Technische details
- Adaptief redeneren:
Gemini 2.5 Flash-Liteondersteunt on-demand redeneren, waardoor ontwikkelaars rekenbronnen alleen toewijzen wanneer diepere redenering vereist is. - Toolintegraties: Volledige compatibiliteit met de native tools van Gemini 2.5, waaronder Grounding with Google Search, Code Execution, URL Context en Function Calling voor naadloze multimodale workflows.
- Model Context Protocol (MCP): Maakt gebruik van Google’s MCP om realtime webgegevens op te halen, waardoor antwoorden actueel en contextueel relevant zijn.
- Implementatieopties: Beschikbaar via de CometAPI, Gemini API, Vertex AI en Google AI Studio, met een previewtraject voor early adopters om te experimenteren en feedback te geven.
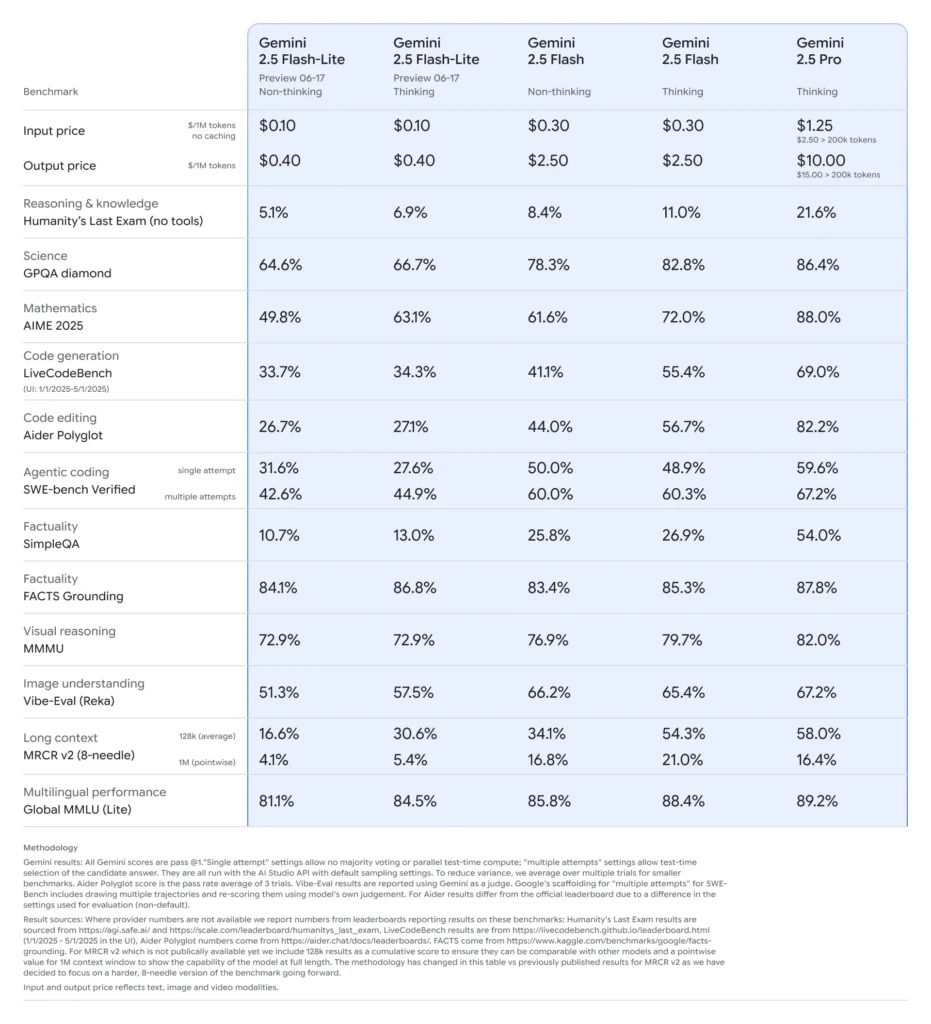
Benchmarkprestaties van Gemini 2.5 Flash-Lite
- Latentie: Realiseert tot 50% lagere mediane responstijden vergeleken met Gemini 2.5 Flash, met typische latenties onder de 100 ms op standaard classificatie- en samenvattingsbenchmarks.
- Doorvoer: Geoptimaliseerd voor workloads met hoge volumes, en kan tienduizenden verzoeken per minuut aan zonder prestatieverlies.
- Prijs-prestatie: Laat een kostenreductie van 25% per 1,000 tokens zien ten opzichte van de Flash-tegenhanger, waardoor het de Pareto-optimale keuze is voor kostengevoelige implementaties.
- Adoptie in de sector: Vroege gebruikers melden naadloze integratie in productiepijplijnen, met prestatiecijfers die overeenkomen met of de initiële prognoses overtreffen.
Ideale gebruiksscenario's
- Taken met hoge frequentie en lage complexiteit: Geautomatiseerde tagging, sentimentanalyse en bulkvertaling
- Kostengevoelige pijplijnen: Gegevensextractie uit grote documentencorpora, periodieke batchsamenvatting
- Edge- en mobiele scenario's: Wanneer latentie cruciaal is maar resourcebudgetten beperkt zijn
Beperkingen van Gemini 2.5 Flash-Lite
- Previewstatus: Kan API-wijzigingen ondergaan vóór GA; integraties moeten rekening houden met mogelijke versie-upgrades.
- Geen on-the-fly fine-tuning: Kan geen aangepaste gewichten uploaden; vertrouw op prompt-engineering en systeemberichten.
- Minder creativiteit: Afgestemd op deterministische taken met hoge doorvoer; minder geschikt voor open-eindegeneratie of ‘creatief’ schrijven.
- Resourceplafond: Schaalt lineair slechts tot ~16 vCPU's; daarboven nemen doorvoerstijgingen af.
- Multimodale beperkingen: Ondersteunt beeld- en audio-inputs maar met beperkte nauwkeurigheid; niet ideaal voor zware beeld- of audiotranscriptietaken.
- Trade-off van het contextvenster : Hoewel het tot 1 M tokens accepteert, kan de praktische inferentie op die schaal een verminderde doorvoer vertonen.