

Google og forskningsarmen DeepMind har stille (og deretter mindre stille) tatt et nytt stort steg i Gemini-veikartet: Gemini 3.1 Pro. Lanseringen, rullet ut på forbrukerrettede flater CometAPI, er posisjonert som en ytelses- og resonneringsoppgradering for Gemini 3-familien — og lover merkbart sterkere langformresonnering, forbedret multimodal forståelse og bedre skalerbarhet for virkelige bruksområder.
Googles nyeste modell — hva er Gemini 3.1 Pro?
Gemini 3.1 Pro er den første inkrementelle oppdateringen i Gemini 3-familien, posisjonert som en «mest kapabel» resonneringsmodell optimalisert for flertrinns, multimodale og agentiske oppgaver. Lansert i offentlig forhåndsvisning i midten av februar 2026 (forhåndsvisning annonsert 19.–20. feb. 2026), er modellen eksplisitt rettet mot scenarier som krever vedvarende tankerekker, verktøybruk og forståelse av lang kontekst — for eksempel: storskala forskningssyntese, ingeniør-agenter som koordinerer verktøy og systemer, og multimodal analyse av dokumenter som blander tekst, bilder, lyd og video.
På et overordnet nivå beskrives Gemini 3.1 Pro av utviklerne som:
- Naturlig multimodal — kan ta imot og resonnere over tekst, bilder, lyd og video.
- Bygget for lang kontekst — støtter svært store kontekstvinduer som egner seg for hele kodebaser, multidokument-dossierer eller lange transkripsjoner.
- Optimalisert for pålitelig resonnering og agentiske arbeidsflyter, noe som betyr at den er tunet til å planlegge, kalle verktøy og verifisere resultater på tvers av flertrinnsoppgaver.
Hvorfor dette er viktig nå: organisasjoner og utviklere går fra «gode samtaleassistenter» til «høyinnsats beslutningsstøtte- og forskningsagenter» (juridisk utkast, FoU-syntese, multimodal dokumentforståelse). Gemini 3.1 Pro er eksplisitt designet for det segmentet — for å redusere hallusinasjoner, produsere sporbar resonnering og integrere med CometAPI for både prototyping og produksjon.
Hva er de tekniske høydepunktene og funksjonene i Gemini 3.1 Pro?
Naturlig multimodalitet og ekstreme kontekstvinduer
Gemini 3.1 Pro viderefører Gemini-linjens fokus på multimodalitet. Ifølge modellkortet og produktnotatene aksepterer og resonnerer modellen over tekst, bilder, lyd og video i samme pipeline — en kapasitet som forenkler arbeidsflyter der datatyper blandes (f.eks. rettsdeposisjoner med lyd + transkripsjon + skannede dokumenter). Merk at modellen støtter et 1,000,000-token kontekstvindu og kan produsere lange utdata (publiserte notater angir utgangsgrenser på svært store størrelser som passer langformoppgaver). Denne skalaen gjør den egnet for bruksområder som å analysere hele koderepositorier, flerkapitteldokumenter eller lange transkripsjoner uten oppdeling.
«Dynamisk tenkning»: forbedret resonnering og trinnvis planlegging
Google beskriver 3.1 Pro som å ha forbedret «tenkning» — dvs. bedre intern håndtering av tankerekker og dynamisk valg av resonneringsstrategier avhengig av oppgavens kompleksitet. Modellen er tunet til å engasjere eksplisitt flertrinns planlegging når det trengs, og være token-effektiv mens den gjør det. I praksis betyr dette færre hallusinasjoner for komplekse, trinnvise problemer og forbedret faktakonsistens på flertrinns resonneringsbenchmarker.
Agentiske arbeidsflyter og verktøybruk
Et stort designfokus for 3.1 Pro er agentisk ytelse: koordinering av verktøy, invoking av nettforankring eller søk, skriving og kjøring av kodebiter, og verifisering av utdata gjennom sekundære pass. Google har integrert 3.1 Pro i agent-første produkter (f.eks. Antigravity-utviklingsmiljøet) for å la modeller kjøre oppgaver som involverer en redaktør, terminal og nettleser — og registrere artefakter som skjermbilder og nettleseropptak for å verifisere fremdrift. Disse funksjonene tar sikte på å redusere gapet mellom «rådgivende» modeller og modeller som faktisk utfører fler-verktøys arbeidsflyter pålitelig.
Spesialiserte undermoduser (Deep Research, Deep Think)
Google parer 3.1 Pro med «Deep Research» og refererer til en kommende «Deep Think»-variant. Disse undermodusene er rettet mot — henholdsvis — forskningsoppgaver med høy recall og maksimal resonneringsdybde (med ekstra beregningskostnad og latens). De er ment for analytikere, forskere og utviklere som trenger mer gjennomtenkte, høyere kvalitet på utdata fremfor de raskeste og billigste svarene.
Hvordan presterer Gemini 3.1 Pro på referansetester?
Gemini 3.1 Pro oppnår sterke gevinster over tidligere Gemini 3 Pro-resultater, og tar ofte ledelsen på et bredt sett av flertrinns resonnerings- og multimodale mål — men ligger etter noen konkurrenter på spesifikke spesialiserte oppgaver (særlig enkelte avanserte koding- eller ekspertspørsmålssett). Kort sagt: brede forbedringer med smale konkurrentfordeler i spesialbenchmarker.
Viktige benchmark-påstander og nøkkeltall
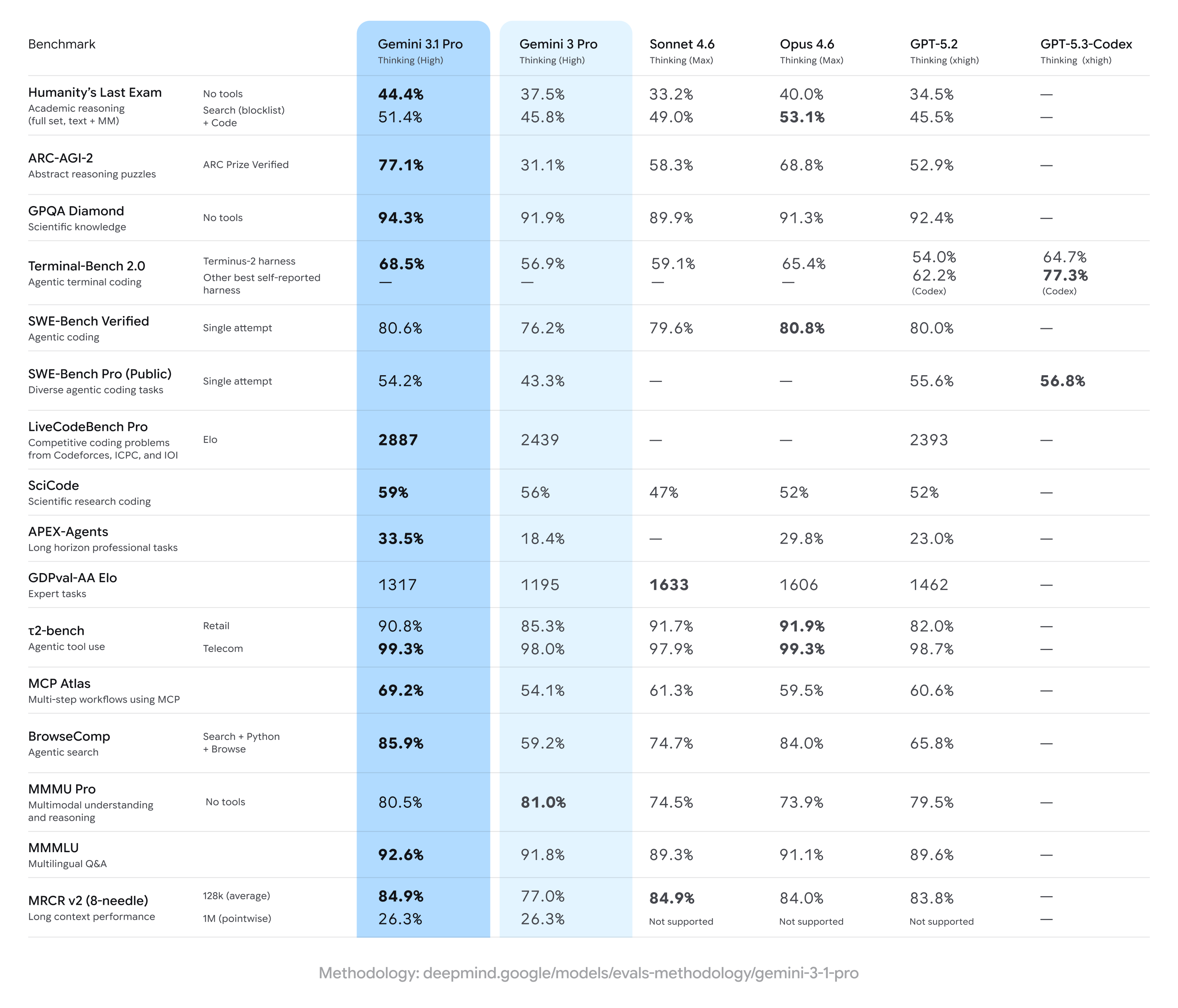
- ARC-AGI-2 (abstrakt resonnering / flertrinns vitenskapelige nøtter): Rapporterte økninger for Gemini 3.1 Pro viser betydelig forbedring fra tidligere Gemini 3 Pro-versjoner; ett community-testsett indikerte mer enn en dobling på ARC-AGI-2 vs. tidligere Gemini 3 Pro-baseline i korte, fokuserte tester. Spesifikke rapporterte poengsummer (community-tester) plasserer Gemini 3.1 Pro på ~77.1% på noen ARC-lignende aggregeringer (offentlig rapportering).
- GPQA Diamond og tester på masternivå innen realfag: Rapporter indikerer at Gemini 3.1 Pro nådde rekordhøyder på GPQA Diamond (en masternivå realfaglig QA-benchmark), overgikk tidligere Gemini-modeller og satte en ny høyvannslinje for familien i uavhengige kjøringer. Disse gevinstene reflekterer modellens forbedrede tankerekke- og trinnvise resonneringstuning.
- «Humanity’s Last Exam» med verktøy aktivert (flerverktøy, forankret resonnering): I direkte sammenligninger med Anthropics Claude Opus 4.6 oppnådde Claude 53.1% på denne komplekse verktøyaktiverte benchmarken, mens Gemini 3.1 Pro nådde 51.4% i samme testrunde — noe som viser at Gemini er tett bak, men ikke helt på topp på akkurat denne fler-verktøyprøven.
- Koding- og terminalbenchmarker (Terminal-Bench 2.0, SWE-Bench Pro): Spesialist-benchmarker for koding viste større divergens. På Terminal-Bench 2.0 med spesifikke rammeverk scoret GPT-5.3-Codex-varianter rundt 77.3% vs. Gemini 3.1 Pro sine ~68.5% i de samme sammenligningene. På SWE-Bench Pro, ifølge offentlig rapporterte resultater, scoret Gemini 3.1 Pro ~54.2% vs. GPT-5.3-Codex sine 56.8% — nærmere, men med OpenAIs Codex-familie som har et overtak på spesialiserte programmeringsoppgaver i disse kjøringene.
- GDPval-AA Elo (vurdering av ekspertoppgaver): I en Elo-stil aggregert rangering for ekspertoppgaver, scoret Claude Sonnet/Opus-varianter høyere (f.eks. ~1606–1633 poeng), mens en offentlig rapport plasserte Gemini 3.1 Pro på ~1317 poeng i det samme datasettet — noe som indikerer forbedringspotensial på enkelte smale ekspertdomener.
Resultater fra virkelige forsøk og praktiske tester
Praktiske analytikerapporter viser at Gemini 3.1 Pro særlig utmerker seg på:
- Langkontekst-sammendrag og multidokumentsyntese, der 1M-token-vinduet unngår artefakt-preget oppdeling.
- Multimodale forståelsesoppgaver hvor bilde + tekstforankring forbedrer faktauttrekk.
- Agentisk automatisering (f.eks. koordinering av enkle verktøykjeder) — med Antigravity-forsøk som viser at multiagent-orkestrering er mulig med artefakter som dokumenterer hvert steg.
Hvor Gemini 3.1 Pro fortsatt henger etter (hva tallene sier)
Ingen modell er best overalt. Uavhengige kommentarer og community-testing fremhever spesifikke gap:
- Programvareingeniør- og kodevedlikeholdsbenchmarker (SWE-Bench Pro og lignende) — Gemini 3.1 Pro ligger etter en konkurrent (Anthropics Claude Opus 4.6) på oppgaver som tester praktiske programvareingeniør-evner: storskala refaktoriseringer, feiltriage i rotete kodebaser og enkelte typer automatisert programreparasjon. Med andre ord: for dag-til-dag vedlikehold i ingeniørarbeid har spesialiserte modeller fortsatt et overtak i visse testmiljøer.
- Latensfølsomme mikrooppgaver — fordi Gemini 3.1 Pro er tunet for dybde, kan oppgaver som krever ultralav latens og høy gjennomstrømning (f.eks. mikroinferen s for lette samtalegrensesnitt) være bedre tjent med «Flash» eller andre optimaliserte varianter i Gemini-familien.
Hva koster Gemini 3.1 Pro?
Du kan få tilgang til Gemini 3.1 Pro på to måter — forbrukerabonnement eller utvikler-API — og prisene er ulike for hver.
- Forbruker (Gemini-appen / Google AI Pro): Tilgang til Gemini 3.1 Pro er inkludert i Google AI Pro-abonnementet, som i USA er $19.99 / måned (Google tilbyr også et lavere «AI Plus»-nivå og et høyere «AI Ultra»-nivå). Google.
- Utvikler / API (token-basert): Hvis du kaller Gemini-modellene via Gemini/AI-utvikler-API-et, prises bruken etter tokens. For Gemini 3.x Pro-forhåndsvisningen er de publiserte utviklerprisene omtrent: $2.00 per 1M input-tokens og $12.00 per 1M output-tokens for standardbåndet (≤200k forespørsler) — med høyere nivåer (f.eks. $4/$18 per 1M) for svært store kontekster. (Se Gemini API-pristabellen for alle detaljer og batch-priser.)
- Hvis du bruker Gemini 3.1 Pro via CometAPI:
| Comet-pris (USD / M tokens) | Offisiell pris (USD / M tokens) |
|---|---|
| Inndata:$1.6/M; Utdata:$9.6/M | Inndata:$2/M; Utdata:$12/M |
Forbrukerabonnement-priser (Gemini-appen)
For sluttbrukerplaner inne i Gemini-appen strukturerer Google nivåer som styrer tilgang til modellvarianter og ekstra funksjoner: Google AI Pro og Google AI Ultra. Prisene varierer etter marked og valuta; publiserte eksempler viser Google AI Pro til $19.99/måned (med kampanjeprøver tilgjengelig) og nivådelte valutapriser vises på produktsiden (inkludert prøveperioder og kortsiktige reduserte priser). AI Ultra pakker høyere tilgang (f.eks. prioritert tilgang til nye innovasjoner, høyere kreditter for videoproduksjon) til en høyere månedspris. Disse forbrukerplanprisene er konkurransedyktige med andre førsteklasses forbruker-AI-abonnementer og er posisjonert for å gi individuelle kraftbrukere eller små team tilgang til 3.1 Pro-funksjoner uten API-integrasjon.
Praktiske prompt- og brukstips (det jeg ville gjort)
Bruk disse for å få pålitelige, repeterbare resultater:
- Eksplisitt stegplanlegger
Prompt-mønster:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Dette utnytter 3.1 Pro sin sterkere trinnvise utførelse og gir deg sjekkpunkter. - Strukturerte utdata med skjemaer
Be om JSON med et skjema ogstrict: true. Fordi 3.1 Pro produserer lange, skjema-etterrettelige utdata mer pålitelig, får du større enkeltresponser du kan parse nedstrøms. - Verktøysjekk-sandwich
Når du påkaller eksterne verktøy (API-er, kodekjørere), la modellen produsere: plan → nøyaktig verktøykall (copy/paste-vennlig) → valideringssteg. Verifiser så valideringsstegene utenfor modellen før du fortsetter. - Vær varsom med enkeltstegstillit
Selv om modellen skriver tilsynelatende perfekt kode eller kommandoer, kjør uavhengig validering (tester, linters, sandkassekjøring) — spesielt for agentiske/autonome handlinger.
Hands-On med Gemini 3.1 Pro
Prøvetilfelle 1: Langkontekst forskningsassistent (NotebookLM / Deep Research)
Mål: Evaluere modellens evne til å syntetisere 10–50 lange dokumenter (f.eks. rapporter, whitepapers) til et flersiders lederoppsummering med sitater og tiltakspunkter.
Oppsett: Mat et korpus på totalt 200k–800k tokens; be modellen produsere en 2–4 siders oppsummering med eksplisitte sitater og anbefalte «neste steg». Bruk en repeterbar prompt-mal og mål tid, tokenbruk (kostnad) og faktanøyaktighet.
Resultater: Raskere ende-til-ende oppsummering med færre oppdelingsartefakter relativt til eldre modeller, høyere siteringsfidelitet i oppsummeringen og bedre sammenheng i skala — med kostnad av betydelig tokenbruk (så planlegg budsjettet). Benchmarker og praktiske tester viser at Gemini 3.1 Pro utmerker seg i multidokumentsyntese takket være 1M-token-vinduet.
Prøvetilfelle 2: Agentisk kodeassistent (Antigravity + GitHub Copilot)
Mål: Måle reduksjon i tid-til-fullføring for flertrinns utvikleroppgaver (f.eks. implementere en funksjon på tvers av flere filer, kjøre tester, fikse feilede tester).
Oppsett: Bruk Antigravity eller GitHub Copilot i forhåndsvisning med Gemini 3.1 Pro valgt. Definer reproduserbare oppgaver (issue-opprettelse → implementering → kjøre tester), logg steg og agentartefakter, og sammenlign med en ren menneskelig baseline.
Resultater: Forbedret orkestrering av flertrinnsoppgaver (artefaktregistrering, automatisk forslag til patch-kandidater), bedre flerfilresonnering enn tidligere Gemini 3 Pro, og målbare tidsbesparelser på rutinemessig funksjonsarbeid. Spesialiserte, lavnivå systemfeilsøkingsoppgaver kan fortsatt favorisere spesialiserte kodeførste-modeller (community-resultater viser et gap vs. noen GPT-Codex-varianter på visse terminalbenchmarker).
Prøvetilfelle 3: Multimodal juridisk/medisinsk dokumentgjennomgang
Mål: Bruke modellen til å ta inn et blandet korpus (skannede PDF-er, bilder, lydtranskripsjoner), trekke ut nøkkelfakta og produsere en risikomatrise og prioriterte handlinger.
Oppsett: Lever et datasett med skannede bilder og OCR-tekst, pluss støttende lyd. Mål presisjon i navngitt enhetsekstraksjon, falsk positiv-rate og modellens evne til å referere til kildeartefakter.
resultater: Sterkere integrert resonnering på tvers av modaliteter og mer sporbare utdata (evne til å peke på bildet / siden / lydtidsstempelet som støtter en påstand). Det lange kontekstvinduet reduserer behovet for manuell oppdeling og kryssreferering. I regulerte domener bør imidlertid utdata valideres av domeneeksperter og en forankrings-/verifiseringspipeline bør brukes.
Førsteinntrykk (hva føles annerledes)
- Dypere trinnvis resonnering. Oppgaver som tidligere trengte flere frem-og-tilbake — f.eks. multidokumentsyntese, flertrinns matematikk/logikk — fullføres oftere i færre pass og med klarere tankerekke-lignende utdata (uten å eksponere intern instruksjonstekst). Dette er overskriften Google fremhevet.
- Lengre, høyere kvalitet på strukturerte utdata. JSON og langtformede automasjoner er mer konsistente og ofte mye lengre (noen brukere rapporterte utstørrelser langt større enn 3.0). Det gjør den flott for genereringsjobber der du vil ha en enkelt, stor nyttelast. Forvent å håndtere større utdata og strømming.
- Mer effektiv token-/konteksthåndtering. Forbedret tokeneffektivitet og en mer «forankret, faktakonsistent» atferd for verktøybruksscenarier. Det viser seg i færre hallusinasjoner på korte faktasøk.
Endelig analyse: Er Gemini 3.1 Pro verdt å ta i bruk nå?
Gemini 3.1 Pro representerer et meningsfullt steg fremover i Gemini-familien med påviselige forbedringer på resonnering, koding og agentiske benchmarker — støttet av Googles publiserte modellkort og uavhengige trackere som viser store hopp på utvalgte topplister. For team som trenger avansert resonnering, agentisk verktøykoordinering eller langkontekst multimodale kapabiliteter, er 3.1 Pro en overbevisende kandidat.
Utviklere kan få tilgang til Gemini 3.1 Pro via CometAPI nå. For å komme i gang, utforsk modellens kapabiliteter i Playground og se API-veiledningen for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og skaffet API-nøkkelen. CometAPI tilbyr en pris langt lavere enn den offisielle prisen for å hjelpe deg med integrasjonen.
Ready to Go?→ Sign up fo Gemini 3.1 pro today !
Hvis du vil ha flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!