

Op 17 juni heeft de Shanghai AI-eenhoorn MiniMax officieel de open source-versie vrijgegeven MiniMax‑M1, 's werelds eerste open-gewicht grootschalige hybride-attention inference model. Door een Mixture-of-Experts (MoE)-architectuur te combineren met het nieuwe Lightning Attention-mechanisme, levert MiniMax-M1 aanzienlijke verbeteringen in inferentiesnelheid, ultralange contextverwerking en complexe taakprestaties.
Achtergrond en evolutie
Voortbouwend op het fundament van MiniMax-Tekst-01, die razendsnelle aandacht introduceerde in een Mixture-of-Experts (MoE)-framework om contexten van 1 miljoen tokens te bereiken tijdens training en tot 4 miljoen tokens bij inferentie, vertegenwoordigt de MiniMax-M1 de volgende generatie van de MiniMax-01-serie. Het voorgaande model, de MiniMax-Text-01, bevatte in totaal 456 miljard parameters met 45.9 miljard geactiveerde parameters per token. Dit demonstreerde prestaties die vergelijkbaar waren met die van top-LLM's, terwijl de contextmogelijkheden aanzienlijk werden uitgebreid.
Belangrijkste kenmerken van de MiniMax‑M1
- Hybride MoE + Lightning-aandacht:MiniMax‑M1 combineert een spaarzaam Mixture‑of‑Experts-ontwerp (456 miljard parameters in totaal, maar slechts 45.9 miljard geactiveerd per token) met Lightning Attention, een lineaire complexiteitsattentie die is geoptimaliseerd voor zeer lange sequenties.
- Ultralange context: Ondersteunt tot 1 miljoen invoertokens, ongeveer acht keer de limiet van 128 K van DeepSeek‑R1, waardoor diepgaand inzicht in enorme documenten mogelijk is.
- Superieure efficiëntie:Bij het genereren van 100 K tokens vereist Lightning Attention van MiniMax‑M1 slechts ~25–30% van de rekenkracht die DeepSeek‑R1 gebruikt.
Modelvarianten
- MiniMax‑M1‑40K: 1 M tokencontext, 40 K token-inferentiebudget
- MiniMax‑M1‑80K: 1 M tokencontext, 80 K token-inferentiebudget
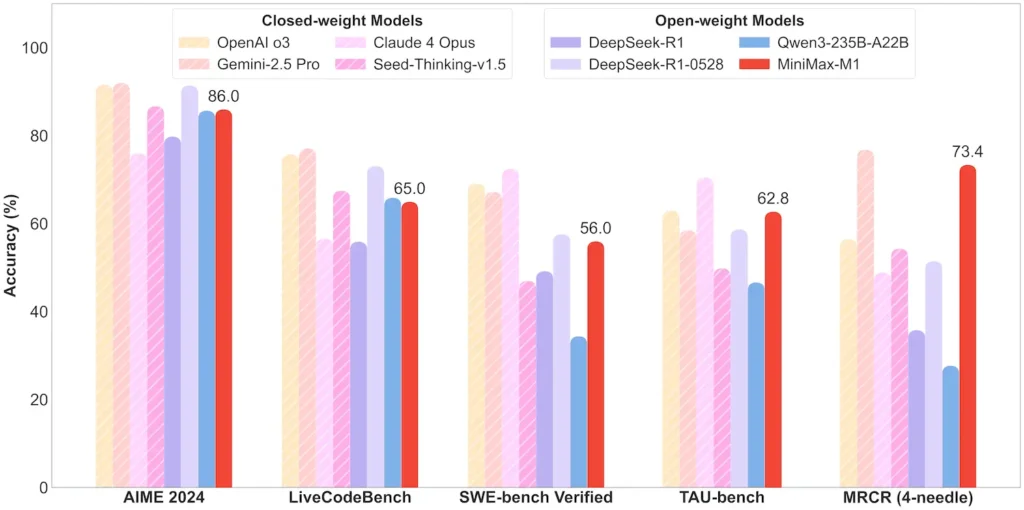
In TAU-benchtool-gebruikscenario's presteerde de 40K-variant beter dan alle open-weight-modellen, waaronder Gemini 2.5 Pro, wat zijn agentcapaciteiten aantoonde.
Trainingskosten en -opzet
MiniMax-M1 werd end-to-end getraind met behulp van grootschalige reinforcement learning (RL) voor een breed scala aan taken – van geavanceerd wiskundig redeneren tot sandbox-gebaseerde software engineering-omgevingen. Een nieuw algoritme, CISPO (Clipped Importance Sampling for Policy Optimization) verbetert de trainingsefficiëntie verder door gewichten voor clipping importance sampling te gebruiken in plaats van updates op tokenniveau. Deze aanpak, gecombineerd met de bliksemsnelle aandacht van het model, maakte volledige RL-training op 512 H800 GPU's mogelijk in slechts drie weken, tegen een totale huurprijs van $ 534,700.
Beschikbaarheid en Prijzen
MiniMax-M1 wordt uitgebracht onder de Apache 2.0 open‑sourcelicentie en is direct toegankelijk via:
- GitHub-repository, inclusief modelgewichten, trainingsscripts en evaluatiebenchmarks.
- SiliciumCloud hosting, waarbij twee varianten worden aangeboden - 40 K-token ("M1-40K") en 80 K-token ("M1-80K") - met plannen om de volledige 1 M-token-funnel mogelijk te maken.
- Prijzen momenteel vastgesteld op ¥4 per miljoen tokens voor invoer en ¥16 per miljoen tokens voor output, met volumekortingen voor zakelijke klanten.
Ontwikkelaars en organisaties kunnen MiniMax-M1 integreren via standaard-API's, afstemmen op domeinspecifieke gegevens of on-premises implementeren voor gevoelige workloads.
Prestaties op taakniveau
| Taakcategorie | Markeer | Relatieve prestaties |
|---|---|---|
| Wiskunde en logica | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; bijna gesloten bron |
| Lange-contextbegrip | Heerser (4 K–1 M tokens): Stabiele topklasse | Presteert beter dan GPT‑4 bij een tokenlengte van meer dan 128 K |
| Software Engineering | SWE‑bench (echte GitHub-bugs): 56% | Beste onder de open modellen; tweede na de leidende gesloten modellen |
| Agent- en gereedschapsgebruik | TAU-bench (API-simulatie) | 62-63.5% versus Gemini 2.5, Claude 4 |
| Dialoog & Assistent | MultiChallenge: 44.7% | Komt overeen met Claude 4, DeepSeek‑R1 |
| Feiten QA | Eenvoudige QA: 18.5% | Gebied voor toekomstige verbetering |
Let op: percentages en benchmarks afkomstig van officiële MiniMax-openbaarmaking en onafhankelijke nieuwsberichten
Technische innovaties
- Hybride aandachtsstapel: Bliksem aandacht lagen (lineaire kosten) afgewisseld met periodieke Softmax Aandacht (kwadratisch maar expressiever) voor evenwicht tussen efficiëntie en modelleringsvermogen.
- Sparse MoE-routering:32 expertmodules; elk token activeert slechts ~10% van de totale parameters, waardoor de inferentiekosten worden verlaagd en de capaciteit behouden blijft.
- CISPO-versterkingsleren: Een nieuw algoritme voor “Clipped IS‑weight Policy Optimization” dat zeldzame maar cruciale tokens in het leersignaal behoudt, waardoor de RL-stabiliteit en -snelheid worden versneld.
De open-gewicht release van de MiniMax-M1 maakt ultra-lange-context, zeer efficiënte inferentie mogelijk voor iedereen, en overbrugt zo de kloof tussen onderzoek en inzetbare grootschalige AI.
Beginnen
CometAPI biedt een uniforme REST-interface die honderden AI-modellen, waaronder de ChatGPT-familie, samenvoegt onder één consistent eindpunt, met ingebouwd API-sleutelbeheer, gebruiksquota's en factureringsdashboards. Dit voorkomt het gebruik van meerdere leveranciers-URL's en inloggegevens.
Om te beginnen, verken de mogelijkheden van modellen in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt.
De nieuwste integratie MiniMax‑M1 API zal binnenkort verschijnen op CometAPI, dus blijf op de hoogte! Terwijl we de upload van het MiniMax‑M1-model afronden, kunt u onze andere modellen bekijken op de Modellenpagina of probeer ze in de AI-speeltuinHet nieuwste model van MiniMax in CometAPI is Minimax ABAB7-Preview-API en MiniMax Video-01 API ,verwijzen naar:
