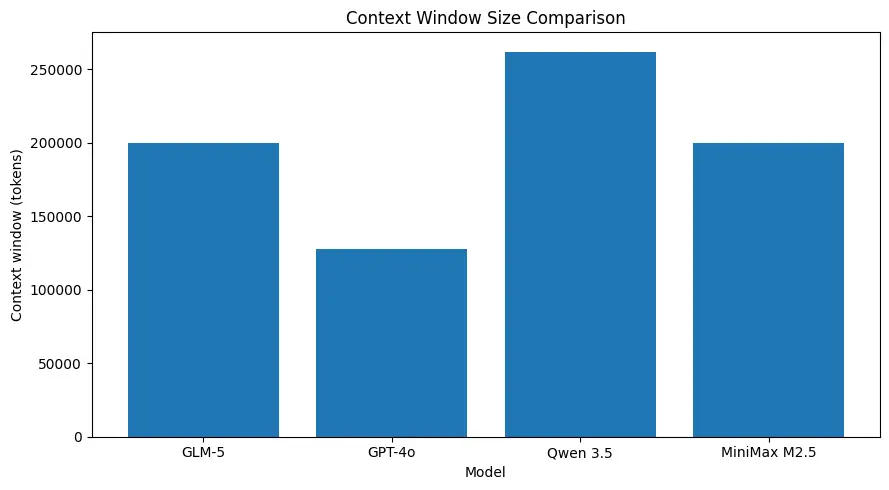
GLM-5 ondersteunt zeer grote contextgroottes (in de orde van ~200k tokens in gepubliceerde modelspecificaties), waardoor u meer van een sessie in één verzoek kunt behouden en de behoefte aan agressief chunken of externe geheugenoplossingen voor veel use‑cases vermindert. (Zie de vergelijkingsgrafiek hieronder.)
Sterke codeerprestaties voor systeemniveau‑taken
GLM-5 rapporteert toonaangevende open‑sourceprestaties op software‑engineering‑benchmarks (SWE‑bench en toegepaste code + agent suites). Op SWE‑bench‑Verified rapporteert het ~77.8%; op codeer-/terminalstijl agenttests (Terminal‑Bench 2.0) clusteren scores in de midden‑50 — bewijs van praktische codeerbekwaamheid die frontier‑proprietary modellen benadert. Deze metrics betekenen dat GLM-5 geschikt is voor taken zoals codegeneratie, geautomatiseerde refactoring, redeneren over meerdere bestanden en CI/CD‑assistant‑scenario’s.
Kosten-/efficiëntie‑afwegingen
Omdat GLM-5 MoE en ‘sparse’‑attention‑innovaties gebruikt, beoogt het de inferentiekosten per eenheid capaciteit te verlagen ten opzichte van brute‑force dichte schaling. CometAPI biedt concurrerende prijsniveaus die GLM-5 aantrekkelijk maken voor agentische workloads met hoge throughput.
Hoe gebruik ik de GLM-5 API via CometAPI?
Kort antwoord: behandel CometAPI als een OpenAI‑compatibele gateway — stel uw basis‑URL en API‑sleutel in, kies glm-5 als het model en roep vervolgens het chat/completions‑endpoint aan. CometAPI biedt een OpenAI‑achtige REST‑interface (endpoints zoals /v1/chat/completions) plus SDK’s en voorbeeldprojecten die migreren triviaal maken.
Hieronder staat een praktische, productiegerichte cookbook: authenticatie, basis chat‑aanroep, streaming, functie/tool‑aanroepen en kosten-/responsafhandeling.
De basisstappen om GLM-5 via CometAPI te benaderen zijn:
- Meld u aan bij CometAPI en verkrijg een API‑sleutel.
- Zoek de exacte model‑ID voor GLM-5 in de catalogus van CometAPI (
"glm-5"afhankelijk van de listing). - Verstuur een geauthenticeerde POST‑aanvraag naar het CometAPI chat/completions‑endpoint (OpenAI‑stijl).
Basisdetails (CometAPI‑patronen): het platform ondersteunt OpenAI‑achtige paden zoals https://api.cometapi.com/v1/chat/completions, Bearer‑authenticatie, de parameter model, system/user‑berichten, streaming en zowel curl/python‑voorbeelden in de documentatie.
Voorbeeld: snelle Python (requests) chat completion met GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Voorbeeld: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Streaming‑responses (praktisch patroon)
CometAPI ondersteunt OpenAI‑stijl streaming (SSE / chunked). De eenvoudigste aanpak in Python is om "stream": true te vragen en over de responsdata te itereren zodra die binnenkomt. Dit is belangrijk wanneer u lage‑latentie, gedeeltelijke output nodig hebt (bouw real‑time dev‑assistants, streaming‑UI’s).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Referentie: OpenAI‑stijl streaming en CometAPI‑compatibiliteitsdocumentatie.
Functie-/toolaanroepen (hoe een externe tool aan te roepen)
GLM-5 ondersteunt functie‑ of tool‑calling‑patronen die compatibel zijn met OpenAI/aggregator‑conventies (de gateway geeft gestructureerde function calls door in de modelrespons). Voorbeeld: vraag GLM-5 om een lokale “run_tests”‑tool aan te roepen; het model retourneert een gestructureerde instructie die u kunt parsen en uitvoeren.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Wanneer het model een function_call‑payload retourneert, voert u de tool server‑side uit, voert u vervolgens het toolresultaat terug als een bericht met de rol "tool" en hervat u het gesprek. Dit patroon maakt veilige tool‑aanroepen en stateful agent‑flows mogelijk. Zie de documentatie en voorbeelden van CometAPI voor concrete SDK‑helpers.
Praktische parameters & tuning
function_call: gebruik om gestructureerde tool‑aanroepen en veiligere uitvoeringsflows in te schakelen.
temperature: 0–0.3 voor deterministische systeemniveau‑outputs (code, infra), hoger voor ideatie.
max_tokens: stel in op de verwachte uitvoerlengte; GLM-5 ondersteunt zeer lange outputs wanneer gehost (vendorlimieten variëren).
top_p / nucleus sampling: nuttig om onwaarschijnlijke staarten af te toppen.
stream: true voor interactieve UI’s.
GLM-5 vergeleken met Anthropic's Claude Opus en andere frontier‑modellen
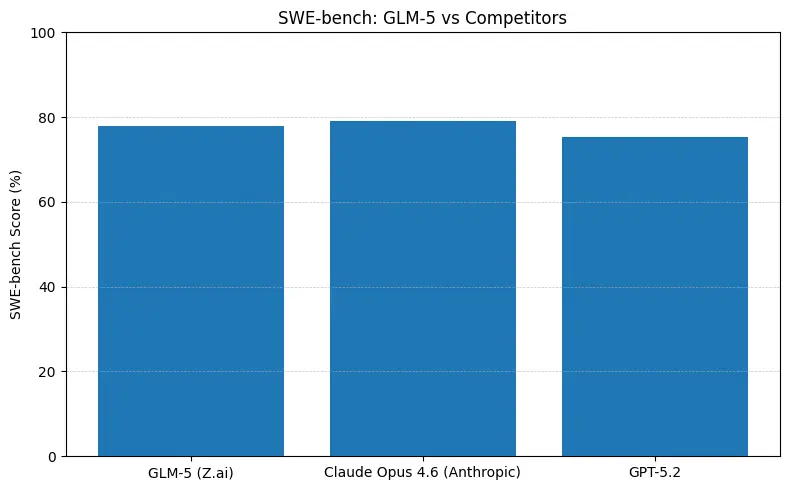
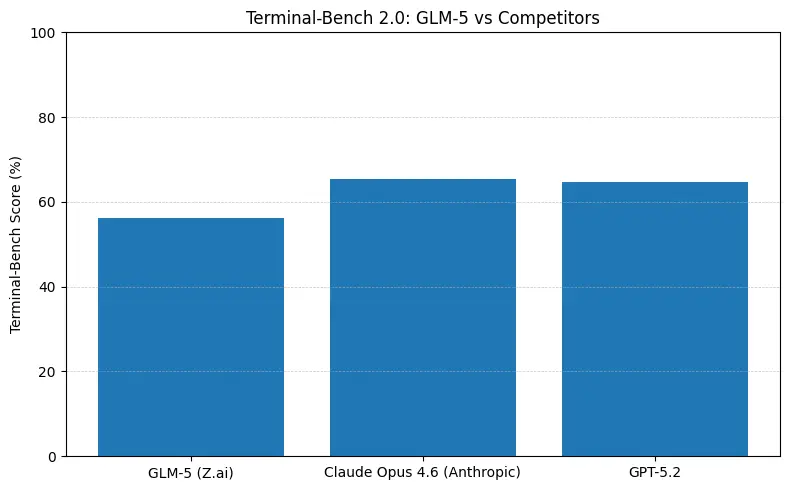
Kort antwoord: GLM-5 verkleint de kloof met gesloten frontier‑modellen in agentische en codeerbenchmarks, terwijl het open‑weights‑deployment biedt en vaak een betere kostprijs per token wanneer gehost door aggregators. De nuance: op sommige absolute codeerbenchmarks (SWE‑bench, Terminal‑Bench‑varianten) loopt Anthropic’s Claude Opus (4.5/4.6) nog enkele punten voor op veel gepubliceerde ranglijsten — maar GLM-5 is zeer competitief en overtreft veel andere open modellen.
Wat de cijfers in de praktijk betekenen
- SWE-bench (~code correctness / engineering): Claude Opus toont een marginale voorsprong (≈79% vs GLM-5 ≈77.8%) op gepubliceerde ranglijsten; voor veel echte taken vertaalt die kloof zich in minder handmatige edits, maar niet per se in een andere architectuurkeuze voor prototyping of opgeschaalde agentische workflows.
- Terminal-Bench (command-line agentic tasks): Opus 4.6 leidt (≈65.4% vs GLM-5 ≈56.2%) — als u robuuste terminalautomatisering en de hoogste betrouwbaarheid op out‑of‑distribution shell‑operaties nodig hebt, is Opus vaak net iets beter.
- Agentic en long-horizon: GLM-5 presteert zeer goed op langetermijn‑businesssimulaties (Vending‑Bench 2 balance $4,432 gerapporteerd) en toont sterke planningscoherentie voor meerstaps‑workflows. Als uw product een langlopende agent is (financiën, operations), is GLM-5 sterk.
Hoe ontwerp ik prompts en systemen om betrouwbare GLM-5‑uitvoer te krijgen?
Systeemberichten & expliciete constraints
Geef GLM-5 een strikte rol en constraints, vooral voor code‑ of tool‑calling‑taken. Voorbeeld:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Vraag om tests en korte redeneerstappen voor elke niet‑triviale wijziging.
Splits complexe taken op
In plaats van “schrijf het volledige product”, vraag om:
- ontwerpoutline,
- interfacesignatures,
- implementatie en tests,
- eindintegratiescript.
Deze stapsgewijze decompositie vermindert hallucinaties en geeft deterministische checkpoints die u kunt valideren.
Gebruik een lage temperatuur voor deterministische code
Wanneer u om code vraagt, zet temperature op 0–0.2 en max_tokens op een veilige bovengrens. Voor creatief schrijven of brainstormen verhoogt u de temperatuur.
Best practices bij het integreren van GLM-5 (via CometAPI of directe hosts)
Prompt engineering & systeemprompts
- Gebruik expliciete system‑instructies die agentrollen, beleid voor tooltoegang en veiligheidsconstraints definiëren. Voorbeeld: “U bent een systeemarchitect: stel alleen wijzigingen voor wanneer unittests lokaal slagen; som exacte CLI‑commando’s op om uit te voeren.”
- Voor codeertaken, bied repositorycontext (bestandslijsten, sleutelcodefragmenten) en voeg unit‑testuitvoer toe indien beschikbaar. GLM-5’s lang‑contextafhandeling helpt — maar plaats altijd essentiële context eerst (rol, taak) en dan ondersteunende artefacten.
Sessie- en statusbeheer
- Gebruik sessie‑ID’s voor lange agentgesprekken en behoud een compacte “memory” van eerdere stappen (samenvattingen) om contextbloat te voorkomen. CometAPI en vergelijkbare gateways bieden sessie-/state‑helpers — maar applicatieniveau state‑compactie is essentieel voor langlopende agents.
Tooling & functieaanroepen (veiligheid + betrouwbaarheid)
- Stel een smalle, auditbare set tools bloot. Sta geen willekeurige shellexecutie toe zonder menselijke supervisie. Gebruik gestructureerde functiedefinities en valideer hun argumenten server‑side.
- Log altijd tool‑aanroepen en modelresponsen voor traceerbaarheid en post‑mortem debugging.
Kostenbeheersing & batching
- Voor agents met hoog volume: routeer achtergrondverwerking naar goedkopere modelvarianten wanneer kwaliteitscompromissen acceptabel zijn (CometAPI laat u van model wisselen op naam). Batch vergelijkbare verzoeken en verlaag
max_tokenswaar mogelijk. Monitor input‑ versus outputtokenratio — outputtokens zijn vaak duurder.
Latentie- & throughput‑engineering
- Gebruik streaming voor interactieve sessies. Voor achtergrond‑agentjobs, geef de voorkeur aan asynchrone runtimes, workerqueues en rate‑limiters. Als u zelf host (open weights), stem uw accelerator‑topologie af op de MoE‑architectuur — FPGA / Ascend / gespecialiseerde siliciumopties kunnen kostenvoordelen opleveren.
Slotopmerkingen
GLM-5 vertegenwoordigt een praktische, open‑weights stap richting agentische engineering: grote contextvensters, planningscapaciteiten en sterke codeerprestaties maken het aantrekkelijk voor ontwikkelaarstools, agent‑orkestratie en automatisering op systeemniveau. Gebruik CometAPI voor snelle integratie of een cloud model garden voor beheerde hosting; valideer altijd op uw workload en instrumenteer intensief voor kosten‑ en hallucinatiecontrole.
Ontwikkelaars kunnen GLM-5 nu benaderen via CometAPI. Om te beginnen, verken de mogelijkheden van het model in de Playground en raadpleeg de API guide voor gedetailleerde instructies. Zorg er vóór de toegang voor dat u bij CometAPI bent ingelogd en de API‑sleutel hebt verkregen. CometAPI biedt een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te beginnen?→ Meld u vandaag aan voor M2.5!
Als u meer tips, gidsen en nieuws over AI wilt weten, volg ons op VK, X en Discord!