

Aan de slag gaan met Gemini 2.5 Flash-Lite via CometAPI biedt een interessante kans om een van de meest kostenefficiënte generatieve AI-modellen met lage latentie te benutten. Deze handleiding combineert de nieuwste aankondigingen van Google DeepMind, gedetailleerde specificaties uit de Vertex AI-documentatie en praktische integratiestappen met CometAPI om u te helpen snel en effectief aan de slag te gaan.
Wat is Gemini 2.5 Flash-Lite en waarom is het een overweging waard?
Overzicht van de Gemini 2.5-familie
Medio juni 2025 bracht Google DeepMind officieel de Gemini 2.5-serie uit, inclusief stabiele GA-versies van Gemini 2.5 Pro en Gemini 2.5 Flash, naast een preview van een gloednieuw, lichtgewicht model: Gemini 2.5 Flash-Lite. De 2.5-serie is ontworpen om de juiste balans te vinden tussen snelheid, kosten en prestaties en vertegenwoordigt Google's streven om een breed spectrum aan toepassingen te bedienen – van zware onderzoekstaken tot grootschalige, kostengevoelige implementaties.
Belangrijkste kenmerken van Flash-Lite
Flash-Lite onderscheidt zich door multimodale mogelijkheden (tekst, afbeeldingen, audio, video) te bieden met een extreem lage latentie, met een contextvenster dat tot een miljoen tokens ondersteunt en toolintegraties zoals Google Zoeken, code-uitvoering en functieaanroepen. Belangrijk is dat Flash-Lite de controle over het "gedachtebudget" introduceert, waardoor ontwikkelaars de diepte van de redenering kunnen afwegen tegen de responstijd en kosten door een interne parameter voor het tokenbudget aan te passen.
Positionering in het modellengamma
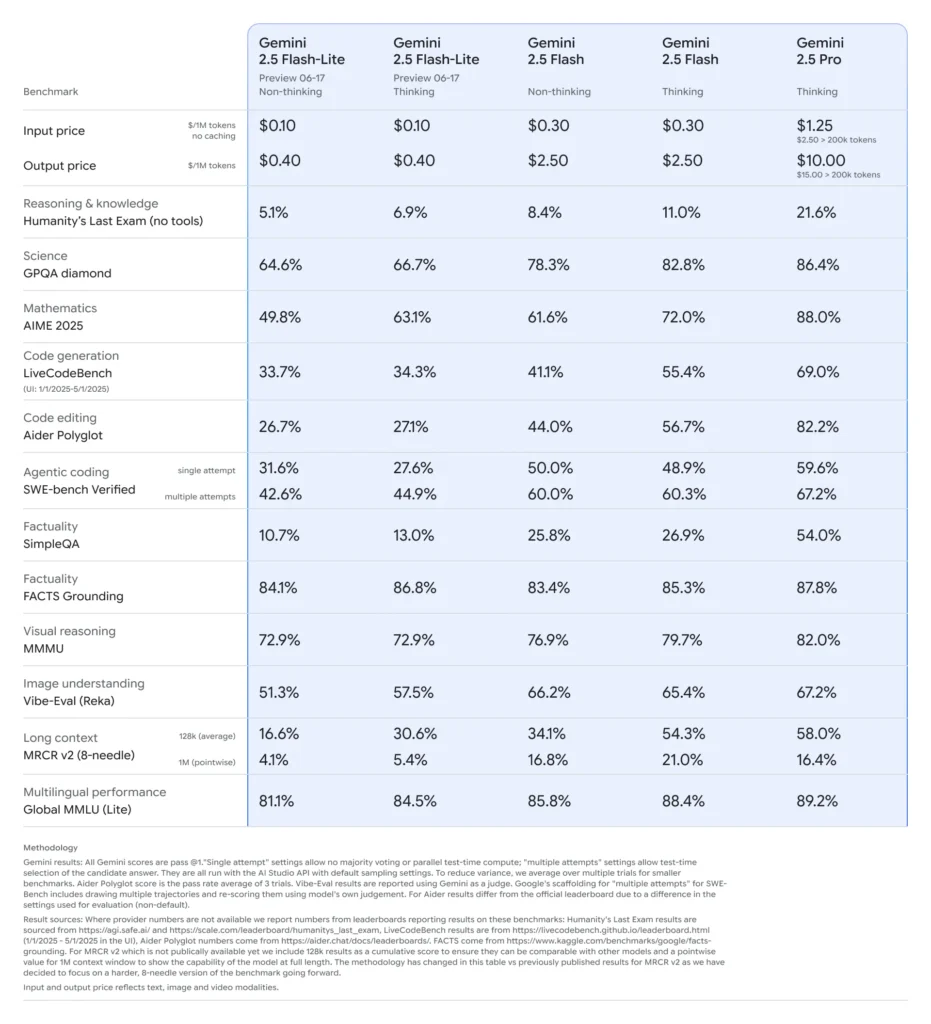
Vergeleken met zijn broertjes en zusjes bevindt Flash-Lite zich op de Pareto-grens van kostenefficiëntie: met een prijs van ongeveer $ 0.10 per miljoen inputtokens en $ 0.40 per miljoen outputtokens tijdens de preview, ondermijnt het zowel Flash ($ 0.30/$ 2.50) als Pro ($ 1.25/$ 10), terwijl het de meeste van hun multimodale mogelijkheden en functieaanroepondersteuning behoudt. Dit maakt Flash-Lite ideaal voor taken met een hoog volume en lage complexiteit, zoals samenvattingen, classificatie en eenvoudige conversationele agents.
Waarom zouden ontwikkelaars Gemini 2.5 Flash-Lite moeten overwegen?
Prestatiebenchmarks en praktijktests
Bij directe vergelijkingen liet Flash-Lite het volgende zien:
- 2× snellere doorvoer dan Gemini 2.5 Flash bij classificatietaken.
- 3× kostenbesparing voor samenvattingspipelines op ondernemingsniveau.
- Concurrerende nauwkeurigheid op logica-, wiskunde- en codebenchmarks, die gelijkwaardig zijn aan of zelfs beter zijn dan eerdere Flash-Lite-previewers.
Ideale use cases
- Chatbots met een groot volume: Bied consistente, gesprekservaringen met lage latentie aan miljoenen gebruikers.
- Geautomatiseerde contentgeneratie: Schaal het samenvatten van documenten, vertalingen en het maken van microkopieën.
- Zoek- en aanbevelingspijplijnen: Maak gebruik van snelle gevolgtrekkingen voor realtime personalisatie.
- Batchgegevensverwerking: Grote datasets annoteren met minimale rekenkosten.
Hoe verkrijgt en beheert u API-toegang voor Gemini 2.5 Flash-Lite via CometAPI?
Waarom CometAPI als uw gateway gebruiken?
CometAPI verzamelt meer dan 500 AI-modellen, waaronder de Gemini-serie van Google, onder één uniform REST-eindpunt, waardoor authenticatie, snelheidsbeperking en facturering tussen providers worden vereenvoudigd. In plaats van te jongleren met meerdere basis-URL's en API-sleutels, verwijst u alle verzoeken naar https://api.cometapi.com/v1, specificeer het doelmodel in de payload en beheer het gebruik via één dashboard.
Vereisten en aanmelden
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
- Haal de url van deze site op: https://api.cometapi.com/
Uw tokens en quota's beheren
Het dashboard van CometAPI biedt uniforme tokenquota die gedeeld kunnen worden met Google, OpenAI, Anthropic en andere modellen. Gebruik de ingebouwde monitoringtools om gebruikswaarschuwingen en snelheidslimieten in te stellen, zodat u nooit de begrote toewijzingen overschrijdt of onverwachte kosten maakt.
Hoe configureert u uw ontwikkelomgeving voor CometAPI-integratie?
Vereiste afhankelijkheden installeren
Voor Python-integratie installeert u de volgende pakketten:
pip install openai requests pillow
- openai: Compatibele SDK voor communicatie met CometAPI.
- verzoeken: Voor HTTP-bewerkingen zoals het downloaden van afbeeldingen.
- hoofdkussen: Voor beeldverwerking bij het verzenden van multimodale invoer.
Initialiseren van de CometAPI-client
Gebruik omgevingsvariabelen om uw API-sleutel uit de broncode te houden:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Deze clientinstantie kan nu elk ondersteund model targeten door de ID ervan op te geven (bijv. gemini-2.5-flash-lite-preview-06-17) in uw verzoeken.
Het configureren van het budget en andere parameters
Wanneer u een aanvraag verzendt, kunt u optionele parameters opnemen:
- temperatuur/top_p: Controleer willekeur bij de generatie.
- aantal kandidaten: Aantal alternatieve uitgangen.
- max_tokens: Cap voor uitvoertoken.
- gedachte_budget: Aangepaste parameter voor Flash-Lite om diepte in te ruilen voor snelheid en kosten.
Hoe ziet een basisverzoek aan Gemini 2.5 Flash-Lite via CometAPI eruit?
Voorbeeld van alleen tekst
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Met deze aanroep wordt binnen 200 ms een beknopte samenvatting gegenereerd, ideaal voor chatbots of realtime analysepijplijnen.
Voorbeeld van multimodaal invoer
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite verwerkt afbeeldingen tot 7 MB en retourneert contextuele beschrijvingen, waardoor het geschikt is voor documentbegrip, UI-analyse en geautomatiseerde rapportage.
Hoe kunt u geavanceerde functies zoals streaming en functieaanroepen benutten?
Streaming-reacties voor realtime-toepassingen
Gebruik de streaming API voor chatbotinterfaces of live ondertiteling:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Hierdoor worden gedeeltelijke uitvoerresultaten weergegeven zodra deze beschikbaar zijn, waardoor de waargenomen latentie in interactieve gebruikersinterfaces wordt verminderd.
Functie die gestructureerde gegevensuitvoer aanroept
Definieer JSON-schema's om gestructureerde reacties af te dwingen:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Deze aanpak garandeert JSON-conforme uitvoer, waardoor downstream gegevenspijplijnen en integraties worden vereenvoudigd.
Hoe optimaliseert u prestaties, kosten en betrouwbaarheid bij het gebruik van Gemini 2.5 Flash-Lite?
Gedachte budget afstemming
Met de gedachtebudgetparameter van Flash-Lite kunt u de hoeveelheid "cognitieve inspanning" die het model nodig heeft, nauwkeurig bepalen. Een laag budget (bijv. 0) geeft prioriteit aan snelheid en kosten, terwijl hogere waarden leiden tot diepere redeneringen ten koste van latentie en tokens.
Beheer van tokenlimieten en doorvoer
- Invoertokens: Tot 1,048,576 tokens per aanvraag.
- Uitvoertokens: Standaardlimiet van 65,536 tokens.
- Multimodale inputs: Tot 500 MB aan afbeeldingen, audio- en videobestanden.
Implementeer client-side batching voor workloads met een hoog volume en maak gebruik van de automatische schaalbaarheid van CometAPI om piekverkeer te verwerken zonder handmatige tussenkomst.
Kosten-efficiëntiestrategieën
- U kunt taken met een lage complexiteit samenvoegen in Flash-Lite en Pro of standaard Flash reserveren voor zwaardere taken.
- Gebruik tarieflimieten en budgetwaarschuwingen in het CometAPI-dashboard om ongecontroleerde uitgaven te voorkomen.
- Houd het gebruik per model-ID bij om de kosten per aanvraag te vergelijken en uw routeringslogica dienovereenkomstig aan te passen.
Wat zijn de beste werkwijzen en vervolgstappen na de eerste integratie?
Monitoring, logging en beveiliging
- Logging: Leg metagegevens van aanvragen/reacties vast (tijdstempels, latenties, tokengebruik) voor prestatiecontroles.
- Alerts: Stel drempelmeldingen in voor foutpercentages of kostenoverschrijdingen in CometAPI.
- Security: Roteer API-sleutels regelmatig en bewaar ze in veilige kluizen of omgevingsvariabelen.
Veelvoorkomende gebruikspatronen
- chatbots: Gebruik Flash-Lite voor snelle gebruikersvragen en stap terug naar Pro voor complexere vervolgvragen.
- Documentverwerking:Batch-PDF- of beeldanalyses 's nachts uitvoeren tegen een lager budget.
- Realtime analyses: Stream financiële of operationele gegevens voor directe inzichten via de streaming-API.
Verder verkennen
- Experimenteer met hybride prompts: combineer tekst- en beeldinvoer voor een rijkere context.
- Prototype RAG (Retrieval-Augmented Generation) door integratie van vectorzoekhulpmiddelen met Gemini 2.5 Flash-Lite.
- Vergelijk dit met concurrerende producten (bijv. GPT-4.1, Claude Sonnet 4) om de afwegingen tussen kosten en prestaties te valideren.
Schaalvergroting in productie
- Maak gebruik van de Enterprise-laag van CometAPI voor speciale quotapools en SLA-garanties.
- Implementeer blauw-groene implementatiestrategieën om nieuwe prompts of budgetten te testen zonder live gebruikers te storen.
- Controleer regelmatig de gebruiksstatistieken van het model om mogelijkheden voor verdere kostenbesparingen of kwaliteitsverbeteringen te identificeren.
Beginnen
CometAPI biedt een uniforme REST-interface die honderden AI-modellen samenvoegt onder één consistent eindpunt, met ingebouwd API-sleutelbeheer, gebruiksquota's en factureringsdashboards. Dit in plaats van te jongleren met meerdere leveranciers-URL's en inloggegevens.
Ontwikkelaars hebben toegang tot Gemini 2.5 Flash-Lite (preview) API(Model: gemini-2.5-flash-lite-preview-06-17) Door KomeetAPIDe nieuwste modellen die in dit artikel worden vermeld, gelden vanaf de publicatiedatum van het artikel. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
In slechts een paar stappen kunt u Gemini 2.5 Flash-Lite via CometAPI integreren in uw applicaties, waarmee u een krachtige combinatie van snelheid, betaalbaarheid en multimodale intelligentie ontsluit. Door de bovenstaande richtlijnen te volgen – inclusief installatie, basisverzoeken, geavanceerde functies en optimalisatie – bent u goed gepositioneerd om uw gebruikers AI-ervaringen van de volgende generatie te bieden. De toekomst van kostenefficiënte AI met hoge doorvoer is hier: ga vandaag nog aan de slag met Gemini 2.5 Flash-Lite.