

Kling O1 — uitgebracht tijdens de lanceringsweek van Kling AI's "Omni" — positioneert zichzelf als een enkel, uniform multimodaal videofundamentmodel dat tekst, afbeeldingen en video's in dezelfde aanvraag accepteert en video's kan genereren en bewerken in iteratieve workflows op regieniveau. Het team van Kling noemt O1 "'s werelds eerste uniforme multimodale videomodel op grote schaal". Klings interne tests claimen aanzienlijke winsten ten opzichte van Google's Veo 3.1 en Runway Aleph.
Wat is Kling O1?
Kling O1 (vaak op de markt gebracht als Video O1 or Omni Een) is een recent uitgebracht videofundamentmodel van Kling AI dat het genereren en bewerken van tekst, afbeeldingen en video verenigt in één enkel, promptgestuurd framework. In plaats van tekst-naar-video, afbeelding-naar-video en videobewerking als aparte pipelines te behandelen, accepteert Kling O1 gemengde input (tekst + meerdere afbeeldingen + optionele referentievideo) in één prompt, redeneert hierover en produceert coherente korte clips of bewerkt bestaand beeldmateriaal met nauwkeurige controle. Het bedrijf positioneerde de uitrol als onderdeel van een "Omni Launch" en beschrijft O1 als een "multimodale video-engine" gebouwd rond een Multimodal Visual Language (MVL)-paradigma en een Chain-of-Thought (CoT)-redeneringspad om complexe, meerdelige creatieve instructies te interpreteren.
Klings boodschap benadrukt drie praktische workflows: (1) tekst → videogeneratie, (2) afbeelding/element → video (compositing en onderwerp/rekwisiet-wissels met behulp van expliciete referenties), en (3) videobewerking/shot-continuïteit (restyling, object toevoegen/verwijderen, start-frame/eind-frame-besturing). Het model ondersteunt prompts voor meerdere elementen (inclusief een "@"-syntaxis voor het targeten van specifieke referentiebeelden) en bevat regisseursachtige besturingselementen zoals verankering van start-/eindframes en video-continuïteit om multi-shotsequenties te bouwen.
5 belangrijkste hoogtepunten van Kling O1
1) Echte uniforme multimodale invoer (MVL)
De belangrijkste functionaliteit van Kling O1 is het verwerken van tekst, stilstaande beelden (meerdere referenties) en video als hoogwaardige, gelijktijdige invoer. Gebruikers kunnen meerdere referentiebeelden (of een korte referentieclip) aanleveren. en een instructie in natuurlijke taal; het model parseert alle invoer samen om een coherente uitvoer te produceren of te bewerken. Dit vermindert de wrijving in de toolketen en maakt workflows mogelijk zoals 'gebruik onderwerp van @image1, plaats ze in de omgeving van @image2, pas de beweging aan ref_video.mp4en pas filmische kleurgraad X toe.” Deze framing met “Multimodale Visuele Taal” (MVL) vormt de kern van Klings pitch.
Waarom het uitmaakt: Echte creatieve workflows vereisen vaak het combineren van referenties: een personage uit één item, een camerabeweging uit een ander item en een narratieve instructie in tekst. Door deze input te bundelen, is generatie in één doorgang mogelijk en zijn er minder handmatige compositiestappen nodig.
2) Bewerken + genereren in één model (multi-elementenmodus)
De meeste eerdere systemen scheidden generatie (tekst → video) van frame-nauwkeurige bewerking. O1 combineert ze opzettelijk: hetzelfde model dat een clip helemaal zelf maakt, kan ook bestaand beeldmateriaal bewerken – objecten verwisselen, kleding restylen, rekwisieten verwijderen of een shot verlengen – allemaal via instructies in natuurlijke taal. Die convergentie vereenvoudigt de workflow aanzienlijk voor productieteams.
Het O1-model bereikt in de kern een diepe integratie van meerdere videotaken:
- Tekst-naar-video generatie
- Generatie van beeld-/onderwerpreferentie
- Videobewerking en inkleuren
- Video-restyle
- Volgende/vorige shotgeneratie
- Keyframe-beperkte videogeneratie
De grootste betekenis van dit ontwerp ligt in het feit dat complexe processen waarvoor voorheen meerdere modellen of onafhankelijke tools nodig waren, nu binnen één engine kunnen worden voltooid. Dit verlaagt niet alleen de kosten voor creatie en berekeningen aanzienlijk, maar legt ook de basis voor de ontwikkeling van een "uniform model voor videobegrip en -generatie".
3) De samenhang van de videogeneratie
Identiteitsconsistentie: Het O1-model verbetert de mogelijkheden voor cross-modale consistentiemodellering, waardoor de stabiliteit van de structuur, het materiaal, de belichting en de stijl van het referentieonderwerp behouden blijft tijdens het generatieproces:
- Het ondersteunt multi-view referentiebeelden voor onderwerpmodellering;
- Het ondersteunt cross-shot-onderwerpconsistentie (personage-, object- en scènekenmerken blijven doorlopend in verschillende shots);
- Het ondersteunt hybride multi-onderwerpreferenties, waardoor groepsportretten en interactieve scèneconstructie mogelijk zijn.
Dit mechanisme verbetert de coherentie en ‘identiteitsconsistentie’ van de videogeneratie aanzienlijk, waardoor het geschikt is voor scenario’s met extreem hoge consistentievereisten, zoals reclame en het genereren van shots op filmniveau.
Verbeterd geheugen: Het O1-model beschikt ook over een "geheugen", waardoor de uitvoerstijl niet instabiel wordt door lange contexten of veranderende instructies. Het kan zelfs:
- meerdere karakters tegelijk onthouden;
- verschillende personages in de video laten interacteren;
- Zorg voor consistentie in stijl, kleding en houding.
4) Nauwkeurige compositie met “@”-syntaxis en start-/eindframecontrole
Kling introduceerde een compositie-steno (gerapporteerd als een "@"-vermeldingssysteem) zodat u specifieke afbeeldingen in de prompt kunt verwijzen (bijv. @image1, @image2) om betrouwbaar rollen aan assets toe te wijzen. In combinatie met expliciete specificatie van start- en eindframes biedt dit controle op regieniveau over hoe elementen overgaan, bewegen of morphen in de gegenereerde clip – een op productie gerichte functionaliteit die O1 onderscheidt van veel consumentgerichte generatoren.
5) Hoge betrouwbaarheid, lange uitvoer en multi-task stacking
Kling O1 zou bioscoopwaardige 1080p-uitvoer (30 fps) produceren en – met eerdere Kling-versies die de toon zetten – prijst het bedrijf de mogelijkheid om langere clips te genereren (tot 2 minuten in recente productbeschrijvingen). Het ondersteunt ook het stapelen van meerdere creatieve taken in één aanvraag (genereren, een onderwerp toevoegen, belichting wijzigen en compositie bewerken). Deze eigenschappen maken het concurrerend met de duurdere tekst-naar-video engines.
Waarom het uitmaakt: Langere, hoogwaardige clips en de mogelijkheid om bewerkingen te combineren, beperken de noodzaak om veel korte clips aan elkaar te plakken en vereenvoudigen de productie van begin tot eind.
Hoe is Kling O1 ontworpen en wat zijn de onderliggende mechanismen?
O1 rond een Multimodale visuele taal (MVL) kern: een model dat gezamenlijke embeddings leert voor taal + afbeeldingen + bewegingssignalen (videoframes en optische flow-achtige functies) en vervolgens diffusie- of transformatorgebaseerde decoders toepast om temporeel coherente frames te synthetiseren. Het model wordt beschreven als uitvoerend conditioning op meerdere referenties (tekst, één-op-veel-afbeeldingen, korte videoclips) om een latente videorepresentatie te produceren die vervolgens wordt gedecodeerd in afbeeldingen per frame, waarbij de temporele consistentie behouden blijft via cross-frame attention of gespecialiseerde temporele modules.
1. Multimodale transformator + lange contextarchitectuur
Het O1-model maakt gebruik van de door Keling zelf ontwikkelde multimodale Transformer-architectuur, die tekst-, beeld- en videosignalen integreert en een lang temporeel contextgeheugen ondersteunt (Multimodal Long Context).
Hierdoor kan het model inzicht krijgen in de temporele continuïteit en ruimtelijke consistentie tijdens het genereren van video.
2. MVL: Multimodale visuele taal
MVL is de kerninnovatie van deze architectuur.
Het zorgt voor een diepgaande afstemming van taal- en visuele signalen binnen de Transformer via een uniforme semantische tussenlaag, waardoor:
- Het mogelijk maken om met één invoerveld multimodale instructies te mengen;
- Verbeteren van het nauwkeurige begrip van beschrijvingen in natuurlijke taal door het model;
- Ondersteuning voor uiterst flexibele interactieve videogeneratie.
De introductie van MVL markeert een verschuiving in de generatie van video van ‘tekstgedreven’ naar ‘semantisch-visueel co-gedreven’.
3. Mechanisme van de keten van gedachtenafleiding
Het O1-model introduceert een ‘Chain-of-Thought’-inferentiepad tijdens de videogeneratiefase.
Met dit mechanisme kan het model gebeurtenislogica en timingdeductie uitvoeren vóór de generatie, waardoor een natuurlijke verbinding tussen acties en gebeurtenissen in de video behouden blijft.
Inferentie- en bewerkingspijplijnen
- Generatie: feed: (tekst + optionele afbeeldingsrefs + optionele videorefs + generatie-instellingen) → model produceert latente videoframes → decoderen naar frames → optionele kleur-/tijdelijke nabewerking.
- Instructiegebaseerde bewerking: Feed: (originele video + tekstinstructie + optionele afbeeldingsreferenties) → model koppelt de gevraagde bewerking intern aan een set pixelruimtetransformaties en synthetiseert vervolgens bewerkte frames met behoud van ongewijzigde content. Omdat alles zich in één model bevindt, worden dezelfde conditionerings- en temporele modules gebruikt voor zowel creatie als bewerking.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
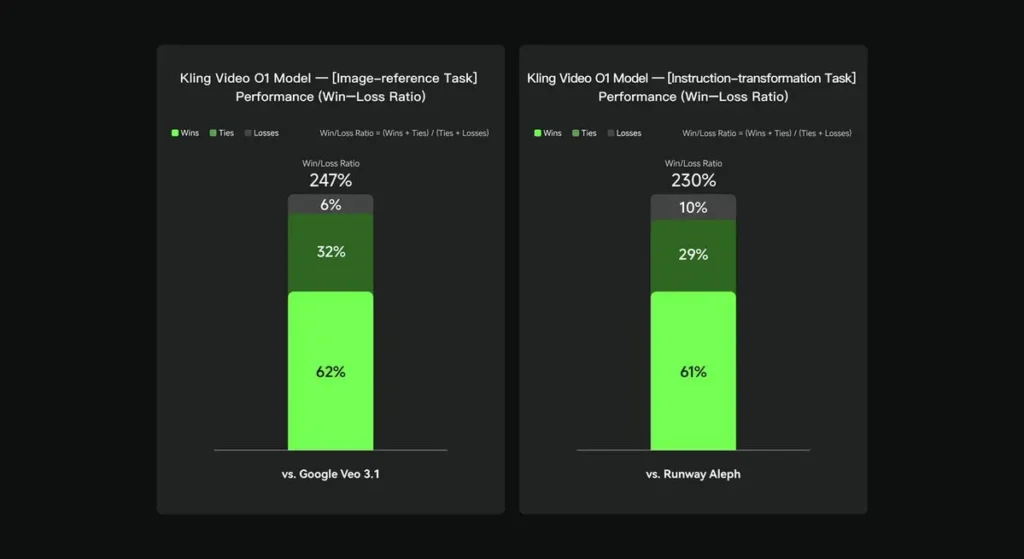
In interne evaluaties presteerde Keling Video O1 aanzienlijk beter dan bestaande internationale tegenhangers op verschillende belangrijke vlakken. Prestatieresultaten (gebaseerd op de door Keling AI zelf samengestelde evaluatieset):
- Taak “Afbeeldingsreferentie”: O1 presteert over het algemeen beter dan Google Veo 3.1, met een winstpercentage van 247%;
- Taak “Instructietransformatie”: O1 presteert beter dan Runway Aleph, met een winstpercentage van 230%.
Momentopname van de concurrent (vergelijking op functieniveau)
| Vermogen / Model | Kling O1 | Google Veo3.1 | Startbaan (Aleph / Gen-4.5) |
|---|---|---|---|
| Uniforme multimodale prompt (tekst + afbeeldingen + video) | Ja (belangrijkste verkoopargument). multimodale stromen met één aanvraag. | Gedeeltelijk — tekst→video + referenties bestaan; minder nadruk op één enkele, uniforme MVL. | Runway richt zich op generatie en bewerking, maar vaak als aparte modi; de nieuwste Gen-4.5 verkleint de kloof. |
| Conversatie-/tekstgebaseerde pixelbewerkingen | Ja — “bewerken als een gesprek” (geen maskers). | Gedeeltelijk — bewerken bestaat, maar masker-/keyframe-workflows zijn nog steeds gebruikelijk. | Runway beschikt over krachtige bewerkingstools; Runway claimt krachtige instructietransformaties (varieert per release). |
| Start-/eindframecontrole en camerareferentie | Ja — beschrijving van expliciete start-/eindframe- en referentiecamerabewegingen. | Beperkt / evoluerend | Runway: verbeterde bediening, niet precies dezelfde UX. |
| Lange clipgeneratie (high fidelity) | tot ~2 minuten (1080p, 30 fps) in productmaterialen en communityberichten; | Veo 3.1: sterke samenhang, maar eerdere versies hadden kortere standaardinstellingen; varieert afhankelijk van het model/de instelling. | Runway Gen-4.5: streeft naar hoge kwaliteit; lengte/getrouwheid varieert. |
Conclusie:
De publieke claim op roem van Kling O1 is workflow-unificatie: één model de opdracht geven om tekst, afbeeldingen en video te begrijpen en zowel generatie- als uitgebreide instructiegebaseerde bewerking binnen hetzelfde semantische systeem uit te voeren. Voor makers en teams die regelmatig schakelen tussen de stappen "creëren", "bewerken" en "uitbreiden", kan die consolidatie de iteratiesnelheid en de complexiteit van de tooling aanzienlijk vereenvoudigen. Verbeterde temporele consistentie, controle over start-/eindframes en pragmatische platformintegraties maken het toegankelijk voor makers.
De Kling Video o1 API zal binnenkort beschikbaar zijn op CometAPI.
Ontwikkelaars hebben toegang tot Kling 2.5 Turb en Veo 3.1-API brengt KomeetAPIDe nieuwste modellen die in dit artikel worden vermeld, gelden vanaf de publicatiedatum van het artikel. Om te beginnen, verken de mogelijkheden van het model in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt. KomeetAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!