Gemini 2.5 Flash is ontworpen om snelle respons te leveren zonder in te boeten aan outputkwaliteit. Het ondersteunt multimodale input, waaronder tekst, afbeeldingen, audio en video, waardoor het geschikt is voor uiteenlopende toepassingen. Het model is toegankelijk via platforms zoals Google AI Studio en Vertex AI, en biedt ontwikkelaars de tools die nodig zijn voor naadloze integratie in diverse systemen.
Basisinformatie (Functies)
Gemini 2.5 Flash introduceert verschillende opvallende functies die het onderscheiden binnen de Gemini 2.5-familie:
- Hybride redenering: Ontwikkelaars kunnen een thinking_budget-parameter instellen om precies te bepalen hoeveel tokens het model besteedt aan interne redenering vóór de output.
- Paretofront: Gepositioneerd op het optimale prijs-prestatiepunt biedt Flash de beste verhouding tussen prijs en intelligentie binnen de 2.5-modellen.
- Multimodale ondersteuning: Verwerkt native tekst, afbeeldingen, video en audio, wat rijkere conversatie- en analysecapaciteiten mogelijk maakt.
- Contextvenster van 1 miljoen tokens: Ongeëvenaarde contextlengte maakt diepgaande analyse en begrip van lange documenten in één aanvraag mogelijk.
Versiebeheer van het model
Gemini 2.5 Flash heeft de volgende belangrijke versies doorlopen:
- gemini-2.5-flash-lite-preview-09-2025: Verbeterde bruikbaarheid van tools: betere prestaties op complexe, meerstappige taken, met een stijging van 5% in SWE-Bench Verified-scores (van 48,9% naar 54%). Verbeterde efficiëntie: bij ingeschakelde reasoning wordt met minder tokens een hogere outputkwaliteit bereikt, wat latentie en kosten verlaagt.
- Preview 04-17: Vroege toegang met “thinking”-capaciteit, beschikbaar via gemini-2.5-flash-preview-04-17.
- Stabiele algemene beschikbaarheid (GA): Sinds 17 juni 2025 vervangt het stabiele endpoint gemini-2.5-flash de preview, met productierijpe betrouwbaarheid en zonder API-wijzigingen ten opzichte van de preview van 20 mei.
- Uitfasering van preview: Preview-endpoints stonden gepland voor uitschakeling op 15 juli 2025; gebruikers moeten vóór deze datum migreren naar het GA-endpoint.
Per juli 2025 is Gemini 2.5 Flash nu publiek beschikbaar en stabiel (geen wijzigingen ten opzichte van de gemini-2.5-flash-preview-05-20). Als u gemini-2.5-flash-preview-04-17 gebruikt, blijft de bestaande preview-prijsstelling van kracht tot de geplande uitfasering van het model-endpoint op 15 juli 2025, wanneer het wordt uitgeschakeld. U kunt migreren naar het algemeen beschikbare model "gemini-2.5-flash".
Sneller, goedkoper, slimmer:
- Ontwerpdoelen: lage latentie + hoge doorvoer + lage kosten;
- Algehele versnelling bij redeneren, multimodale verwerking en taken met lange teksten;
- Het tokenverbruik is met 20–30% verlaagd, waardoor de kosten voor reasoning significant dalen.
Technische specificaties
Contextvenster voor invoer: Tot 1 miljoen tokens, waardoor uitgebreide contextretentie mogelijk is.
Uitvoertokens: Kan tot 8.192 tokens per respons genereren.
Ondersteunde modaliteiten: Tekst, afbeeldingen, audio en video.
Integratieplatforms: Beschikbaar via Google AI Studio en Vertex AI.
Prijzen: Concurrerend, op tokens gebaseerd prijsmodel, wat kostenefficiënte uitrol faciliteert.
Technische details
Onder de motorkap is Gemini 2.5 Flash een transformergebaseerd groot taalmodel, getraind op een mix van web-, code-, beeld- en videodata. Belangrijke technische specificaties zijn onder meer:
Multimodale training: Getraind om meerdere modaliteiten te aligneren; Flash kan naadloos tekst combineren met afbeeldingen, video of audio, nuttig voor taken zoals videosamenvatting of audiobeschrijving.
Dynamisch denkproces: Implementeert een interne redeneringslus waarbij het model plant en complexe prompts opsplitst vóór de uiteindelijke output.
Configureerbare denkbudgetten: Het thinking_budget kan worden ingesteld van 0 (geen reasoning) tot 24,576 tokens, waarmee u kunt afwegen tussen latentie en antwoordkwaliteit.
Tool-integratie: Ondersteunt Grounding with Google Search, Code Execution, URL Context en Function Calling, zodat echte acties direct vanuit natuurlijke taalprompts mogelijk zijn.
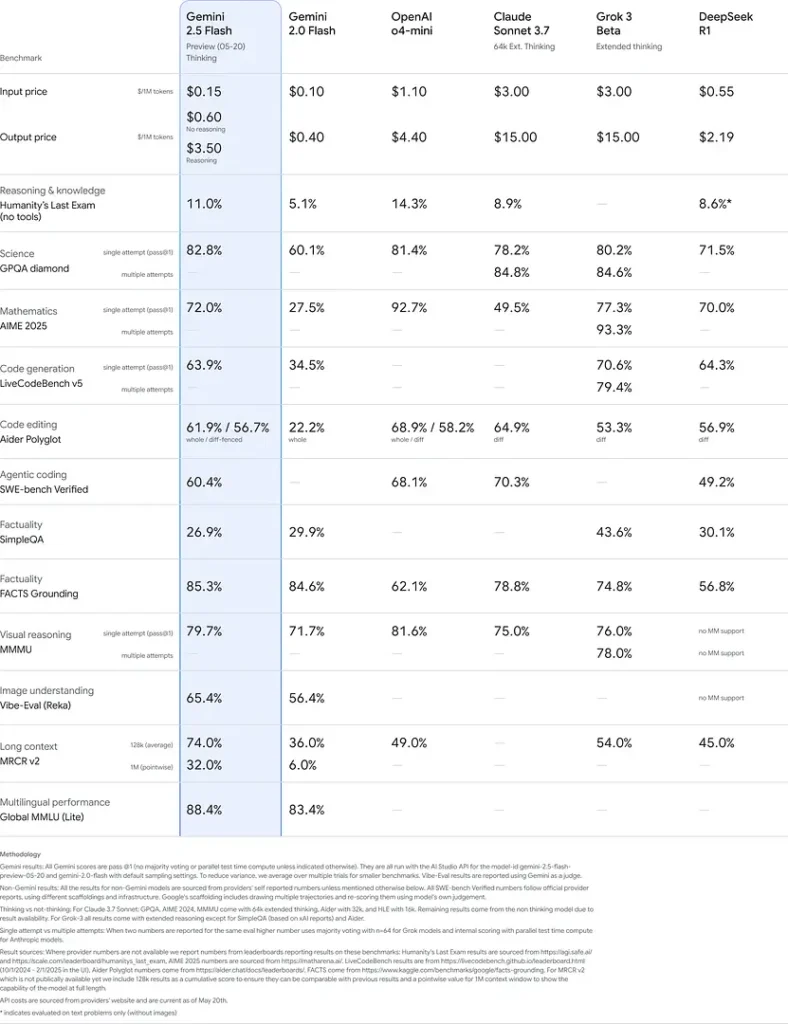
Benchmarkprestaties
In strenge evaluaties toont Gemini 2.5 Flash toonaangevende prestaties:
- LMArena Hard Prompts: Scoorde na 2.5 Pro de hoogste op de veeleisende Hard Prompts-benchmark, wat sterke meerstapsredeneercapaciteiten laat zien.
- MMLU-score van 0.809: Overtreft het gemiddelde modelprestatieniveau met een 0.809 MMLU-nauwkeurigheid, wat de brede domeinkennis en redeneervaardigheid weerspiegelt.
- Latentie en doorvoer: Bereikt een decodesnelheid van 271.4 tokens/sec met een 0.29 s Time-to-First-Token, ideaal voor latency-gevoelige workloads.
- Leider in prijs-prestatie: Met $0.26/1 M tokens is Flash goedkoper dan veel concurrenten, terwijl het op kernbenchmarks evenaart of beter presteert.
Deze resultaten duiden op het concurrentievoordeel van Gemini 2.5 Flash in redeneren, wetenschappelijk begrip, wiskundig probleemoplossen, coderen, visuele interpretatie en meertalige capaciteiten:
Beperkingen
Hoewel krachtig, kent Gemini 2.5 Flash bepaalde beperkingen:
- Veiligheidsrisico’s: Het model kan een moraliserende toon aannemen en plausibel klinkende maar onjuiste of bevooroordeelde outputs produceren (hallucinaties), vooral bij randgevallen. Strikte menselijke beoordeling blijft essentieel.
- Ratelimieten: API-gebruik is begrensd door limieten (10 RPM, 250,000 TPM, 250 RPD in standaardtiers), wat batchverwerking of toepassingen met hoog volume kan beïnvloeden.
- Ondergrens qua intelligentie: Hoewel uitzonderlijk capabel voor een flash-model, is het minder nauwkeurig dan 2.5 Pro bij de meest veeleisende agentische taken zoals geavanceerd coderen of multi-agentcoördinatie.
- Kostentrade-offs: Hoewel het de beste prijs-prestatie biedt, verhoogt intensief gebruik van de thinking-modus het totale tokenverbruik, waardoor de kosten voor diep redenerende prompts stijgen.