

Het Chinese Z.ai (voorheen Zhipu AI) heeft opnieuw de krantenkoppen gehaald met de lancering van zijn open-source GLM 4.5-serie. Gepositioneerd als een kostenefficiënt en krachtig alternatief voor bestaande, grootschalige taalmodellen, belooft GLM-4.5 de tokeneconomie te hervormen en de toegang voor startups, ondernemingen en onderzoeksinstellingen te democratiseren. Dit uitgebreide artikel onderzoekt de oorsprong, prijsstructuur en reële waarde van de GLM-4.5-serie en behandelt de twee belangrijkste vragen die elke stakeholder bezighouden: hoeveel kost het en is het de moeite waard?
Wat is de GLM 4.5-serie?
De GLM 4.5-serie van Z.ai is gebaseerd op een 'agentisch' AI-framework. Dit betekent dat het model complexe taken autonoom kan opsplitsen in kleinere, opeenvolgende subtaken, wat de precisie verbetert en redundante berekeningen vermindert. Dit in tegenstelling tot meer monolithische LLM's die prompts in één keer verwerken. Volgens Z.ai integreert GLM 4.5 redenering en actieplanning standaard in de kernarchitectuur, waardoor workflows met meerdere stappen, zoals het genereren van datavisualisatie of end-to-end documentverwerking, mogelijk zijn zonder externe orkestratie.
De GLM 4.5-serie, ontwikkeld door Z.ai, vertegenwoordigt de nieuwste generatie open-source, Mixture-of-Experts (MoE) grote taalmodellen, ontworpen om geavanceerd redeneren, codegeneratie en agentische mogelijkheden te verenigen binnen één architectuur. De serie is verkrijgbaar in twee hoofdvarianten: het vlaggenschip GLM 4.5 (355 B totale parameters, 32 B actief) en de lichtere GLM 4.5‑Air (106 B totaal, 12 B actief). Beide varianten maken gebruik van een hybride inferentiemechanisme – de 'denkmodus' voor complexe, toolgestuurde redeneringen en de 'niet-denkmodus' voor snelle, eenvoudige voltooiingen – en zijn geschikt voor een breed spectrum aan use cases, van full-stack ontwikkeling tot autonome agentworkflows.
kern technische specificaties:
- Kenmerken :GLM 4.5 bevat 355 miljard parameters, met een actieve subset van 32 miljard per inferentie om hardwaregebruik en doorvoer te optimaliseren.
- Mix-of-Experts (MoE):De serie maakt gebruik van de MoE-architectuur en routeert tokens dynamisch naar subnetwerken van experts voor meer efficiëntie.
- Contextvenster: Uitgebreid naar 128 K tokens op geselecteerde platforms (bijv. SiliconFlow), geschikt voor grote documenten en codebases.
- Generatiesnelheid: Varianten met hoge snelheid overschrijden 100 tokens/sec, geschikt voor realtimetoepassingen.
- Hybride inferentiemodiGebruikers kunnen schakelen tussen de 'denk'-modus (volledige MoE-activering voor diepgaand redeneren) en de 'niet-denken'-modus (minimale activering voor snelle, directe reacties), waardoor ontwikkelaars nauwkeurige controle hebben over prestaties versus snelheid.
Welke varianten bestaan er binnen de Serie?
- GLM 4.5 (Standaard): 355 B totaal / 32 B actieve parameters. Primair ontworpen voor evenwichtige prestaties bij redeneren, coderen en agentische taken.
- GLM 4.5‑Air: Een lichtgewicht versie met een totale capaciteit van 106 B / een actieve parameter van 12 B, speciaal ontworpen voor scenario's met strenge hardware- of latentiebeperkingen, en die een concurrerende nauwkeurigheid in zijn klasse levert.
Hoeveel kost de GLM 4.5-serie?
Wat zijn de input- en output-tokenprijzen?
Volgens de openbare API-prijsinformatie van Z.ai bedraagt de prijs van GLM 4.5:
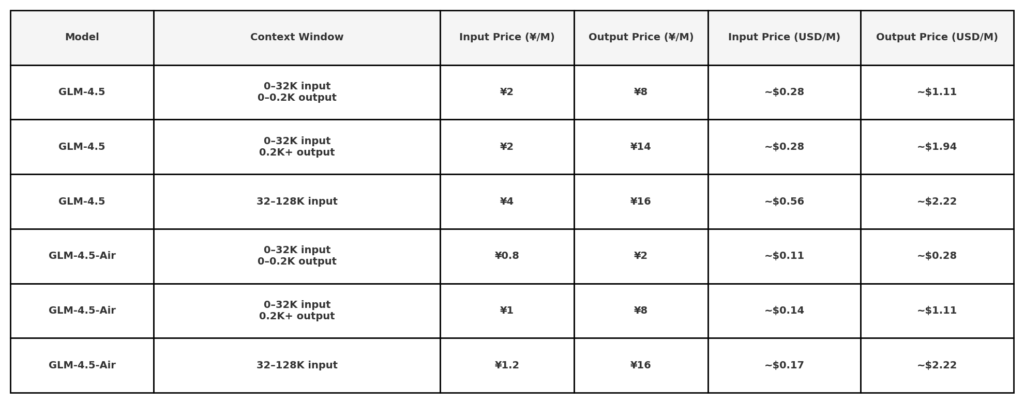
Let op: zeer lage tarieven ($0.11/$0.28) kunnen beperkt zijn tot kleine tokenlengtes of specifieke promoties. 50% korting op alle modellen voor een beperkte tijd, geldig tot 31 augustus 2025. Zie voor andere modellen kantoorprijspagina.
Op de CometAPI wordt de serie gebundeld met licht afwijkende prijsniveaus, zie GLM‑4.5 API:
| Model | voorstellen | Prijs |
glm-4.5 | Ons krachtigste redeneermodel, met 355 miljard parameters | Invoertokens $0.48 Uitvoertokens $1.92 |
glm-4.5-air | Kosteneffectieve lichtgewicht sterke prestaties | Invoertokens $0.16 Uitvoertokens $1.07 |
glm-4.5-x | Hoge prestaties, sterk redeneren, ultrasnelle respons | Invoertokens $1.60 Uitvoertokens $6.40 |
glm-4.5-airx | Lichtgewicht, sterke prestaties, ultrasnelle respons | Invoertokens $0.02 Uitvoertokens $0.06 |
glm-4.5-flash | Sterke prestaties, uitstekend voor redeneren, codering en agenten | Invoertokens $3.20 Uitvoertokens $12.80 |
Hoe verhouden de prijzen van GLM 4.5 zich tot die van DeepSeek en Western LLM's?
Op de World AI Conference van 2025 positioneerde Z.ai GLM 4.5 expliciet als een uitdager van DeepSeek, de voormalige kostenleider in China, en beloofde "een fractie van de tokenkosten" en de helft van de hardwarevoetafdruk van DeepSeeks R1-model.
- Diep zoeken R1: Ongeveer USD 0.14 input, USD 0.60 output per miljoen tokens.
- GLM 4.5: Zou DeepSeek met 20-30% onderbieden op zowel input als output.
- Westerse benchmarks: OpenAI's GPT‑4 en Google's Gemini variëren in prijs van 3 tot 15 dollar per miljoen tokens, wat GLM 4.5 positioneert als een kostenbesparing van de orde van grootte.
Deze prijsstrategie weerspiegelt het bredere Chinese AI-economische model: slankere computing, kleinere modellen en agressieve prijsverlagingen om marktaandeel te veroveren.
Zijn de GLM 4.5-series het waard?
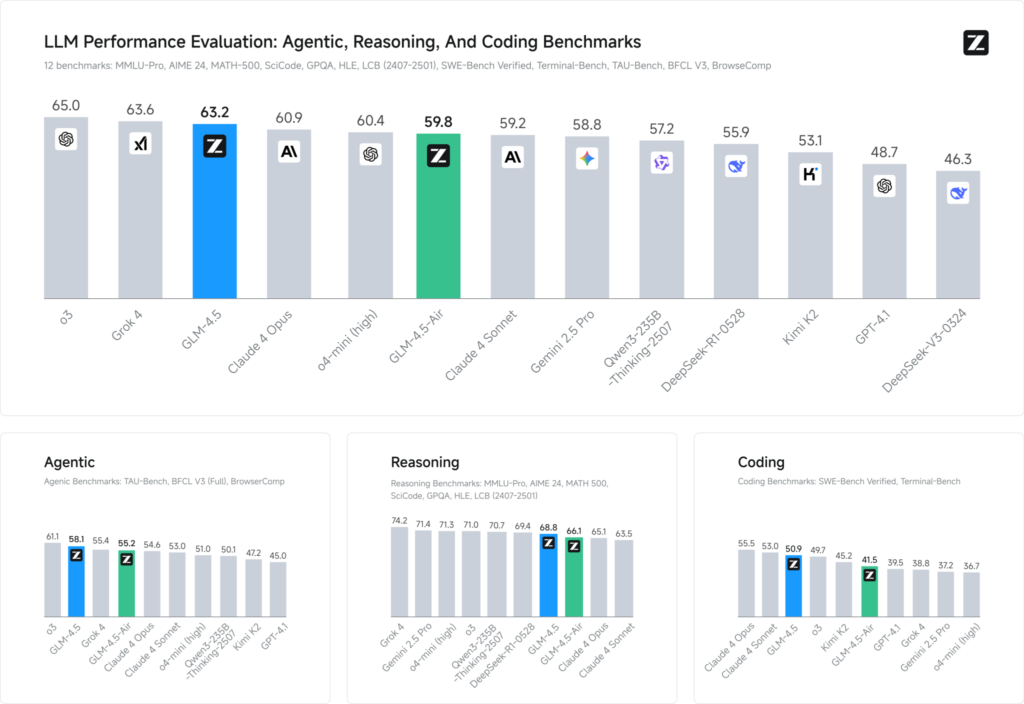
Benchmarkevaluaties van 12 representatieve datasets (MMLU Pro, MATH 500, SciCode, Terminal-Bench en TAU-Bench) laten zien dat GLM 4.5 wereldwijd op de 3e plaats staat, achter Grok 4 van xAI en o3 van OpenAI, maar toch op de eerste plaats staat onder de open-sourceaanbiedingen.
Bij codeertaken (LiveCodeBench, SWE-Bench) draagt het Mixture-of-Experts-ontwerp van GLM 4.5 bij aan een hoogwaardige codegeneratie, terwijl bij redeneren (AIME 24, MMLU Pro) de meerstapsplanning een robuuste nauwkeurigheid oplevert die vergelijkbaar is met die van closed-source-varianten. De lichtgewicht Air-variant behoudt concurrerende scores binnen zijn parameterbereik (schaal van 100 B), waardoor het een aantrekkelijke keuze is voor edge-implementaties en embedded systemen.
Prestatiebenchmarks
- Intelligentie-index: GLM 4.5 scores 66 op een samengestelde Intelligence Index (MMLU Pro, MATH 500, AIME 24), waarmee het veel open-source en commerciële middenklassemodellen overtreft.
- Inferentie latentie: Gemiddelden van de tijd tot het eerste token 0.89 seconden, concurrerend voor complexe redeneertaken, hoewel iets langzamer in doorvoer (≈45.7 tokens/s) vergeleken met sommige geoptimaliseerde gesloten-bronmodellen.
- Agentische workflow: Toont een robuuste beheersing van het gebruik van multi-staps tools en dynamische codegeneratie, met een head-to-head winstpercentage van ~54% tegen Kimi K2 en 81% tegen Qwen3‑Coder in onafhankelijke coderingsevaluaties.
Welke praktische use cases laten een ROI zien?
- Full-Stack Ontwikkeling:GLM‑4.5 kan complete webapplicaties ondersteunen, van frontend-layouts in HTML/CSS/JavaScript tot backend-databaseschema's, via multi-turn prompts, waardoor prototypecycli van dagen naar uren worden teruggebracht.
- Complexe documentanalyseDankzij het uitgebreide contextvenster van 128 K kunnen juridische, financiële en wetenschappelijke bedrijven contracten of onderzoeksrapporten van meerdere pagina's in één keer verwerken, waardoor de segmentatiekosten worden verlaagd.
- Geautomatiseerde agentworkflows:Hybride inferentie maakt het mogelijk om autonome scripts te creëren (bijvoorbeeld webscrapingbots, handelsagenten) die redeneren via processen met meerdere stappen met minimale menselijke tussenkomst.
Kwantitatieve casestudies suggereren tot 60 procent vermindering van de ontwikkelaarsuren voor codegerichte taken en 40 procent snellere doorlooptijd voor analyses van langere content.
Wat zijn de mogelijke nadelen en overwegingen?
Geen enkele technologie kent compromissen. Potentiële gebruikers moeten rekening houden met regelgeving, operationele aspecten en ecosysteemfactoren.
Beperkingen
Ondersteuning en SLA's:Open-sourceproviders bieden mogelijk geen SLA's op ondernemingsniveau of 24/7-ondersteuning, in tegenstelling tot commerciële tegenhangers.
Doorvoerbeperkingen:Hoewel het contextvenster enorm is, blijven de token-per-seconde-snelheden achter bij die van sommige gesloten-source-tegenhangers die geoptimaliseerd zijn voor afleiding, wat van invloed kan zijn op realtime-toepassingen.
Operationele overhead:Zelf-hostende MoE-modellen vereisen een zorgvuldige orkestratie (deskundige routering, geheugenbeheer) om prestatieknelpunten en kostenoverschrijdingen te voorkomen.
Welke infrastructuurinvesteringen zijn nodig?
- Rekenvoetafdruk: Zelfs met MoE-efficiëntie vereist het hosten van de standaardvariant van GLM‑4.5 GPU's met ≥80 GB geheugen en robuuste NVLink-verbindingen voor lage latentie-inferentie.
- Overheadkosten voor fijnafstelling: Het aanpassen van het model voor domeinspecifieke taken kan aanzienlijke GPU-cycli vereisen, waardoor de initiële kosten oplopen voordat u besparingen op de tokenfacturering ziet.
- Onderhoud: Bij implementaties op locatie wordt de verantwoordelijkheid voor updates, beveiligingspatches en opschaling verlegd van de leverancier naar interne DevOps-teams.
Hoe kunt u aan de slag met GLM‑4.5?
Het integreren van GLM-4.5 gaat in een paar eenvoudige stappen, vooral gezien het open-sourcehandboek en de uitgebreide ondersteuning van derden.
Welke API's en platforms ondersteunen GLM-4.5?
- KomeetAPI API: Volledig OpenAI-compatibel eindpunt, met SDK's in Python, JavaScript en Java.
- Direct Z.ai-eindpunt: Biedt officiële ondersteuning en functies voor vroege toegang, zoals multi-agent-orkestratie.
- Gemeenschapsspiegels: Snelgroeiende reeks open-source runtimes (bijv. Ollama, AutoGPT-CLI) die lokale inferentie mogelijk maken.
Waar kunnen ontwikkelaars tools en documentatie vinden?
- Officiële Z.ai-documentatie: Uitgebreide handleidingen over installatie, snelle engineering en MoE-optimalisatie.
- GitHub-opslagplaatsen: Voorbeeldnotebooks voor codegeneratie, retrieval-augmented generation (RAG) en agentframeworks die compatibel zijn met belangrijke orkestratietools.
- Gemeenschapsforums: Actieve discussiefora op platforms zoals Hugging Face, waar professionals recepten voor het verfijnen van hun vaardigheden, bibliotheken met prompts en prestatiebenchmarks delen.
Conclusie
De GLM-4.5-serie maakt een gewaagde claim in het huidige hypercompetitieve AI-landschap: ongeëvenaarde kosten-batenverhouding voor ontwikkelaars, bedrijven en onderzoeksinstellingen. Met tokenprijzen vanaf $ 0.11 per miljoen inputtokens en $ 0.28 per miljoen outputs – nog eens extra verlaagd met een promotiekorting van 50 procent – en benchmarkprestaties die grotere, gepatenteerde modellen evenaren of overtreffen, levert GLM-4.5 een substantiële ROI voor codegerichte applicaties, long-form understanding en agentic workflows.
Beginnen
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars hebben toegang tot GLM-4.5 Lucht API en GLM‑4.5 API brengt KomeetAPIDe meest recente versies van de Claude-modellen zijn van de publicatiedatum van het artikel. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.