
Qwen3-Max-Preview is Alibaba's nieuwste vlaggenschip in de Qwen3-familie: een model met meer dan een biljoen parameters, een Mixture-of-Experts (MoE)-stijl met een ultralang contextvenster van 262 tokens, uitgebracht als preview voor gebruik in bedrijven/de cloud. Het richt zich op *diepgaand redeneren, het begrijpen van lange documenten, codering en agentische workflows.
Basisinformatie en hoofdkenmerken
- Naam / Label:
qwen3-max-preview(Instrueren). - Schaal: Meer dan 1 biljoen parameters (vlaggenschip met een biljoen parameters). Dit is de belangrijkste marketing-/statistische mijlpaal voor de release.
- Contextvenster: 262,144 tokens (ondersteunt zeer lange invoer en transcripties in meerdere bestanden).
- Modus(sen): Instructie-afgestemde “Instruct”-variant met ondersteuning voor het denken (opzettelijke gedachteketen) en niet-denkend snelle modi in de Qwen3-familie.
- Beschikbaarheid: Preview-toegang via Qwen-chat, Alibaba Cloud Model Studio (OpenAI-compatibele of DashScope-eindpunten) en routeringsproviders zoals KomeetAPI.
Technische details (architectuur en modi)
- architectuur: Qwen3-Max volgt de Qwen3-ontwerplijn die een mix van dicht + Mix van Experts (MoE) componenten in grotere varianten, plus technische keuzes om de inferentie-efficiëntie te optimaliseren voor zeer grote parameteraantallen.
- Denkmodus versus niet-denkmodus: De Qwen3-serie introduceerde een denkmodus (voor outputs in de stijl van een meerstapsgedachtenketen) en niet-denkende modus voor snellere, bondige antwoorden. Het platform stelt parameters beschikbaar om dit gedrag in of uit te schakelen.
- Contextcaching / prestatiefuncties: Model Studio-lijsten contextcache Ondersteuning voor grote verzoeken om de kosten voor herhaalde invoer te verminderen en de doorvoer bij herhaalde contexten te verbeteren.
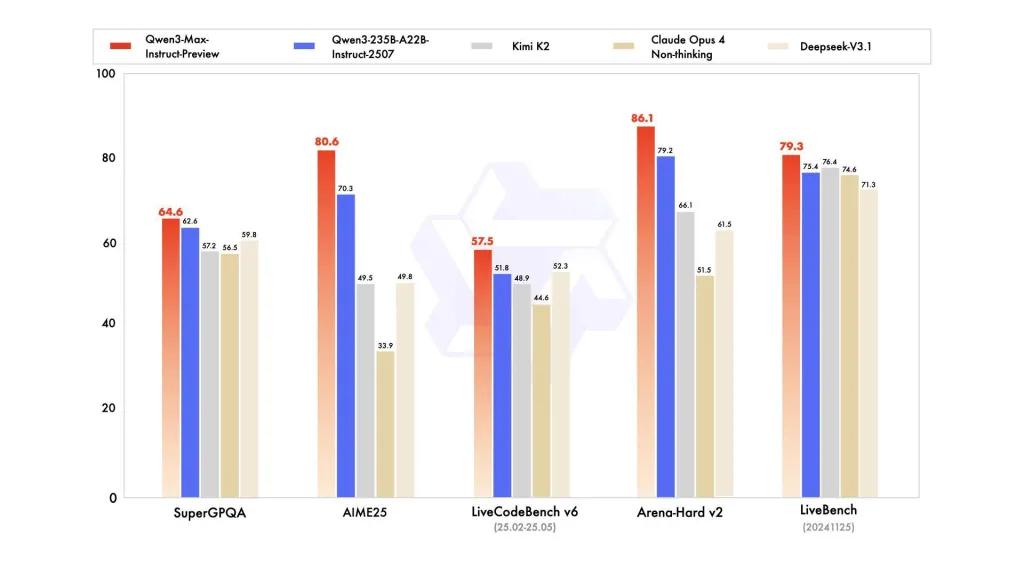
Benchmarkprestaties
Rapporten verwijzen naar SuperGPQA, LiveCodeBench-varianten, AIME25 en andere wedstrijd-/benchmarksuites waarin Qwen3-Max concurrerend of leidend lijkt.
Beperkingen en risico's (praktische en veiligheidsinstructies)
- Dekking voor volledig trainingsrecept / gewichten: Als preview kunnen de volledige trainings-/data-/gewichtsreleases en reproduceerbaarheidsmaterialen beperkt zijn in vergelijking met eerdere open-gewicht Qwen3-releases. Sommige Qwen3-familiemodellen zijn in open-gewicht uitgebracht, maar Qwen3-Max wordt geleverd als een gecontroleerde preview voor cloudtoegang. vermindert de reproduceerbaarheid voor onafhankelijke onderzoekers.
- Hallucinaties en feitelijkheid: Leveranciersrapporten beweren dat hallucinaties afnemen, maar in de praktijk zullen er nog steeds feitelijke onjuistheden en overmoedige beweringen te vinden zijn – de standaard LLM-waarschuwingen zijn van toepassing. Onafhankelijke evaluatie is noodzakelijk vóór implementatie met hoge risico's.
- Kosten op schaal: Met een enorm contextvenster en hoge capaciteit, tokenkosten Kan aanzienlijk zijn voor zeer lange prompts of productiedoorvoer. Gebruik caching, chunking en budgetcontroles.
- Overwegingen met betrekking tot regelgeving en datasoevereiniteit: Zakelijke gebruikers moeten de regio's van Alibaba Cloud, de locatie van gegevens en de nalevingsmaatregelen controleren voordat ze gevoelige informatie verwerken. (De documentatie van Model Studio bevat regiospecifieke eindpunten en opmerkingen.)
Use cases
- Documentbegrip/samenvatting op schaal: juridische documenten, technische specificaties en multi-file kennisbanken (voordeel: 262K-token raam).
- Redeneren met lange context en ondersteuning voor code op repository-schaal: inzicht in code voor meerdere bestanden, uitgebreide PR-beoordelingen, suggesties voor refactoring op repositoryniveau.
- Complexe redeneer- en gedachteketentaken: wiskundewedstrijden, planning in meerdere stappen, agentische workflows waarbij 'denkende' sporen de traceerbaarheid bevorderen.
- Meertalige vraag- en antwoordsessies voor bedrijven en gestructureerde gegevensextractie: ondersteuning voor grote meertalige corpora en gestructureerde uitvoermogelijkheden (JSON / tabellen).
Hoe de Qqwen3-max-preview API vanuit CometAPI aan te roepen
qwen3-max-preview API-prijzen in CometAPI, 20% korting op de officiële prijs:
| Invoertokens | $0.24 |
| Uitvoertokens | $2.42 |
Vereiste stappen
- Inloggen cometapi.com. Als u nog geen gebruiker van ons bent, registreer u dan eerst
- Haal de API-sleutel voor de toegangsgegevens van de interface op. Klik op 'Token toevoegen' bij de API-token in het persoonlijke centrum, haal de tokensleutel op: sk-xxxxx en verstuur.
- Haal de url van deze site op: https://api.cometapi.com/
Gebruik methode
- Selecteer het eindpunt "qwen3-max-preview" om de API-aanvraag te verzenden en de aanvraagbody in te stellen. De aanvraagmethode en de aanvraagbody zijn te vinden in de API-documentatie op onze website. Onze website biedt ook een Apifox-test voor uw gemak.
- Vervangen met uw werkelijke CometAPI-sleutel van uw account.
- Vul het inhoudsveld in en het model zal hierop reageren.
- Verwerk het API-antwoord om het gegenereerde antwoord te verkrijgen.
API-aanroep
CometAPI biedt een volledig compatibele REST API voor een naadloze migratie. Belangrijke details voor API-document:
- Kernparameters:
prompt,max_tokens_to_sample,temperature,stop_sequences - eindpunt:
https://api.cometapi.com/v1/chat/completions - Modelparameter: qwen3-max-preview
- authenticatie:
Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
vervangen
CometAPI_API_KEYmet uw sleutel; let op de basis-URL.
Python (verzoeken) — OpenAI-compatibel
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Tip: . max_input_tokens, max_output_tokensen Model Studio's contextcache functies bij het verzenden van zeer grote contexten om kosten en doorvoer te beheersen.
Zie ook Qwen3-codeerder