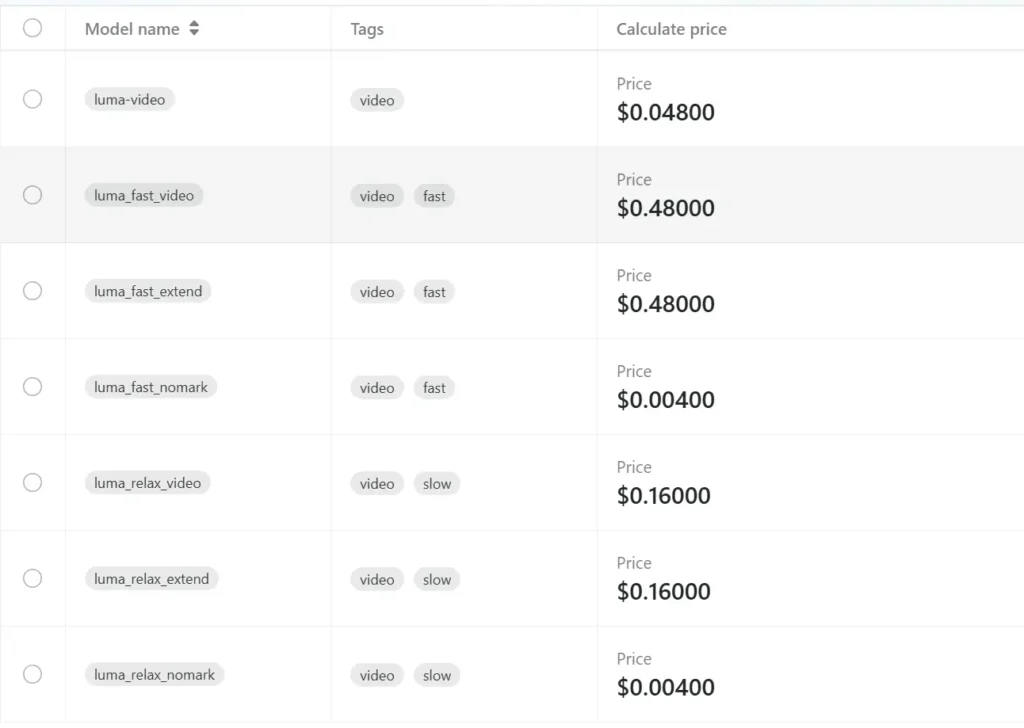
Luma AI is uitgegroeid tot een van de meest besproken tools voor het creëren van content voor consumenten en prosumers: een app en cloudservice die smartphonefoto's en -video's omzet in fotorealistische 3D NeRF's en – via de Dream Machine/Ray2-modellen – afbeeldingen en korte video's genereert op basis van tekst- of beeldprompts. Maar snelheid is een van de eerste praktische vragen die makers zich stellen: hoe lang duurt een opname, render of videogeneratie eigenlijk?
Hoelang duurt het voordat Luma AI een Dream Machine (tekst → video) clip genereert?
Officiële basislijntijden
De productpagina's en leerhub van Luma bieden snelle basistimings voor hun pipelines voor het genereren van afbeeldingen en korte video's: batches van afbeeldingen worden gemeten in tientallen seconden en korte video's in seconden tot enkele minuten onder normale omstandigheden voor betalende gebruikers en interne benchmarks. Deze officiële statistieken weerspiegelen geoptimaliseerde modelruns op Luma's infrastructuur (Ray2 / Dream Machine stack) en zijn de beste cijfers voor kleine, korte clips.
De werkelijke bereiken die u mag verwachten
Randgevallen / gratis tier of piekbelasting: gratis gebruikers of tijden van grote vraag hebben wachttijden opgeleverd uur of taken die "in de wachtrij staan" totdat er capaciteit vrijkomt; community-discussies beschrijven wachttijden van meerdere uren tijdens piekperiodes of storingen. Als lage latentie cruciaal is, houd dan rekening met deze variabiliteit en overweeg betaalde/prioriteitsopties.
Kleine sociale clips (5–15 sec): in veel gevallen kan de generatiestap alleen al volstaan minder dan een minuut tot een paar minuten voor betalende gebruikers tijdens normale belasting, maar de totale kloksnelheid kan langer zijn als u wachtrijen, voorverwerking en streaming-/exportstappen meerekent.
Clips met meer details of langere clips (20–60 sec.): deze kunnen nemen enkele minuten tot tientallen minuten, vooral als u om een hogere resolutie, complexe camerabewegingen of iteratieve verfijning vraagt. Beoordelingen van derden en gebruikersaccounts rapporteren typische tijden in de 5–30 minuten band voor complexere korte video's.
Hoelang duurt het voordat Luma AI een 3D-opname maakt (met NeRF/Genie/telefoon)?
Typische 3D-capture-workflows en hun tijdsprofielen
De 3D-capturetools van Luma (de mobiele capture-app + Genie-achtige functies) transformeren een set foto's of een opgenomen video naar een NeRF-achtig 3D-model of textuurmesh. In tegenstelling tot korte Dream Machine-clips is 3D-reconstructie zwaarder: het moet veel frames verwerken, cameraposities inschatten, volumetrische geometrie optimaliseren en texturen synthetiseren. Openbare tutorials en praktische handleidingen rapporteren. Real-world verwerkingstijden van enkele minuten tot meerdere uren, afhankelijk van de opnamelengte en -kwaliteit. Een veelgeciteerd tutorialvoorbeeld toonde 30 minuten tot een uur voor een gemiddelde opname; andere soorten opnames (lange walkthroughs, frames met een hoge resolutie) kunnen langer duren.
Representatieve bereiken
- Snelle object-/productscans (20–80 foto's, korte opname): een paar minuten tot ~30 minuten.
- Opnamen op kamerformaat of doorloopopnamen (honderden tot duizenden frames): 30 minuten tot enkele uren, afhankelijk van de invoergrootte en de uiteindelijke exportgetrouwheid.
- High-fidelity export voor game engines (meshes, high-res texturen): voeg extra tijd toe voor het genereren van mesh, retopologie en bakken — dit kan taken naar de uur.
Waarom 3D langer duurt dan korte video's
3D-reconstructie is iteratief en vergt veel optimalisatie: het model verfijnt volumetrische velden en textuurvoorspellingen over meerdere frames, wat rekenintensief is. De backend van Luma paralleliseert een groot deel van dit werk, maar de omvang van de berekeningen per taak blijft groter dan één korte videogeneratie.
Wat zijn de belangrijkste factoren die de verwerkingstijd van Luma AI beïnvloeden?
Model- en pijplijnkeuze (Ray2, Photon, Genie, Modify Video)
Verschillende Luma-modellen en -functies zijn ontworpen met verschillende afwegingen: Ray2 en Dream Machine geven prioriteit aan fotorealistische videogeneratie met interactieve feedback met lage latentie, terwijl Photon en Genie geoptimaliseerd zijn voor beeldverbetering of 3D-reconstructie en mogelijk zwaarder van ontwerp zijn. Het kiezen van een model met hogere getrouwheidsinstellingen verhoogt de rekentijd. Officiële documentatie en de API beschrijven meerdere modeleindpunten en kwaliteitsvlaggen die de runtime beïnvloeden.
Invoergrootte en complexiteit
- Aantal frames / foto's: meer input = meer optimalisatiestappen.
- Resolutie: hogere uitvoerresoluties en invoer met een hogere resolutie verhogen de verwerkingstijd.
- Lengte van de gevraagde clip: langere clips vereisen meer rendering en controles op bewegingscoherentie.
Accountniveau, wachtrij en prioriteit
Betaalde abonnementen en zakelijke/API-klanten krijgen vaak voorrang of hogere limieten. Gratis gebruikers ervaren vaak langere wachtrijen wanneer het systeem onder druk staat. Communityrapporten bevestigen dit: betaalde abonnementen verkorten over het algemeen de wachttijd en verbeteren de doorvoer.
Systeembelasting en tijdstip van de dag
Uit praktijkonderzoeken van gebruikers blijkt dat de opwekkingstijden kunnen pieken tijdens piekuren of wanneer de lancering van belangrijke functies pieken veroorzaakt. Het team van Luma werkt de infrastructuur continu bij (zie changelogs) om de capaciteit aan te passen, maar er blijven tijdelijke vertragingen optreden.
Netwerk-/uploadtijd en clientapparaat
Voor capture-workflows zijn uploadsnelheid en apparaatprestaties van belang: grote uploads van meerdere gigabytes verhogen de kloksnelheid voordat de verwerking überhaupt begint. De documentatie van Luma vermeldt maximale bestandsgroottes en adviseert over best practices voor capture om onnodige gegevensoverdracht te minimaliseren.
Hoe kan ik de doorlooptijd van een opdracht vooraf inschatten en de wachttijd verkorten?
Snelle schattingschecklist
- Classificeer uw baan: afbeelding, korte video (<15s), langere video (>15s) of 3D-opname.
- Tel de ingangen: aantal foto's / videolengte (seconden) / bestandsgrootte van de opname.
- Bepaal de kwaliteit: lage, standaard of hoge betrouwbaarheid — hogere betrouwbaarheid = langere rekentijd.
- Controleer accountniveau: gratis vs. betaald vs. enterprise; houd rekening met mogelijke wachtrijen.
- Voer een korte test uit: maak een testopdracht van 5–10 seconden om een realistische uitgangswaarde te verzamelen.
Praktische tips om de doorvoer te versnellen
- Gebruik aanbevolen vastlegpatronen (soepele camerabeweging, consistente belichting), zodat de reconstructie sneller convergeert. De leerhub en mobiele app-pagina's van Luma bieden best practices voor het vastleggen van beelden.
- Verklein de invoergrootte indien acceptabel: snijd, downsamp of trim beeldmateriaal vóór het uploaden om de verwerkingstijd en -kosten te verminderen.
- Kies voor concepten voorinstellingen van lagere kwaliteiten rond het pas af op hoge kwaliteit als u tevreden bent met de compositie.
- Plan zware ritten buiten de spits als het kan; uit gemeenschapsrapporten blijkt dat de wachtrijen buiten de spitsuren korter zijn.
- Overweeg API-/enterprise-opties Als u schaalbaarheid en een voorspelbare SLA nodig hebt, tonen de API en het wijzigingslogboek van Luma voortdurende investeringen in prestaties en nieuwe eindpunten zoals Modify Video om workflows te stroomlijnen.
Hoe verhouden de timingcijfers van Luma zich tot die van andere tools?
Het vergelijken van generatieve beeld-/video- of NeRF-diensten is complex, omdat elke provider optimaliseert voor verschillende afwegingen (kwaliteit versus snelheid versus kosten). Voor het genereren van afbeeldingen en zeer korte video's concurreert Luma's Dream Machine – met name met Ray2 Flash – met een interactieve latentie van minder dan een minuut, wat vergelijkbaar is met toonaangevende generatieve diensten voor consumenten. Voor volledige NeRF-opnames en het creëren van high-fidelity 3D-modellen, zijn cloud computing-vereisten en wachtrij-pushtijden hoger dan bij snelle beeldgeneratoren: verwacht grotere variantie en plan dienovereenkomstig. Partnerdocumentatie en beschrijvingen van derden geven vaak aan dat minuten voor korte, eenvoudige renders en uren (of onvoorspelbaar langer) voor complexe 3D-pijplijnen.
Eindoordeel - hoe lang nog? wil Luma neemt het over my functie?
Er is geen enkel getal dat voor elke gebruiker of elke taak geldt. Gebruik deze pragmatische ankers om te schatten:
- Beeldgeneratie (Dream Machine): ~20–30 seconden per kleine batch onder normale belasting.
- Korte videogeneratie (Dream Machine / Ray2): tientallen seconden tot een paar minuten voor korte clips; Ray2 Flash kan aanzienlijk sneller zijn op ondersteunde flows.
- 3D-opname → NeRF: zeer variabel. Beste geval: minuten voor een klein object en lichtberekening; ergste geval (gerapporteerd): Vele uren tot dagen bij grote vraag of voor zeer grote opnames. Als u een strakke planning nodig hebt, koop dan prioriteits-/enterprise-abonnementen of voer pre-productiepilots uit en bouw geplande buffertijd in uw planning in.
Beginnen
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars hebben toegang tot Luma-API brengt KomeetAPIDe nieuwste modellen die vermeld staan, gelden vanaf de publicatiedatum van het artikel. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen bij de integratie van: