

In het snel evoluerende landschap van kunstmatige intelligentie (AI) heeft 2025 aanzienlijke vooruitgang geboekt op het gebied van grote taalmodellen (LLM's). Tot de koplopers behoren Alibaba's Qwen2.5, DeepSeek's V3- en R1-modellen en OpenAI's ChatGPT. Elk van deze modellen biedt unieke mogelijkheden en innovaties. Dit artikel verdiept zich in de nieuwste ontwikkelingen rond Qwen2.5 en vergelijkt de functies en prestaties ervan met DeepSeek en ChatGPT om te bepalen welk model momenteel de AI-race aanvoert.
Wat is Qwen2.5?
Overzicht
Qwen 2.5 is Alibaba Cloud's nieuwste compacte, decoder-only grote taalmodel, beschikbaar in verschillende groottes variërend van 0.5B tot 72B parameters. Het is geoptimaliseerd voor instructievolging, gestructureerde output (bijv. JSON, tabellen), codering en wiskundige probleemoplossing. Met ondersteuning voor meer dan 29 talen en een contextlengte tot 128K tokens is Qwen2.5 ontworpen voor meertalige en domeinspecifieke toepassingen.
BELANGRIJKSTE KENMERKEN
- Meertalige ondersteuning: Ondersteunt meer dan 29 talen en is geschikt voor gebruikers over de hele wereld.
- Uitgebreide contextlengte: Verwerkt maximaal 128 tokens, waardoor lange documenten en gesprekken verwerkt kunnen worden.
- Gespecialiseerde varianten:Omvat modellen zoals Qwen2.5-Coder voor programmeertaken en Qwen2.5-Math voor wiskundige probleemoplossing.
- Toegankelijkheid: Beschikbaar via platforms zoals Hugging Face, GitHub en een onlangs gelanceerde webinterface op chat.qwenlm.ai.
Hoe kan ik Qwen 2.5 lokaal gebruiken?
Hieronder vindt u een stapsgewijze handleiding voor de 7 B Chat controlepunt; grotere formaten verschillen alleen in GPU-vereisten.
1. Hardwarevereisten
| Model | vRAM voor 8-bits | vRAM voor 4-bits (QLoRA) | Schijfgrootte |
|---|---|---|---|
| Qwen 2.5‑7B | 14GB | 10GB | 13GB |
| Qwen 2.5‑14B | 26GB | 18GB | 25GB |
Eén RTX 4090 (24 GB) is voldoende voor 7 B-inferentie met volledige 16-bits precisie; twee van dergelijke kaarten of CPU-offload plus kwantificering kunnen 14 B aan.
2. Installatie
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Snel inferentiescript
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
Het trust_remote_code=True vlag is vereist omdat Qwen een op maat gemaakte Rotatieve positie-inbedding wikkel.
4. Finetuning met LoRA
Dankzij parameter-efficiënte LoRA-adapters kunt u Qwen in minder dan vier uur op een enkele 50 GB GPU trainen op ~24 K domeinparen (bijvoorbeeld medisch):
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Het resulterende adapterbestand (~120 MB) kan op verzoek worden samengevoegd of geladen.
Optioneel: voer Qwen 2.5 uit als een API
CometAPI fungeert als een gecentraliseerde hub voor API's van verschillende toonaangevende AI-modellen, waardoor het niet nodig is om afzonderlijk met meerdere API-providers samen te werken. KomeetAPI Biedt een prijs die veel lager is dan de officiële prijs om u te helpen de Qwen API te integreren. U ontvangt $ 1 op uw account na registratie en inloggen! Welkom bij CometAPI en ervaar het zelf. Voor ontwikkelaars die Qwen 2.5 in applicaties willen integreren:
Stap 1: Installeer de benodigde bibliotheken:
bash
pip install requests
Stap 2: API-sleutel verkrijgen
- Navigeer naar KomeetAPI.
- Meld u aan met uw CometAPI-account.
- Selecteer het Overzicht.
- Klik op ‘API-sleutel ophalen’ en volg de instructies om uw sleutel te genereren.
Stap 3: API-aanroepen implementeren
Gebruik de API-referenties om verzoeken te doen aan Qwen 2.5.Vervangen met uw werkelijke CometAPI-sleutel van uw account.
Bijvoorbeeld in Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Deze integratie zorgt voor een naadloze integratie van de mogelijkheden van Qwen 2.5 in verschillende applicaties, waardoor de functionaliteit en gebruikerservaring worden verbeterd. Selecteer de “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” eindpunt om de API-aanvraag te versturen en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak.
Raadpleeg Qwen 2.5 Maximale API voor integratiedetails. CometAPI heeft de laatste bijgewerkt QwQ-32B-APIVoor meer informatie over het model in de Comet API, zie API-document.
Best practices en tips
| Scenario | Aanbeveling |
|---|---|
| Vragen en antwoorden over lange documenten | Verdeel passages in tokens van ≤16 K en gebruik prompts met verbeterde retrieval in plaats van naïeve contexten van 100 K om de latentie te verminderen. |
| Gestructureerde uitgangen | Voeg het systeembericht toe als voorvoegsel: You are an AI that strictly outputs JSON. De uitlijningstraining van Qwen 2.5 blinkt uit in beperkte generatie. |
| Code aanvulling | Set temperature=0.0 en top_p=1.0 om het determinisme te maximaliseren, bemonster dan meerdere balken (num_return_sequences=4) voor rangschikking. |
| Veiligheidsfiltering | Gebruik als eerste stap Alibaba's open-source "Qwen-Guardrails" regex-bundel of OpenAI's text-moderation-004. |
Bekende beperkingen van Qwen 2.5
- Gevoeligheid voor snelle injectie. Uit externe audits blijkt dat de Qwen 18‑VL een succespercentage van 2.5% heeft bij jailbreaken. Dit toont aan dat de omvang van het model alleen niet immuun is voor vijandige instructies.
- Niet-Latijnse OCR-ruis. Bij het verfijnen van het model voor taken met betrekking tot visuele taal kan het voorkomen dat de end-to-end-pijplijn van het model traditionele en vereenvoudigde Chinese tekens met elkaar verwart, waardoor domeinspecifieke correctielagen nodig zijn.
- GPU-geheugenlimiet van 128 K. FlashAttention‑2 compenseert RAM, maar een 72 B dense forward pass over 128 K tokens vereist nog steeds >120 GB vRAM; beoefenaars zouden window‑attend of KV‑cachen moeten gebruiken.
Routekaart en community-ecosysteem
Het Qwen-team heeft gezinspeeld op Qwen 3.0, gericht op een hybride routeringsbackbone (Dense + MoE) en een uniforme spraak-, beeld- en tekstvoortraining. Het ecosysteem biedt inmiddels al:
- Q‑Agent – een ReAct-stijl gedachtenketenagent die Qwen 2.5-14B als beleid gebruikt.
- Chinese financiële alpaca – een LoRA op Qwen2.5‑7B getraind met 1 miljoen regelgevende indieningen.
- Open Interpreter-plug-in – ruilt GPT‑4 in voor een lokaal Qwen-controlepunt in VS Code.
Bekijk de Hugging Face-pagina “Qwen2.5-collectie” voor een continu bijgewerkte lijst met controlepunten, adapters en evaluatieharnassen.
Vergelijkende analyse: Qwen2.5 versus DeepSeek en ChatGPT
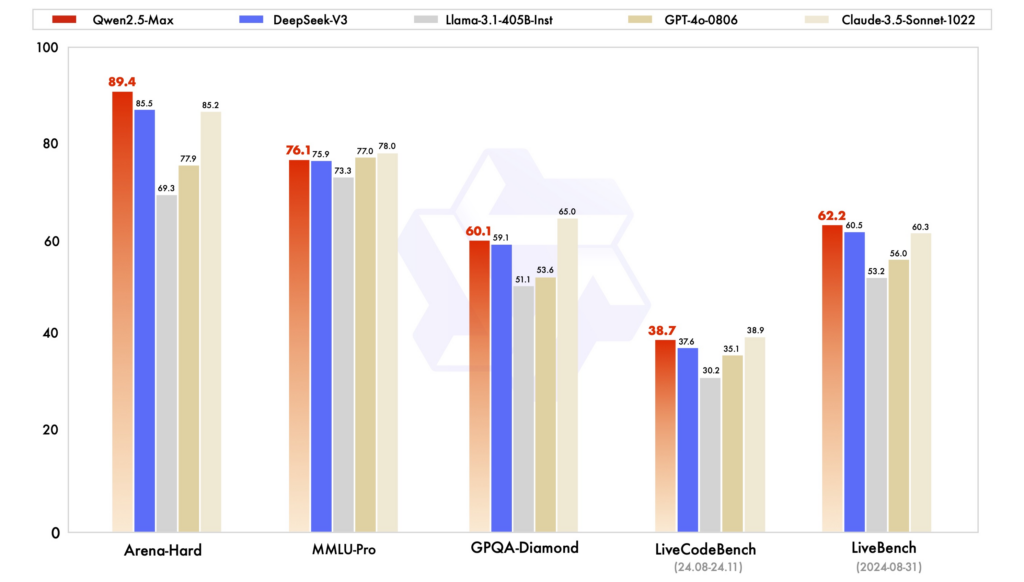
Prestatiebenchmarks: In diverse evaluaties heeft Qwen2.5 sterke prestaties laten zien in taken die redeneren, coderen en meertalig begrip vereisen. DeepSeek-V3, met zijn MoE-architectuur, blinkt uit in efficiëntie en schaalbaarheid en levert hoge prestaties met beperkte rekenkracht. ChatGPT blijft een robuust model, met name voor algemene taaltaken.
Efficiëntie en kosten: De modellen van DeepSeek staan bekend om hun kosteneffectieve training en inferentie, waarbij gebruik wordt gemaakt van MoE-architecturen om alleen de benodigde parameters per token te activeren. Qwen2.5 is weliswaar compact, maar biedt gespecialiseerde varianten om de prestaties voor specifieke taken te optimaliseren. De training van ChatGPT vereiste aanzienlijke rekenkracht, wat tot uiting kwam in de operationele kosten.
Toegankelijkheid en open-source beschikbaarheid: Qwen2.5 en DeepSeek hebben open-sourceprincipes in verschillende mate omarmd, met modellen die beschikbaar zijn op platforms zoals GitHub en Hugging Face. De recente lancering van een webinterface voor Qwen2.5 verbetert de toegankelijkheid. ChatGPT is weliswaar niet open-source, maar wel breed toegankelijk via het platform en de integraties van OpenAI.
Conclusie
Qwen 2.5 bevindt zich op een ideale plek tussen gesloten gewicht premiediensten en volledig open hobbymodellenDe combinatie van permissieve licenties, meertalige kracht, lange-contextcompetentie en een breed scala aan parameterschalen maakt het een overtuigende basis voor zowel onderzoek als productie.
Terwijl het open-source LLM-landschap razendsnel vooruitgaat, toont het Qwen-project aan dat transparantie en prestatie kunnen naast elkaar bestaanVoor ontwikkelaars, datawetenschappers en beleidsmakers is het beheersen van Qwen 2.5 vandaag al een investering in een meer pluralistische, innovatievriendelijke AI-toekomst.