

Alibaba's nieuwste vooruitgang op het gebied van kunstmatige intelligentie, Qwen3-codeerder, markeert een belangrijke mijlpaal in het snel evoluerende landschap van AI-gestuurde softwareontwikkeling. Qwen23-Coder, onthuld op 2025 juli 3, is een open-source, agentisch coderingsmodel dat is ontworpen om complexe programmeertaken autonoom uit te voeren, van het genereren van boilerplate-code tot het debuggen van complete codebases. Gebouwd op een geavanceerde mix van experts (MoE)-architectuur en met 480 miljard parameters, waarvan er 35 miljard per token zijn geactiveerd, bereikt het model een optimale balans tussen prestaties en rekenefficiëntie. In dit artikel onderzoeken we wat Qwen3-Coder onderscheidt, onderzoeken we de benchmarkprestaties, ontleden we de technische innovaties, begeleiden we ontwikkelaars bij optimaal gebruik en bespreken we de ontvangst en toekomstperspectieven van het model.
Wat is Qwen3‑Coder?
Qwen3-Coder is het nieuwste agentische codeermodel uit de Qwen-familie, officieel aangekondigd op 22 juli 2025. Ontworpen als een "meest agentische codemodel tot nu toe", beschikt de vlaggenschipvariant, Qwen3-Coder-480B-A35B-Instruct, over 480 miljard parameters in totaal met een Mixture-of-Experts (MoE)-ontwerp dat 35 miljard parameters per token activeert. Het ondersteunt native contextvensters tot 256 tokens en kan via extrapolatietechnieken worden opgeschaald tot een miljoen tokens, waarmee wordt voldaan aan de vraag naar codebegrip en -generatie op repo-schaal.
Open-source onder Apache 2.0
In lijn met Alibaba's toewijding aan community-gedreven ontwikkeling, wordt Qwen3-Coder uitgebracht onder de Apache 2.0-licentie. Deze open-source beschikbaarheid garandeert transparantie, stimuleert bijdragen van derden en versnelt de acceptatie in zowel de academische wereld als de industrie. Onderzoekers en engineers hebben toegang tot vooraf getrainde gewichten en kunnen het model verfijnen voor gespecialiseerde domeinen, van fintech tot wetenschappelijk computergebruik.
Evolutie van Qwen2.5
Voortbouwend op het succes van Qwen2.5-Coder, dat modellen bood met parameters variërend van 0.5 tot 32 miljard en SOTA-resultaten behaalde in benchmarks voor codegeneratie, breidt Qwen3-Coder de mogelijkheden van zijn voorganger uit met grootschaligere, verbeterde datapijplijnen en nieuwe trainingsregimes. Qwen2.5-Coder is getraind op meer dan 5.5 biljoen tokens met nauwgezette dataopschoning en synthetische datageneratie; Qwen3-Coder verbetert dit door 7.5 biljoen tokens te verwerken met een coderatio van 70%, waarbij gebruik wordt gemaakt van eerdere modellen om ruisige input te filteren en te herschrijven voor superieure datakwaliteit.
Wat zijn de belangrijkste innovaties die Qwen3-Coder onderscheiden?
Een aantal belangrijke innovaties onderscheiden Qwen3-Coder:
- Agentische taakorkestratie:In plaats van alleen maar fragmenten te genereren, kan Qwen3-Coder autonoom meerdere bewerkingen aan elkaar koppelen, zoals het lezen van documentatie, het aanroepen van hulpprogramma's en het valideren van uitvoer, zonder menselijke tussenkomst.
- Verbeterd Denkbudget:Ontwikkelaars kunnen configureren hoeveel rekenkracht er aan elke stap van het redeneren wordt besteed. Hierdoor is er een aanpasbare afweging mogelijk tussen snelheid en grondigheid, wat cruciaal is voor grootschalige codesynthese.
- Naadloze toolintegratie:De opdrachtregelinterface van Qwen3-Coder, "Qwen Code", past protocollen voor het aanroepen van functies en aangepaste prompts aan om te integreren met populaire ontwikkelaarstools. Hierdoor is het eenvoudig om deze te integreren in bestaande CI/CD-pijplijnen en IDE's.
Hoe presteert Qwen3‑Coder in vergelijking met concurrenten?
Benchmark-showdowns
Volgens de gepubliceerde prestatiegegevens van Alibaba presteert Qwen3-Coder beter dan toonaangevende binnenlandse alternatieven, zoals DeepSeeks codex-stijlmodellen en Moonshot AI's K2, en evenaart of overtreft het de codeercapaciteiten van toonaangevende Amerikaanse aanbieders in verschillende benchmarks. In externe evaluaties:
- Hulp Polyglot: Qwen3-Coder-480B behaalde een score van 61.8%, wat een krachtige meertalige codegeneratie en -redenering illustreert.
- MBPP en HumanEvalUit onafhankelijke tests blijkt dat de Qwen3-Coder-480B-A35B beter presteert dan GPT-4.1 op het gebied van zowel functionele correctheid als complexe promptverwerking, met name bij coderingsuitdagingen met meerdere stappen.
- De 480B-parametervariant behaalde een uitvoeringssucces van meer dan 85% op de SWE‑Bank Geverifieerde suite, die zowel DeepSeek's topmodel (78%) als Moonshot's K2 (82%) overtreft en nauw aansluit bij Claude Sonnet 4 met 86%.
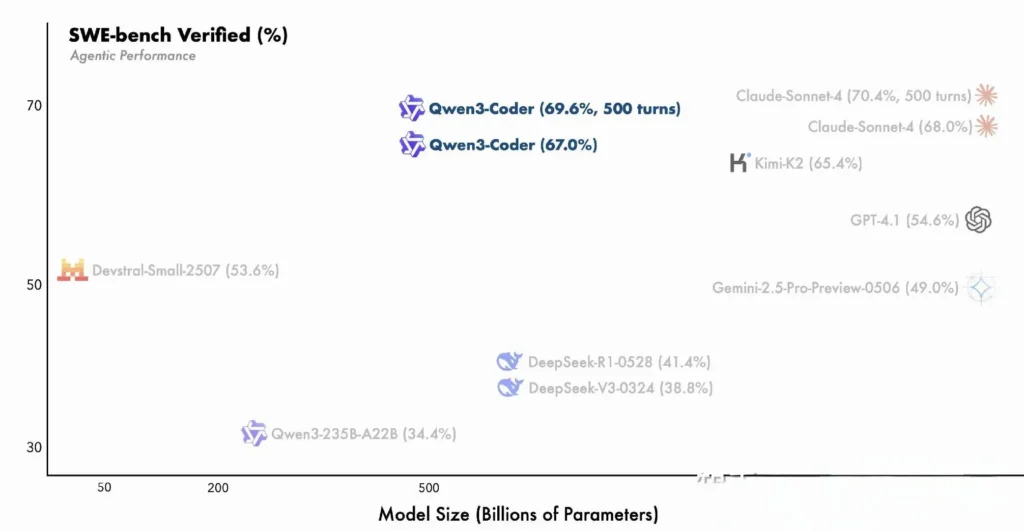
Vergelijking met eigen modellen
Alibaba beweert dat de agentische mogelijkheden van Qwen3-Coder aansluiten bij die van Anthropic's Claude en OpenAI's GPT-4 in end-to-end codeerworkflows, een opmerkelijke prestatie voor een open-sourcemodel. Vroege testers melden dat de multi-turn planning, dynamische toolaanroeping en automatische foutcorrectie complexe taken – zoals het bouwen van full-stack webapplicaties of het integreren van CI/CD-pipelines – aankunnen met minimale menselijke prompts. Deze mogelijkheden worden versterkt door het vermogen van het model om zichzelf te valideren door middel van code-uitvoering, een eigenschap die minder uitgesproken is in puur generatieve LLM's.
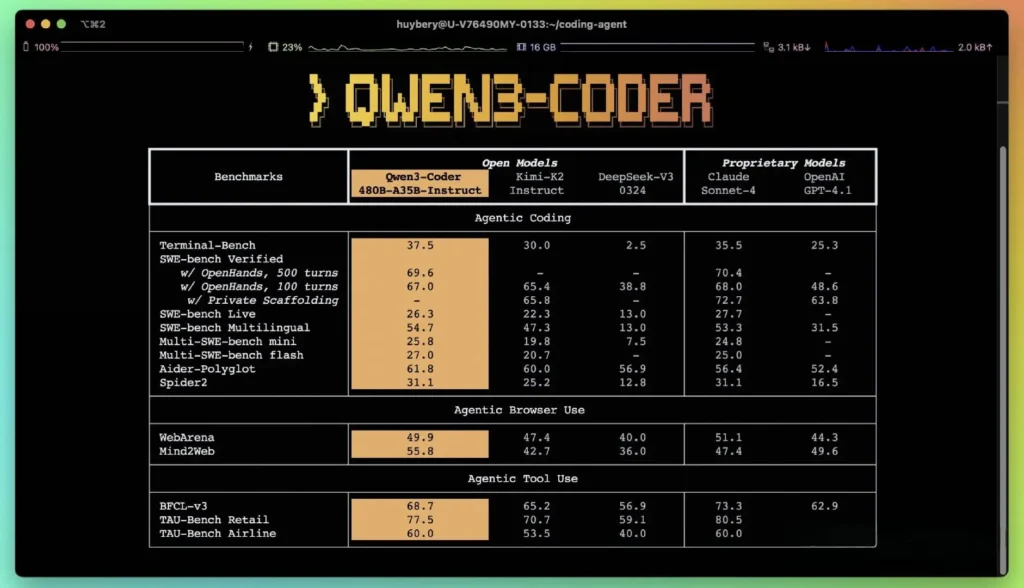
Wat zijn de technische innovaties achter Qwen3‑Coder?
Mixture-of-Experts (MoE)-architectuur
De kern van Qwen3-Coder wordt gevormd door een state-of-the-art MoE-ontwerp. In tegenstelling tot dichte modellen die alle parameters voor elk token activeren, schakelen MoE-architecturen selectief gespecialiseerde subnetwerken (experts) in die zijn afgestemd op specifieke tokentypen of taken. In Qwen3-Coder zijn in totaal 480 miljard parameters verdeeld over meerdere experts, met slechts 35 miljard actieve parameters per token. Deze aanpak verlaagt de inferentiekosten met meer dan 60% ten opzichte van vergelijkbare dichte modellen, terwijl de hoge betrouwbaarheid van codesynthese en debuggen behouden blijft.
Denkmodus en niet-denkenmodus
Door te lenen van de bredere innovaties van de Qwen3-familie, integreert Qwen3-Coder een dual-mode inferentie kader:
- Denkmodus kent een groter ‘denkbudget’ toe aan complexe, meerstaps redeneertaken zoals algoritmeontwerp of refactoring van meerdere bestanden.
- Niet-denkende modus Biedt snelle, contextgestuurde reacties die geschikt zijn voor eenvoudige codeaanvullingen en API-gebruiksfragmenten.
Dankzij deze uniforme modusschakeling hoeft u niet langer te jongleren met afzonderlijke modellen voor chat-geoptimaliseerde versus redeneer-geoptimaliseerde taken, waardoor de workflows van ontwikkelaars worden gestroomlijnd.
Reinforcement Learning met geautomatiseerde testcasesynthese
Een opvallende innovatie is Qwen3-Coder's native contextvenster van 256K tokens – twee keer de typische capaciteit van toonaangevende open modellen – en de ondersteuning voor maximaal een miljoen tokens via extrapolatiemethoden (bijvoorbeeld YaRN). Dit stelt het model in staat om complete repositories, documentatiesets of projecten met meerdere bestanden in één keer te verwerken, waardoor afhankelijkheden tussen bestanden behouden blijven en het aantal repetitieve prompts wordt verminderd. Empirische tests tonen aan dat uitbreiding van het contextvenster een afnemende, maar nog steeds zinvolle verbetering oplevert in de prestaties van taken met een lange horizon, met name in scenario's met omgevingsgestuurd reinforcement learning.
Hoe krijgen ontwikkelaars toegang tot Qwen3‑Coder en kunnen ze het gebruiken?
De releasestrategie voor Qwen3-Coder legt de nadruk op openheid en eenvoudige acceptatie:
- Open-source modelgewichten:Alle modelcontrolepunten zijn beschikbaar op GitHub onder Apache 2.0, wat volledige transparantie en door de community aangestuurde verbeteringen mogelijk maakt.
- Opdrachtregelinterface (Qwen-code):De CLI is afgeleid van Google Gemini Code en ondersteunt aangepaste prompts, functieaanroepen en plug-inarchitecturen voor naadloze integratie met bestaande buildsystemen en IDE's.
- Cloud- en on-prem-implementaties:Vooraf geconfigureerde Docker-images en Kubernetes Helm-grafieken maken schaalbare implementaties in cloudomgevingen mogelijk, terwijl lokale kwantificeringsrecepten (dynamische kwantificering van 2–8 bits) efficiënte on-premises inferentie mogelijk maken, zelfs op standaard GPU's.
- API-toegang via CometAPI:Ontwikkelaars kunnen ook met Qwen3-Coder communiceren via gehoste eindpunten op platforms zoals KomeetAPI, die open source aanbieden(
qwen3-coder-480b-a35b-instruct) en commerciële versies(qwen3-coder-plus; qwen3-coder-plus-2025-07-22) voor dezelfde prijs. De commerciële versie is 1M lang. - Gezicht knuffelen:Alibaba heeft de Qwen3‑Coder-gewichten en bijbehorende bibliotheken gratis beschikbaar gesteld op zowel Hugging Face als GitHub, verpakt onder een Apache 2.0-licentie die academisch en commercieel gebruik zonder royalty's toestaat.
API- en SDK-integratie via CometAPI
CometAPI is een uniform API-platform dat meer dan 500 AI-modellen van toonaangevende aanbieders – zoals de GPT-serie van OpenAI, Gemini van Google, Claude, Midjourney en Suno van Anthropic – samenvoegt in één, gebruiksvriendelijke interface voor ontwikkelaars. Door consistente authenticatie, aanvraagopmaak en responsverwerking te bieden, vereenvoudigt CometAPI de integratie van AI-mogelijkheden in uw applicaties aanzienlijk. Of u nu chatbots, beeldgenerators, muziekcomponisten of datagestuurde analysepipelines bouwt, met CometAPI kunt u sneller itereren, kosten beheersen en leveranciersonafhankelijk blijven – en tegelijkertijd profiteren van de nieuwste doorbraken in het AI-ecosysteem.
Ontwikkelaars kunnen interacteren met Qwen3-codeerder via een compatibele API in OpenAI-stijl, beschikbaar via CometAPI. KomeetAPI, die open source aanbieden(qwen3-coder-480b-a35b-instruct) en commerciële versies(qwen3-coder-plus; qwen3-coder-plus-2025-07-22) voor dezelfde prijs. De commerciële versie is 1M lang. Voorbeeldcode voor Python (met behulp van de OpenAI-compatibele client) met aanbevolen procedures voor bemonsteringsinstellingen van temperatuur = 0.7, top_p = 0.8, top_k = 20 en een herhalingsstraf = 1.05. De uitvoerlengte kan oplopen tot 65,536 tokens, waardoor het geschikt is voor grote codegeneratietaken.
Om te beginnen, verken de mogelijkheden van modellen in de Speeltuin en raadpleeg de API-gids voor gedetailleerde instructies. Zorg ervoor dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen voordat u toegang krijgt.
Snelstartgids voor Hugging Face en Alibaba Cloud
Ontwikkelaars die graag willen experimenteren met Qwen3‑Coder kunnen het model vinden op Hugging Face onder de repository Qwen/Qwen3‑Coder‑480B‑A35B‑InstructIntegratie wordt gestroomlijnd via de transformers bibliotheek (versie ≥ 4.51.0 om te voorkomen KeyError: 'qwen3_moe') en OpenAI-compatibele Python-clients. Een minimaal voorbeeld:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
Aangepaste tools en agent-workflows definiëren
Een van de opvallende kenmerken van Qwen3‑Coder is dynamische gereedschapsaanroepingOntwikkelaars kunnen externe hulpprogramma's registreren – linters, formatters, testrunners – en het model deze autonoom laten aanroepen tijdens een codeersessie. Deze mogelijkheid transformeert Qwen3-Coder van een passieve code-assistent in een actieve codeeragent, die tests kan uitvoeren, de codestijl kan aanpassen en zelfs microservices kan implementeren op basis van conversatie-intenties.
Welke potentiële toepassingen en toekomstige richtingen biedt Qwen3‑Coder?
Door de vrijheid van open source te combineren met prestaties op ondernemingsniveau, maakt Qwen3-Coder de weg vrij voor een nieuwe generatie AI-gestuurde ontwikkeltools. Van geautomatiseerde code-audits en compliancecontroles tot continue refactoring-services en AI-gestuurde ontwikkelassistenten: de veelzijdigheid van het model inspireert nu al zowel startups als interne innovatieteams.
Softwareontwikkelingsworkflows
Early adopters melden een tijdsbesparing van 30 tot 50 procent op boilerplate-codering, afhankelijkheidsbeheer en initiële scaffolding, waardoor engineers zich kunnen concentreren op waardevolle ontwerp- en architectuurtaken. Continue integratiesuites kunnen Qwen3-Coder gebruiken om automatisch tests te genereren, regressies te detecteren en zelfs prestatieoptimalisaties voor te stellen op basis van realtime codeanalyse.
Bedrijven spelen
Naarmate bedrijven in de financiële sector, de gezondheidszorg en e-commerce Qwen3-Coder integreren in bedrijfskritische systemen, zullen feedbackloops tussen gebruikersteams en Alibaba's R&D de verfijningen versnellen, zoals domeinspecifieke afstemming, verbeterde beveiligingsprotocollen en strengere IDE-plug-ins. Bovendien stimuleert Alibaba's open-sourcestrategie bijdragen van de wereldwijde community, wat een dynamisch ecosysteem van extensies, benchmarks en best-practice-bibliotheken bevordert.
Conclusie
Kortom, Qwen3-Coder vertegenwoordigt een mijlpaal in open-source AI voor software engineering: een krachtig, agentisch model dat niet alleen code schrijft, maar ook complete ontwikkeltrajecten orkestreert met minimale menselijke supervisie. Door de technologie gratis beschikbaar en eenvoudig te integreren te maken, democratiseert Alibaba de toegang tot geavanceerde AI-tools en legt het de basis voor een tijdperk waarin softwarecreatie steeds meer een samenwerkingsgerichte, efficiënte en intelligente aanpak vereist.
Veelgestelde vragen
Wat maakt Qwen3‑Coder ‘agentisch’?
Agentische AI verwijst naar modellen die autonoom meerstapstaken kunnen plannen en uitvoeren. De mogelijkheid van Qwen3-Coder om externe tools aan te roepen, tests uit te voeren en codebases te beheren zonder menselijke tussenkomst, is een voorbeeld van dit paradigma.
Is Qwen3‑Coder geschikt voor productiegebruik?
Hoewel Qwen3‑Coder uitstekende prestaties levert in benchmarks en praktijktests, moeten bedrijven domeinspecifieke evaluaties uitvoeren en beveiligingsmaatregelen (bijvoorbeeld pijplijnen voor uitvoerverificatie) implementeren voordat ze het in kritieke productieworkflows integreren.
Welke voordelen biedt de Mixture-of-Experts-architectuur ontwikkelaars?
MoE verlaagt de inferentiekosten door alleen relevante subnetwerken per token te activeren, wat snellere generatie en lagere rekenkosten mogelijk maakt. Deze efficiëntie is cruciaal voor het opschalen van AI-codeerassistenten in cloudomgevingen.