

В ландшафте, доминируемом философией «масштабировать любой ценой» — где модели вроде Flux.2 и Hunyuan-Image-3.0 доводят число параметров до колоссальных 30–80 млрд — появился новый претендент, способный изменить статус-кво. Z-Image, разработанная лабораторией Tongyi Alibaba, официально представлена и разрушает ожидания благодаря компактной архитектуре на 6 млрд параметров, сопоставимой по качеству с индустриальными гигантами, при этом работая на потребительском оборудовании.
Выпущенная в конце 2025 года, Z-Image (и её сверхбыстрый вариант Z-Image-Turbo) мгновенно завоевала внимание сообщества ИИ, превысив 500,000 downloads в течение 24 часов после дебюта. Генерируя фотореалистичные изображения всего за 8 inference steps, Z-Image — это не просто модель; это демократизирующая сила в генеративном ИИ, позволяющая создавать изображения высокого качества на ноутбуках, которые «задыхались бы» на конкурентах.
What is Z-Image?
Z-Image — это новый, открытый базовый генеративный модельный стек для создания изображений, разработанный исследовательской командой Tongyi-MAI / Alibaba Tongyi Lab. Это генеративная модель на 6 млрд параметров, построенная на новой архитектуре Scalable Single-Stream Diffusion Transformer (S3-DiT), которая конкатенирует текстовые токены, визуальные семантические токены и токены VAE в единый поток обработки. Цель дизайна очевидна: обеспечить топовый фотореализм и следование инструкциям при резком снижении стоимости инференса и возможности практического применения на потребительском оборудовании. Проект Z-Image публикует код, веса модели и онлайн-демо под лицензией Apache-2.0.
Z-Image поставляется в нескольких вариантах. Самый обсуждаемый релиз — Z-Image-Turbo — дистиллированная, мало-шаговая версия, оптимизированная для деплоя, плюс недистиллированная Z-Image-Base (фундаментальная контрольная точка, лучше подходит для дообучения) и Z-Image-Edit (настроенная по инструкциям для редактирования изображений).
The "Turbo" Advantage: 8-Step Inference
Флагманский вариант, Z-Image-Turbo, использует прогрессивную технику дистилляции под названием Decoupled-DMD (Distribution Matching Distillation). Это позволяет сжать процесс генерации со стандартных 30–50 шагов до всего 8 steps.
Result: Субсекундные времена генерации на корпоративных GPU (H800) и практически реальное время на потребительских картах (RTX 4090), без «пластикового» или «выцветшего» вида, типичного для других turbo/lightning-моделей.
4 Key Features of Z-Image
Z-Image наполнена функциями, которые подходят как техническим разработчикам, так и креативным профессионалам.
1. Unmatched Photorealism & Aesthetics
Несмотря на всего 6 млрд параметров, Z-Image создаёт изображения поразительной ясности. Она превосходит в:
- Skin Texture: Воспроизведении пор, несовершенств и естественного освещения на человеческих субъектах.
- Material Physics: Точном рендеринге стекла, металла и фактур ткани.
- Lighting: Лучшей обработке кинематографического и объёмного освещения по сравнению с SDXL.
2. Native Bilingual Text Rendering
Одной из самых значимых проблем в генерации изображений ИИ был рендеринг текста. Z-Image решает её благодаря нативной поддержке both English and Chinese.
- Она может генерировать сложные постеры, логотипы и вывески с корректным правописанием и каллиграфией на обоих языках — возможности, которой часто нет в западно-центристских моделях.
3. Z-Image-Edit: Instruction-Based Editing
Вместе с базовой моделью команда выпустила Z-Image-Edit. Этот вариант дообучен для задач image-to-image, позволяя пользователям модифицировать существующие изображения с помощью инструкций на естественном языке (например, «Сделай человека улыбающимся», «Измени фон на снежную гору»). Он сохраняет высокую согласованность идентичности и освещения в этих трансформациях.
4. Consumer Hardware Accessibility
- VRAM Efficiency: Комфортно работает на 6GB VRAM (с квантованием) до 16GB VRAM (полная точность).
- Local Execution: Полностью поддерживает локальный деплой через ComfyUI и
diffusers, освобождая пользователей от зависимости от облака.
How does Z-Image Work?
Single-stream diffusion transformer (S3-DiT)
Z-Image уходит от классических двухпоточных дизайнов (отдельные кодировщики/потоки для текста и изображения) и вместо этого конкатенирует текстовые токены, токены VAE изображений и визуальные семантические токены в единый вход трансформера. Такой single-stream подход улучшает использование параметров и упрощает кросс-модальную согласованность внутри бэкбона трансформера, что, по словам авторов, даёт выгодный баланс эффективности/качества для модели на 6 млрд параметров.
Decoupled-DMD and DMDR (distillation + RL)
Чтобы обеспечить генерацию за малое количество шагов (8 шагов) без обычной потери качества, команда разработала подход дистилляции Decoupled-DMD. Техника разделяет усиление CFG (classifier-free guidance) и согласование распределений, позволяя оптимизировать их независимо. Затем применяется этап пост-тренировочного обучения с подкреплением (DMDR) для улучшения семантической согласованности и эстетики. В совокупности это даёт Z-Image-Turbo с значительно меньшим числом NFEs, чем у типичных диффузионных моделей, при сохранении высокой реалистичности.
Training throughput and cost optimisation
Z-Image обучалась с подходом оптимизации полного жизненного цикла: курируемые пайплайны данных, упрощённый учебный план и ориентированные на эффективность инженерные решения. Авторы сообщают о завершении полного цикла обучения примерно за 314K H800 GPU hours (≈ USD $630K) — явная, воспроизводимая инженерная метрика, которая позиционирует модель как более экономичную по сравнению с очень крупными альтернативами (>20B).
Benchmark Results of the Z-Image Model
Z-Image-Turbo заняла высокие позиции на нескольких современных лидербордах, включая топовую открыто-исходную позицию на Artificial Analysis Text-to-Image и сильные результаты на оценках предпочтений пользователей Alibaba AI Arena.
Но реальное качество также зависит от формулировки промпта, разрешения, пайплайна апскейлинга и дополнительной пост-обработки.
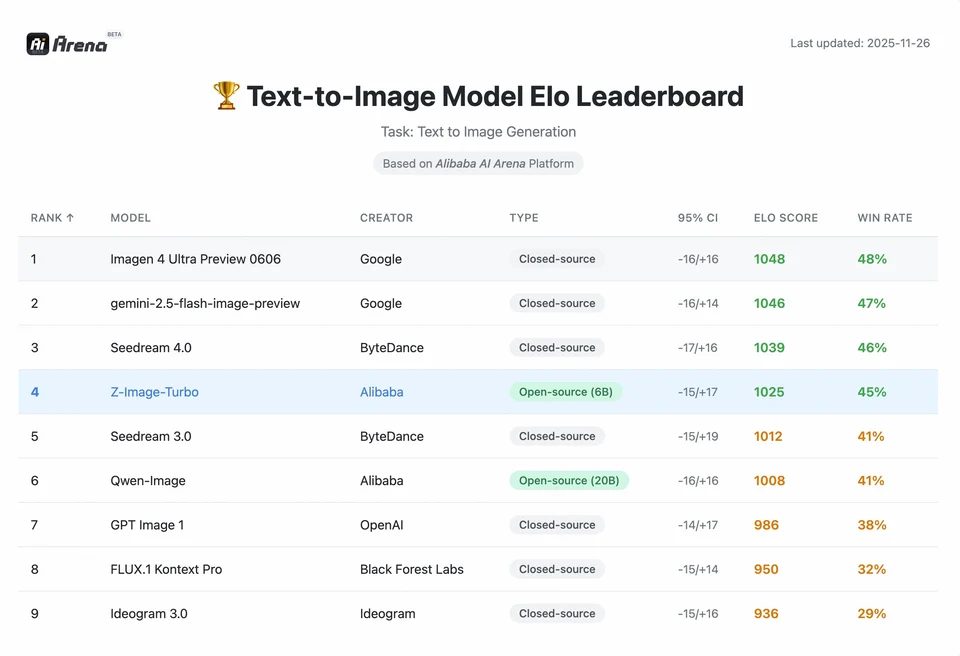
Чтобы понять масштабы достижения Z-Image, нужно посмотреть на данные. Ниже представлена сравнительная оценка Z-Image по отношению к ведущим открытым и проприетарным моделям.
Comparative Benchmark Summary
| Feature / Metric | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Architecture | S3-DiT (Single Stream) | MM-DiT (Dual Stream) | U-Net | Diffusion Transformer |
| Parameters | 6 Billion | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Inference Steps | 8 Steps | 25 - 50 Steps | 1 - 4 Steps | 30 - 50 Steps |
| VRAM Required | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Text Rendering | High (EN + CN) | High (EN) | Moderate (EN) | High (CN + EN) |
| Generation Speed (4090) | ~1.5 - 3.0 Seconds | ~15 - 30 Seconds | ~0.5 Seconds | ~20 Seconds |
| Photorealism Score | 9.2/10 | 9.5/10 | 7.5/10 | 9.0/10 |
| License | Apache 2.0 | Non-Commercial (Dev) | OpenRAIL | Custom |
Data Analysis & Performance Insights
- Speed vs. Quality: Хотя SDXL Turbo быстрее (1 шаг), его качество существенно падает на сложных промптах. Z-Image-Turbo попадает в «золотую середину» на 8 шагах, сопоставляя качество Flux.2, оставаясь в 5–10 раз быстрее.
- Hardware Democratization: Flux.2, хотя и мощная, фактически доступна лишь на картах с 24GB VRAM (RTX 3090/4090) для адекватной производительности. Z-Image позволяет пользователям с картами среднего уровня (RTX 3060/4060) локально генерировать профессиональные изображения 1024×1024.
How can developers access and use Z-Image?
Существуют три типовых подхода:
- Hosted / SaaS (web UI or API): Используйте сервисы вроде z-image.ai или других провайдеров, которые разворачивают модель и предоставляют веб-интерфейс или платный API для генерации изображений. Это самый быстрый путь для экспериментов без локальной настройки.
- Hugging Face + diffusers pipelines: Библиотека Hugging Face
diffusersвключаетZImagePipelineиZImageImg2ImgPipelineи предоставляет типичные рабочие процессыfrom_pretrained(...).to("cuda"). Это рекомендуемый путь для Python-разработчиков, желающих простой интеграции и воспроизводимых примеров. - Local native inference from the GitHub repo: Репозиторий Tongyi-MAI включает нативные скрипты инференса, опции оптимизации (FlashAttention, компиляция, offload на CPU) и инструкции по установке
diffusersиз исходников для последней интеграции. Этот путь полезен для исследователей и команд, желающих полного контроля или запуска пользовательского обучения/дообучения.
What does a minimal Python example look like?
Ниже приведён краткий фрагмент Python с использованием Hugging Face diffusers, демонстрирующий генерацию «текст-в-изображение» с Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Notes:guidance_scale defaults and recommended settings differ for Turbo models; documentation suggests guidance may be set low or zero for Turbo depending on the target behavior.
How do you run image-to-image (edit) with Z-Image?
ZImageImg2ImgPipeline поддерживает редактирование изображений. Пример:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Это отражает официальные паттерны использования и подходит для творческого редактирования и задач инпейнтинга.
How should you approach prompts and guidance?
- Be explicit with structure: Для сложных сцен структурируйте промпты так, чтобы включать композицию сцены, ключевой объект, камеру/объектив, освещение, настроение и любые текстовые элементы. Z-Image хорошо справляется с детализированными промптами и может уверенно обрабатывать позиционные/нарративные указания.
- Tune guidance_scale carefully: Для Turbo-моделей могут рекомендоваться более низкие значения; требуется экспериментирование. Во многих рабочих процессах Turbo
guidance_scale=0.0–1.0с seed и фиксированным числом шагов даёт стабильные результаты. - Use image-to-image for controlled edits: Когда нужно сохранить композицию, но изменить стиль/окраску/объекты, начните с исходного изображения и используйте
strength, чтобы управлять величиной изменений.
Best Use Cases and Best Practices
1. Rapid Prototyping & Storyboarding
Use Case: Режиссёрам и гейм-дизайнерам нужно мгновенно визуализировать сцены.
Why Z-Image? При генерации менее чем за 3 секунды создатели могут перебрать сотни концепций за одну сессию, в реальном времени уточняя освещение и композицию, не дожидаясь минутного рендера.
2. E-Commerce & Advertising
Use Case: Генерация фонов продукта или лайфстайл-кадров для товаров.
Best Practice: Используйте Z-Image-Edit.
Загрузите сырой фото продукта и примените инструкцию вроде "Place this perfume bottle on a wooden table in a sunlit garden." Модель сохранит целостность продукта, сгенерировав фотореалистичный фон.
3. Bilingual Content Creation
Use Case: Глобальные маркетинговые кампании, требующие ассетов для западных и азиатских рынков.
Best Practice: Используйте возможность рендеринга текста.
- Prompt: "A neon sign that says 'OPEN' and '营业中' glowing in a dark alley."
- Z-Image корректно отрендерит и английские, и китайские символы, чем большинство других моделей не умеют.
4. Low-Resouce Environments
Use Case: Запуск генерации ИИ на конечных устройствах или стандартных офисных ноутбуках.
Optimization Tip: Используйте INT8 quantized version Z-Image. Это снижает потребление VRAM до менее чем 6GB с пренебрежимо малой потерей качества, делая локальные приложения на негеймерских ноутбуках реальными.
Bottom line: who should use Z-Image?
Z-Image создана для организаций и разработчиков, которым нужен высококачественный фотореализм при практической задержке и стоимости, и которые предпочитают открытое лицензирование и on-premises или кастомный хостинг. Она особенно привлекательна для команд, которым нужна быстрая итерация (креативные инструменты, продуктовые мокапы, сервисы в реальном времени), а также для исследователей/сообществ, интересующихся дообучением компактной, но мощной модели изображений.
CometAPI предлагает аналогично менее ограниченные модели Grok Image, а также модели вроде Nano Banana Pro, GPT- image 1.5, Sora 2 (Can Sora 2 generate NSFW content? How can we try it?) и т. д. — при условии, что у вас есть правильные NSFW советы и трюки для обхода ограничений и свободного творчества. Прежде чем получить доступ, убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предлагает цену значительно ниже официальной, чтобы помочь интегрировать.
Ready to Go?→ Free trial for Creating !