

Op 19 en 20 november 2025 bracht OpenAI twee gerelateerde maar verschillende upgrades uit: GPT-5.1-Codex-Max, een nieuw agentisch coderingsmodel voor Codex dat de nadruk legt op codering met een lange horizon, tokenefficiëntie en ‘compactie’ om sessies met meerdere vensters te ondersteunen; en GPT-5.1 Pro, een bijgewerkt Pro-tier ChatGPT-model dat is afgestemd op duidelijkere, krachtigere antwoorden bij complexe, professionele werkzaamheden.
Wat is GPT-5.1-Codex-Max en welk probleem probeert het op te lossen?
GPT-5.1-Codex-Max is een gespecialiseerd Codex-model van OpenAI, afgestemd op coderingsworkflows die aanhoudende, langetermijn redenering en uitvoeringWaar gewone modellen in de problemen kunnen komen door extreem lange contexten – bijvoorbeeld multi-file refactoring, complexe agent loops of persistente CI/CD-taken – is Codex-Max ontworpen om automatisch de sessiestatus comprimeren en beheren over meerdere contextvensters, waardoor het coherent kan blijven werken, aangezien één project vele duizenden (of meer) tokens omvat. OpenAI positioneert Codex-Max als de volgende stap in het daadwerkelijk bruikbaar maken van code-capabele agents voor uitgebreid engineeringwerk.
Wat is GPT-5.1-Codex-Max en welk probleem probeert het op te lossen?
GPT-5.1-Codex-Max is een gespecialiseerd Codex-model van OpenAI, afgestemd op coderingsworkflows die aanhoudende, langetermijn redenering en uitvoeringWaar gewone modellen in de problemen kunnen komen door extreem lange contexten – bijvoorbeeld multi-file refactoring, complexe agent loops of persistente CI/CD-taken – is Codex-Max ontworpen om automatisch de sessiestatus comprimeren en beheren over meerdere contextvensterswaardoor het samenhangend kan blijven werken, ook al omvat één project duizenden (of meer) tokens.
OpenAI beschrijft het als "sneller, intelligenter en token-efficiënter in elke fase van de ontwikkelingscyclus" en het is expliciet bedoeld om GPT-5.1-Codex te vervangen als standaardmodel in Codex-oppervlakken.
Momentopname van de functie
- Verdichting voor continuïteit tussen meerdere vensters: snoeit en behoudt kritieke context om coherent te werken gedurende miljoenen tokens en uren. 0
- Verbeterde tokenefficiëntie vergeleken met GPT-5.1-Codex: tot ~30% minder denktokens voor vergelijkbare redeneerinspanning in sommige codebenchmarks.
- Duurzaamheid van het agentium op lange termijn: intern waargenomen om agent-loops van meerdere uren/meerdere dagen te ondersteunen (OpenAI documenteerde interne runs van >24 uur).
- Platformintegraties: Vanaf vandaag beschikbaar in Codex CLI, IDE-extensies, de cloud en codebeoordelingstools; API-toegang volgt binnenkort.
- Ondersteuning voor Windows-omgevingen: OpenAI geeft specifiek aan dat Windows voor het eerst wordt ondersteund in Codex-workflows, waardoor ontwikkelaars in de praktijk meer mogelijkheden krijgen.
Hoe verhoudt het zich tot concurrerende producten (bijv. GitHub Copilot en andere coderende AI's)?
GPT-5.1-Codex-Max wordt gepresenteerd als een autonomere, langetermijn-samenwerker in vergelijking met tools voor voltooiing per aanvraag. Hoewel Copilot en vergelijkbare assistenten uitblinken in voltooiingen op korte termijn binnen de editor, liggen de sterke punten van Codex-Max in het orkestreren van taken met meerdere stappen, het handhaven van een coherente status tussen sessies en het afhandelen van workflows die planning, testen en iteratie vereisen. Desondanks zal de beste aanpak voor de meeste teams een hybride aanpak zijn: gebruik Codex-Max voor complexe automatisering en langdurige agenttaken en gebruik lichtere assistenten voor voltooiingen op regelniveau.
Hoe werkt GPT-5.1-Codex-Max?
Wat is ‘verdichting’ en hoe maakt het langdurig werk mogelijk?
Een centrale technische vooruitgang is verdichting—een intern mechanisme dat de sessiegeschiedenis snoeit, terwijl de belangrijkste contextuele elementen behouden blijven, zodat het model coherent werk kan blijven verrichten meervoudig Contextvensters. In de praktijk betekent dit dat Codex-sessies die hun contextlimiet naderen, worden gecomprimeerd (oudere tokens of tokens met een lagere waarde worden samengevat/bewaard), zodat de agent een nieuw venster heeft en herhaaldelijk kan blijven itereren totdat de taak is voltooid. OpenAI rapporteert interne runs waarbij het model meer dan 24 uur onafgebroken aan taken heeft gewerkt.
Adaptief redeneren en token-efficiëntie
GPT-5.1-Codex-Max maakt gebruik van verbeterde redeneerstrategieën die het token-efficiënter maken: in de gerapporteerde interne benchmarks van OpenAI behaalt het Max-model vergelijkbare of betere prestaties dan GPT-5.1-Codex, terwijl er aanzienlijk minder 'denkende' tokens worden gebruikt. OpenAI citeert ongeveer 30% minder Denktokens op SWE-bench geverifieerd bij gebruik met gelijke redeneerinspanning. Het model introduceert ook een "Extra Hoge (xhigh)" redeneerinspanningsmodus voor taken die niet gevoelig zijn voor latentie, waardoor er meer interne redenering nodig is om output van hogere kwaliteit te verkrijgen.
Systeemintegraties en agentische tooling
Codex-Max wordt gedistribueerd binnen Codex-workflows (CLI, IDE-extensies, cloud en code review-omgevingen) zodat het kan communiceren met daadwerkelijke toolchains voor ontwikkelaars. De eerste integraties omvatten de Codex CLI en IDE-agents (VS Code, JetBrains, enz.), met API-toegang die binnenkort beschikbaar zal zijn. Het ontwerpdoel is niet alleen slimmere codesynthese, maar ook een AI die workflows met meerdere stappen kan uitvoeren: bestanden openen, tests uitvoeren, fouten verhelpen, refactoren en opnieuw uitvoeren.
Hoe presteert GPT-5.1-Codex-Max in benchmarks en in de praktijk?
Volgehouden redenering en taken met een lange horizon
Uit evaluaties blijkt dat er meetbare verbeteringen zijn in duurzaam redeneren en taken met een lange horizon:
- Interne evaluaties van OpenAI: Codex-Max kan "meer dan 24 uur" aan taken werken in interne experimenten en de integratie van Codex met ontwikkelaarstools verhoogde de interne productiviteitscijfers van engineers (bijv. gebruik en pull-request-doorvoer). Dit zijn interne beweringen van OpenAI en duiden op verbeteringen op taakniveau in de productiviteit in de praktijk.
- Onafhankelijke evaluaties (METR): Het onafhankelijke rapport van METR heeft de waargenomen 50% tijdshorizon (een statistiek die de mediane tijd weergeeft waarin het model een lange taak coherent kan volhouden) voor GPT-5.1-Codex-Max bij ongeveer 2 uur 40 minuten (met een breed betrouwbaarheidsinterval), een stijging ten opzichte van de 2 uur en 17 minuten van GPT-5 in vergelijkbare metingen – een betekenisvolle, trendmatige verbetering in aanhoudende coherentie. De methodologie en betrouwbaarheidsinterval van METR benadrukken variabiliteit, maar het resultaat ondersteunt de theorie dat Codex-Max de praktische prestaties op lange termijn verbetert.
Code-benchmarks
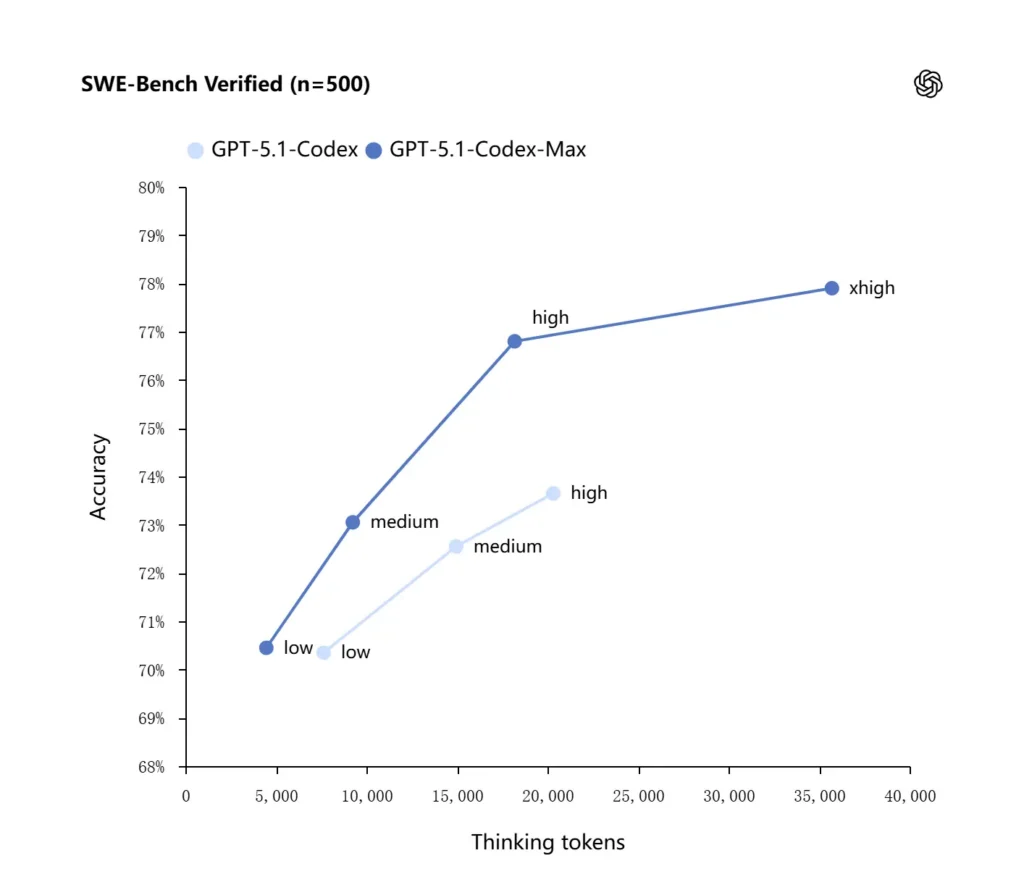
OpenAI rapporteert verbeterde resultaten bij evaluaties van frontier-coding, met name SWE-bench Verified, waar GPT-5.1-Codex-Max GPT-5.1-Codex overtreft met een hogere tokenefficiëntie. Het bedrijf benadrukt dat het Max-model voor dezelfde "gemiddelde" redeneerinspanning betere resultaten oplevert met ongeveer 30% minder denktokens; voor gebruikers die langere interne redeneringen toestaan, kan de xhigh-modus de antwoorden verder verbeteren, ten koste van de latentie.
| GPT‑5.1-Codex (hoog) | GPT‑5.1-Codex-Max (xhoog) | |
| SWE-bench geverifieerd (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
Hoe verhoudt GPT-5.1-Codex-Max zich tot GPT-5.1-Codex?
Prestatie- en doelverschillen
- Domein: GPT-5.1-Codex was een hoogwaardige coderingsvariant van de GPT-5.1-familie; Codex-Max is expliciet een agentische opvolger met een lange horizon die bedoeld is als aanbevolen standaard voor Codex en Codex-achtige omgevingen.
- Token efficiëntie: Codex-Max laat een toename in de efficiëntie van materiële tokens zien (OpenAI claimt dat er ~30% minder denktokens zijn) op de SWE-bench en in intern gebruik.
- Contextbeheer: Codex-Max introduceert compactie en native multi-window afhandeling ter ondersteuning van taken die groter zijn dan één contextvenster. Codex bood deze functionaliteit standaard niet op dezelfde schaal.
- Gereedschapsgereedheid: Codex-Max wordt geleverd als het standaard Codex-model voor de CLI, IDE en codebeoordelingsomgevingen, wat een migratie voor workflows voor productieontwikkelaars aangeeft.
Wanneer welk model gebruiken?
- Gebruik GPT-5.1-Codex voor interactieve coderingshulp, snelle bewerkingen, kleine refactoringen en use cases met lagere latentie waarbij de volledige relevante context gemakkelijk in één venster past.
- Gebruik GPT-5.1-Codex-Max voor multi-file refactorings, geautomatiseerde agentische taken die veel iteratiecycli vereisen, CI/CD-achtige workflows of wanneer u wilt dat het model een projectperspectief behoudt voor veel interacties.
Praktische opdrachtpatronen en voorbeelden voor het beste resultaat?
Patronen aanwijzen die goed werken
- Wees expliciet over doelen en beperkingen: “Refactor X, behoud de openbare API, behoud de functienamen en zorg ervoor dat tests A, B en C slagen.”
- Zorg voor minimaal reproduceerbare context: Link naar de mislukte test, voeg stack traces en relevante bestandsfragmenten toe in plaats van hele repositories te dumpen. Codex-Max comprimeert de geschiedenis indien nodig.
- Gebruik stapsgewijze instructies voor complexe taken: grote taken opsplitsen in een reeks subtaken en Codex-Max erdoorheen laten itereren (bijv. “1) tests uitvoeren 2) de 3 meest falende tests oplossen 3) linter uitvoeren 4) wijzigingen samenvatten”).
- Vraag om uitleg en verschillen: Vraag zowel de patch als een korte toelichting aan, zodat menselijke beoordelaars snel de veiligheid en bedoeling kunnen beoordelen.
Voorbeeldpromptsjablonen
Refactor-taak
“Refactor de
payment/module om betalingsverwerking in te zettenpayment/processor.pyHoud openbare functiehandtekeningen stabiel voor bestaande bellers. Maak unittests voorprocess_payment()die succes, netwerkstoringen en ongeldige kaarten dekken. Voer de testsuite uit en retourneer falende tests en een patch in uniform diff-formaat.
Bugfix + test
“Een test
tests/test_user_auth.py::test_token_refreshmislukt met traceback . Onderzoek de hoofdoorzaak, stel een oplossing voor met minimale wijzigingen en voeg een unittest toe om regressie te voorkomen. Pas de patch toe en voer tests uit.”
Iteratieve PR-generatie
“Implementeer feature X: voeg eindpunt toe
POST /api/exportdie resultaten exporteert en geauthenticeerd is. Maak het eindpunt aan, voeg documenten toe, maak tests aan en open een PR met een samenvatting en checklist van handmatige items.
Voor de meeste hiervan begint u met Medium inspanning; overschakelen naar xhoog wanneer u het model nodig hebt om diepgaande redeneringen uit te voeren over meerdere bestanden en meerdere testiteraties.
Hoe krijg je toegang tot GPT-5.1-Codex-Max?
Waar het vandaag beschikbaar is
OpenAI heeft GPT-5.1-Codex-Max geïntegreerd in Codex-gereedschap Vandaag: de Codex CLI, IDE-extensies, cloud en codereview-flows gebruiken standaard Codex-Max (u kunt kiezen voor Codex-Mini). De API-beschikbaarheid moet nog worden voorbereid; GitHub Copilot biedt openbare previews aan, waaronder GPT-5.1- en Codex-seriemodellen.
Ontwikkelaars hebben toegang tot GPT-5.1-Codex-Max en GPT-5.1-Codex API via CometAPI. Om te beginnen, verken de modelmogelijkheden vanKomeetAPI in de Speeltuin en raadpleeg de API-handleiding voor gedetailleerde instructies. Voordat u toegang krijgt, moet u ervoor zorgen dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen. cometAPI bieden een prijs die veel lager is dan de officiële prijs om u te helpen integreren.
Klaar om te gaan?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!
Snelle start (praktische stap-voor-stap)
- Zorg ervoor dat u toegang hebt: Bevestig dat uw ChatGPT/Codex-productabonnement (Plus, Pro, Business, Edu, Enterprise) of uw API-abonnement voor ontwikkelaars GPT-5.1/Codex-familiemodellen ondersteunt.
- Installeer Codex CLI of IDE-extensie: Als u codetaken lokaal wilt uitvoeren, installeert u de Codex CLI of de Codex IDE-extensie voor VS Code / JetBrains / Xcode, indien van toepassing. De tooling is standaard ingesteld op GPT-5.1-Codex-Max in ondersteunde configuraties.
- Kies redeneerinspanning: beginnen met Medium inspanning voor de meeste taken. Voor diepgaand debuggen, complexe refactorings, of wanneer u wilt dat het model harder nadenkt en u de responslatentie niet belangrijk vindt, schakelt u over naar hoog or xhoog modi. Voor snelle kleine reparaties, lage is redelijk.
- Geef repositorycontext: Geef het model een duidelijk startpunt: een repository-URL of een set bestanden en een korte instructie (bijvoorbeeld: "refactor de betalingsmodule om asynchrone I/O te gebruiken en voeg unittests toe, behoud contracten op functieniveau"). Codex-Max comprimeert de geschiedenis naarmate de contextlimieten naderen en zet de taak voort.
- Herhaal met testen: Nadat het model patches heeft geproduceerd, voer je testsuites uit en geef je fouten terug als onderdeel van de lopende sessie. Compactie en multi-window continuïteit zorgen ervoor dat Codex-Max belangrijke falende testcontext behoudt en itereert.
Conclusie:
GPT-5.1-Codex-Max is een substantiële stap in de richting van agentische coderingsassistenten die complexe, langlopende technische taken met verbeterde efficiëntie en redenering kunnen uitvoeren. De technische vooruitgang (compactie, redeneerinspanningsmodi, training in de Windows-omgeving) maakt het uitermate geschikt voor moderne technische organisaties – mits teams het model combineren met conservatieve operationele controles, duidelijke beleidsregels voor menselijke betrokkenheid en robuuste monitoring. Voor teams die het zorgvuldig implementeren, heeft Codex-Max de potentie om de manier waarop software wordt ontworpen, getest en onderhouden te veranderen – waardoor repetitief technisch werk verandert in een waardevollere samenwerking tussen mens en model.