

per 15. desember 2025 viser offentlige fakta at Googles Gemini 3 Pro (preview) og OpenAIs GPT-5.2 begge setter nye grenser for resonnering, multimodalitet og arbeid med lange kontekster — men de tar ulike ingeniørmessige veier (Gemini → sparse MoE + enorm kontekst; GPT-5.2 → tette/«routing»-design, komprimering og x-high-reasoning-moduser) og avveier derfor toppresultater på benchmarker mot ingeniørmessig forutsigbarhet, verktøy og økosystem. Hvilken som er «best» avhenger av ditt primære behov: ekstreme kontekster og multimodale agentiske applikasjoner heller mot Gemini 3 Pro; stabilt bedriftsverktøy for utviklere, forutsigbare kostnader og umiddelbar API-tilgjengelighet favoriserer GPT-5.2.
Hva er GPT-5.2 og hva er hovedfunksjonene?
GPT-5.2 er OpenAIs utgivelse 11. desember 2025 i GPT-5-familien (varianter: Instant, Thinking, Pro). Den posisjoneres som selskapets mest kapable modell for «profesjonelt kunnskapsarbeid» — optimalisert for regneark, presentasjoner, langkontekstresonnering, verktøykalling, kodegenerering og visjonsoppgaver. OpenAI gjorde GPT-5.2 tilgjengelig for betalende ChatGPT-brukere og via OpenAI API (Responses API / Chat Completions) under modellenavn som gpt-5.2, gpt-5.2-chat-latest og gpt-5.2-pro.
Modellvarianter og tiltenkt bruk
- gpt-5.2 / GPT-5.2 (Thinking) — best for kompleks, flertrinns resonnering (standardvarianten «Thinking» brukt i Responses API).
- gpt-5.2-chat-latest / Instant — lavere ventetid for daglig assistent- og chattebruk.
- gpt-5.2-pro / Pro — høyest presisjon/pålitelighet for de vanskeligste problemene (ekstra compute, støtter
reasoning_effort: "xhigh").
Viktige tekniske funksjoner (brukerrettede)
- Visjon og multimodale forbedringer — bedre romlig resonnering på bilder og forbedret videoforståelse når den kombineres med kodeverktøy (Python-verktøy), samt støtte for verktøy i stil med code-interpreter for å kjøre snutter.
- Konfigurerbar reasoning-innsats (
reasoning_effort: none|minimal|low|medium|high|xhigh) for å avveie ventetid/kostnad mot dybde.xhigher nytt for GPT-5.2 (og støttes i Pro). - Forbedret håndtering av lange kontekster og komprimeringsfunksjoner for å resonnere over hundretusener av tokens (OpenAI rapporterer sterke MRCRv2-/langkontekst-metrikker).
- Avansert verktøykalling og agentiske arbeidsflyter — sterkere fleromgangskoordinering, bedre orkestrering av verktøy i en «single mega-agent»-arkitektur (OpenAI fremhever Tau2-bench-verktøyytelse).
Hva er Gemini 3 Pro Preview?
Gemini 3 Pro Preview er Googles mest avanserte generative KI-modell, lansert som del av den bredere Gemini 3-familien i november 2025. Modellen er bygget med vekt på multimodal forståelse — i stand til å forstå og syntetisere tekst, bilder, video og lyd — og har et stort kontekstvindu (~1 million tokens) for å håndtere omfattende dokumenter eller kodebaser.
Google posisjonerer Gemini 3 Pro som i front når det gjelder resonneringsdybde og nyanser, og den fungerer som motor for flere utvikler- og bedriftsverktøy, inkludert Google AI Studio, Vertex AI og agentiske utviklingsplattformer som Google Antigravity.
Per nå er Gemini 3 Pro i preview — noe som betyr at funksjonalitet og tilgang fortsatt utvides, men modellen skårer allerede høyt på logikk, multimodal forståelse og agentiske arbeidsflyter.
Viktige tekniske og produktmessige funksjoner
- Kontekstvindu: Gemini 3 Pro Preview støtter en 1,000,000-tokeners input-kontekst (og opptil 64k token-utdata), som er en stor praktisk fordel for å ta inn ekstremt store dokumenter, bøker eller videotranskripsjoner i én forespørsel.
- API-funksjoner:
thinking_level-parameter (low/high) for å avveie ventetid og resonneringsdybde;media_resolution-innstillinger for å kontrollere multimodal kvalitet og tokenbruk; søkegrunnlag, fil/URL-kontekst, kodekjøring og funksjonskalling støttes. Thought signatures og kontekstbufring hjelper med å opprettholde tilstand på tvers av fler-kalls arbeidsflyter. - Deep Think-modus / høyere resonnering: Et «Deep Think»-valg gir en ekstra resonneringsrunde for å presse resultatene på vanskelige benchmarker. Google publiserer Deep Think som en egen høyytelsesvei for komplekse problemer.
- Multimodal nativ støtte: Tekst-, bilde-, lyd- og videoinnganger med tett grunnlag for søk og produktintegrasjoner (Video-MMMU-score og andre multimodale benchmarker fremheves).
Lynoversikt — GPT-5.2 vs Gemini 3 Pro
Kompakt sammenligningstabell med de viktigste fakta (kilder oppgitt).
| Aspect | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Vendor / positioning | OpenAI — flaggskipsoppgradering i GPT-5.x med fokus på profesjonelt kunnskapsarbeid, koding og agentiske arbeidsflyter. | Google DeepMind / Google AI — flaggskip i Gemini-generasjonen med fokus på ultralang-kontekst multimodal resonnering og verktøyintegrasjon. |
| Main model flavors | Instant, Thinking, Pro (og Auto som bytter mellom dem). Pro gir høyere reasoning-innsats. | Gemini 3-familien inkludert Gemini 3 Pro og Deep-Think-moduser; multimodalt / agentisk fokus. |
| Context window (input / output) | ~400,000 tokens total inputkapasitet; opptil 128,000 output-/reasoning-tokens (designet for svært lange dokumenter og kodebaser). | Opptil ~1,000,000 tokens input/kontekstvindu (1M) med opptil 64K-tokens utdata |
| Key strengths / focus | Langkontekstresonnering, agentisk verktøykalling, koding, strukturerte arbeidsoppgaver (regneark, presentasjoner); sikkerhets-/systemkort-oppdateringer vektlegger pålitelighet. | Multimodal forståelse i stor skala, resonnering + bildeparti, svært stor kontekst + «Deep Think»-modus, sterke verktøy-/agentintegrasjoner i Google-økosystemet. |
| Multimodal & image capabilities | Forbedret visjon og multimodal forankring; tunet for verktøybruk og dokumentanalyse. | Høyoppløst bildegenerering + resonneringsforsterket komposisjon, bilde-redigering med flere referanser og leselig tekstrendering. |
| Latency / interactivity | Leverandøren fremhever raskere inferens og responstid (lavere latens enn tidligere GPT-5.x-modeller); flere nivåer (Instant / Thinking / Pro). | Google fremhever optimalisert «Flash»/tjenestelag og sammenlignbare interaktive hastigheter for mange flyter; Deep Think-modus bytter latens mot dypere resonnering. |
| Notable features / differentiators | Reasoning-innsatsnivåer (medium/high/xhigh), forbedret verktøykalling, kode av høy kvalitet, høy token-effektivitet for bedriftsarbeidsflyter. | 1M tokens kontekst, sterk nativ multimodal innlesing (video/lyd), «Deep Think»-modus, tette Google-produktintegrasjoner (Docs/Drive/NotebookLM). |
| Typical best uses (short) | Langdokumentanalyse, agentiske arbeidsflyter, komplekse kodeprosjekter, bedriftsautomatisering (regneark/rapporter). | Ekstremt store multimodale prosjekter, langhorisont-agentiske arbeidsflyter som trenger 1M-token kontekst, avanserte bilde- + resonneringspipeliner. |
Hvordan sammenlignes GPT-5.2 og Gemini 3 Pro arkitektonisk?
Kjernearkitektur
- Benchmarker / virkelige evalueringer: GPT-5.2 Thinking oppnådde 70.9% seire/uavgjort på GDPval (44-yrkes kunnskapsarbeidsevaluering) og store gevinster på ingeniør- og mattebenchmarker vs. tidligere GPT-5-varianter. Betydelige forbedringer i koding (SWE-Bench Pro) og domenevitenskapelig QA (GPQA Diamond).
- Verktøy og agenter: Innebygd støtte for verktøykalling, Python-kjøring og agentiske arbeidsflyter (dokumentsøk, filanalyse, data science-agenter). 11x hastighet / <1% kostnad vs. menneskelige eksperter for noen GDPval-oppgaver (mål på potensiell økonomisk verdi, 70.9% vs. tidligere ~38.8%), og viser konkrete gevinster i regnearkmodellering (f.eks. +9.3% på en junior investment banking-oppgave vs. GPT-5.1).
- Gemini 3 Pro: Sparse Mixture-of-Experts Transformer (MoE). Modellen aktiverer et lite sett eksperter per token, som muliggjør svært stor total parameterkapasitet med sublineær per-token compute. Google publiserer et model card som klargjør at Sparse MoE-designet er en kjernebidragsyter til den forbedrede ytelsesprofilen. Denne arkitekturen gjør det mulig å øke modellkapasiteten langt høyere uten lineære inferenskostnader.
- GPT-5.2 (OpenAI): OpenAI fortsetter å bruke Transformer-baserte arkitekturer med routing/komprimerings-strategier i GPT-5-familien (en «router» utløser ulike moduser — Instant vs. Thinking — og selskapet dokumenterer komprimering og token-håndteringsteknikker for lange kontekster). GPT-5.2 vektlegger trening og evaluering for å «tenke før den svarer» og komprimering for langhorisont-oppgaver heller enn å annonsere klassisk sparse-MoE i stor skala.
Impliasjoner av arkitekturene
- Latens- og kostnadsavveininger: MoE-modeller som Gemini 3 Pro kan tilby høyere toppkapabilitet per token samtidig som inferenskostnaden holdes lavere for mange oppgaver fordi bare et delsett eksperter kjøres. De kan imidlertid øke kompleksiteten i servering og planlegging (cold-start ekspertbalansering, IO). GPT-5.2s tilnærming (tett/rutet med komprimering) favoriserer forutsigbar latens og utviklervennlighet — spesielt når den er integrert i etablerte OpenAI-verktøy som Responses, Realtime, Assistants og batch-API-er.
- Skalering av lang kontekst: Geminis 1M input-token-kapasitet lar deg mate inn ekstremt lange dokumenter og multimodale strømmer nativt. GPT-5.2s ~400k kombinert kontekst (input+output) er fortsatt massiv og dekker de fleste bedriftsbehov, men er mindre enn Geminis 1M-spesifikasjon. For svært store korpus eller fler-timers videotranskripsjoner gir Geminis spesifikasjon en tydelig teknisk fordel.
Verktøy, agenter og multimodal infrastruktur
- OpenAI: dyp integrasjon for verktøykalling, Python-kjøring, «Pro»-resonneringsmoduser og betalte agentøkosystemer (ChatGPT Agents / bedriftsverktøyintegrasjoner). Sterkt fokus på kode-sentriske arbeidsflyter og generering av regneark / lysbilder som førsteklasses utdata.
- Google / Gemini: innebygd forankring til Google Søk (valgfri fakturert funksjon), kodekjøring, URL- og filkontekst, og eksplisitte mediaoppløsningskontroller for å avveie tokens mot visuell kvalitet. API-et tilbyr
thinking_levelog andre knotter for å justere kost/latens/kvalitet.
Hvordan sammenlignes benchmark-tallene
Kontekstvindu og token-håndtering
- Gemini 3 Pro Preview: 1,000,000 input-tokens / 64k output-tokens (Pro preview model card). Knowledge cutoff: January 2025 (Google).
- GPT-5.2: OpenAI demonstrerer sterk langkontekstyting (MRCRv2-score på tvers av 4k–256k needle-oppgaver med >85–95% i mange innstillinger) og bruker komprimeringsfunksjoner; OpenAIs offentlige konteksteksempler indikerer robust ytelse selv ved svært store kontekster, men OpenAI lister variantspesifikke vinduer (og vektlegger komprimering fremfor et enkelt 1M-tall). For API-bruk er modellnavnene
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Resonnering og agentiske benchmarker
- OpenAI (utvalg): Tau2-bench Telecom 98.7% (GPT-5.2 Thinking), sterke gevinster i flertrinns verktøybruk og agentiske oppgaver (OpenAI fremhever kollapsing av multi-agent-systemer til en «mega-agent»). GPQA Diamond og ARC-AGI viste trinnvise økninger over GPT-5.1.
- Google (utvalg): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87.6%, høye GPQA- og Humanity’s Last Exam-score; Google demonstrerer også sterk langhorisont-planlegging via agentiske eksempler.
Verktøy og agenter:
GPT-5.2: Innebygd støtte for verktøykalling, Python-kjøring og agentiske arbeidsflyter (dokumentsøk, filanalyse, data science-agenter). 11x hastighet / <1% kostnad vs. menneskelige eksperter for noen GDPval-oppgaver (mål på potensiell økonomisk verdi, 70.9% vs. tidligere ~38.8%), og viser konkrete gevinster i regnearkmodellering (f.eks. +9.3% på en junior investment banking-oppgave vs. GPT-5.1).
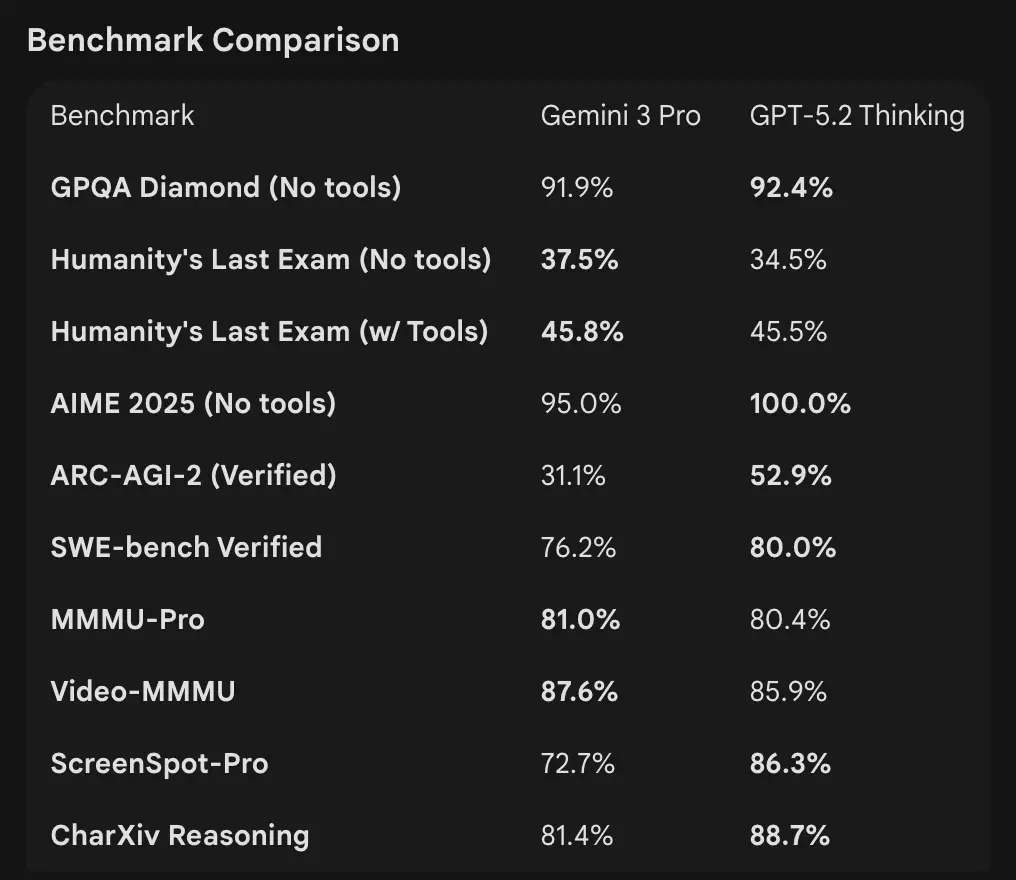
Tolkning: benchmarkene er komplementære — OpenAI vektlegger reelle kunnskapsarbeids-benchmarker (GDPval) som viser at GPT-5.2 utmerker seg i produksjonsoppgaver som regneark, lysbilder og lange agentiske sekvenser. Google vektlegger ledertabeller for rå resonnering og ekstremt store kontekstvinduer for enkeltsforespørsler. Hva som betyr mest avhenger av arbeidslasten din: agentiske, langdokument-baserte bedriftslinjer favoriserer GPT-5.2s dokumenterte GDPval-ytelse; inntak av massiv rå kontekst (f.eks. hele videokorpora / hele bøker i én pass) favoriserer Geminis 1M input-vindu.
Hvordan sammenlignes de multimodale kapasitetene?
Inndata og utdata
- Gemini 3 Pro Preview: støtter tekst, bilde, video, lyd, PDF som inndata og tekstutdata; Google tilbyr granulære
media_resolution-kontroller og enthinking_level-parameter for å avveie kost mot kvalitet for multimodalt arbeid. Utdata-token-tak 64k; inndata opptil 1M tokens. - GPT-5.2: støtter rike visjons- og multimodale arbeidsflyter; OpenAI fremhever forbedret romlig resonnering (estimert merking av komponenter i bilder), videoforståelse (Video MMMU-score) og verktøyaktivert visjon (Python-verktøy på visjonsoppgaver forbedrer score). GPT-5.2 fremhever at komplekse visjon + kode-oppgaver drar stort nytte av at verktøystøtte (Python-kodekjøring) er aktivert.
Praktiske forskjeller
Granularitet vs. bredde: Gemini eksponerer en serie multimodale knotter (media_resolution, thinking_level) som lar utviklere finstille avveininger per medietype. GPT-5.2 vektlegger integrert verktøybruk (kjøre Python i løkken) for å kombinere visjon, kode og datatransformasjoner. Hvis bruken din er tung video + bildeanalyse med ekstremt store kontekster, er Geminis 1M-kontekst overbevisende; hvis arbeidsflytene dine krever programmatisk kjøring av kode i løkken (datatransformasjoner, generering av regneark), kan GPT-5.2s kodeverktøy og agentvennlighet være mer praktisk.
Hva med API-tilgang, SDK-er og priser?
OpenAI GPT-5.2 (API og priser)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provia Responses API / Chat Completions. Etablerte SDK-er (Python/JS), kokebøker og et modent økosystem. - Priser (offentlig): $1.75 / 1M input-tokens og $14 / 1M output-tokens; cache-rabatter (90% for bufrede inputs) reduserer effektiv kost ved gjentatt data. OpenAI vektlegger tokeneffektivitet (høyere pris per token, men lavere totalkost for å nå en kvalitetsgrense).
Gemini 3 Pro Preview (API og priser)
- API:
gemini-3-pro-previewvia Google GenAI SDK og Vertex AI/GenerativeLanguage-endepunkter. Nye parametere (thinking_level,media_resolution) og integrasjon med Googles grunnlag og verktøy. - Priser (offentlig preview): Omtrent $2 / 1M input-tokens og $12 / 1M output-tokens for preview-nivåer under 200k tokens; tilleggskostnader kan påløpe for Search-grunnlag, Maps eller andre Google-tjenester (Search-grunnlag-fakturering starter 5. januar 2026).
Bruk GPT-5.2 og Gemini 3 via CometAPI
CometAPI er en gateway-/aggregator-API: ett, OpenAI-lignende REST-API-endepunkt som gir deg enhetlig tilgang til hundrevis av modeller fra mange leverandører (LLM-er, bilde-/videomodeller, embeddings, osv.). I stedet for å integrere mange leverandør-SDK-er, lar CometAPI deg kalle kjente OpenAI-formatendepunkter (chat/completions/embeddings/images) mens du bytter modell eller leverandør under panseret.
Utviklere kan bruke flaggskipsmodeller fra to forskjellige selskaper samtidig via CometAPI uten å bytte leverandør, og API-prisene er mer rimelige, som regel 20% lavere.
Eksempel: raske API-snutter (kopi–lim inn for å prøve)
Nedenfor er minimale eksempler du kan kjøre. De gjenspeiler leverandørenes publiserte quickstarts (OpenAI Responses API + Google GenAI-klient). Erstatt $OPENAI_API_KEY / $GEMINI_API_KEY med nøklene dine.
GPT-5.2 — Python (OpenAI Responses API, reasoning satt til xhigh for dype problemer)
# Python (krever openai-SDK som støtter Responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 eller gpt-5.2-pro input="Oppsummer denne selskapsrapporten på 50k tokens og lag en disposisjon for en presentasjon med 10 lysbilder med talernotater.", reasoning={"effort": "xhigh"}, # dypere resonnering max_output_tokens=4000)print(resp.output_text) # eller inspiser resp for å hente strukturerte utdata / tokens
Notater: reasoning.effort lar deg avveie kostnad mot dybde. Bruk gpt-5.2-chat-latest for Instant chat-stil. OpenAI-dokumentasjonen viser eksempler for responses.create.
GPT-5.2 — curl (enkelt)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Skriv en Python-funksjon som konverterer en PDF med tabeller til en normalisert CSV med typede kolonner.", "reasoning": {"effort":"high"} }'
(Undersøk JSON for output_text eller strukturerte utdata.)
Gemini 3 Pro Preview — Python (Google GenAI-klient)
# Python (google genai-klient) — eksempel fra Google-dokfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Finn race condition i denne multitrådede C++-snutten: <lim inn kode her>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Notater: thinking_level styrer modellens interne overveielse; media_resolution kan settes for bilder/videoer. REST- og JS-eksempler finnes i Googles Gemini-utviklerguide.
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Forklar race condition i denne C++-koden: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
Googles dokumenter inkluderer multimodale eksempler (innebygd bildedata, media_resolution).
Hvilken modell er «best» — praktiske råd
Det finnes ingen «vinner» som passer alle; velg i stedet basert på brukstilfelle og begrensninger. Nedenfor er en kort beslutningsmatrise.
Velg GPT-5.2 hvis:
- Du trenger tett integrasjon med kodekjøringsverktøy (OpenAIs interpreter-/verktøyøkosystem) for programmatisk datarør, generering av regneark eller agentiske kode-arbeidsflyter. OpenAI fremhever Python-verktøyforbedringer og agentisk mega-agent-bruk.
- Du prioriterer tokeneffektivitet etter leverandørens påstander og vil ha eksplisitt, forutsigbar OpenAI-prising per token med store rabatter på bufrede inndata (nyttig i batch/produksjonsflyter).
- Du vil ha OpenAI-økosystemet (ChatGPT-produktintegrasjon, Azure / Microsoft-partnerskap og verktøy rundt Responses API og Codex).
Velg Gemini 3 Pro hvis:
- Du trenger ekstreme multimodale inndata (video + bilder + lyd + pdf-er) og ønsker én modell som nativt aksepterer alt dette med et 1,000,000 token input-vindu. Google markedsfører dette eksplisitt for lange videoer, store dokument + video-pipeliner og interaktiv bruk av Search/AI Mode.
- Du bygger på Google Cloud / Vertex AI og vil ha tett integrasjon med Google søkegrunnlag, Vertex-provisjonering og GenAI-klient-API-er. Du vil dra nytte av Google-produktintegrasjoner (Search AI Mode, AI Studio, Antigravity-agentverktøy).
Konklusjon: Hvilken er best i 2026?
I «GPT-5.2 vs. Gemini 3 Pro Preview»-oppgjøret er svaret kontekst-avhengig:
- GPT-5.2 leder i profesjonelt kunnskapsarbeid, analytisk dybde og strukturerte arbeidsflyter.
- Gemini 3 Pro Preview utmerker seg i multimodal forståelse, integrerte økosystemer og oppgaver med stor kontekst.
Ingen av modellene er universelt «best» — styrkene deres utfyller ulike reelle behov. Kloke brukere bør matche modellvalg til spesifikke brukstilfeller, budsjettbegrensninger og økosystemtilhørighet.
Det som er klart i 2026 er at KI-fronten har rykket betydelig frem, og både GPT-5.2 og Gemini 3 Pro presser grensene for hva intelligente systemer kan oppnå i virksomheter og utover.
Hvis du vil prøve med én gang, utforsk GPT-5.2 og Gemini 3 Pro sine kapabiliteter via CometAPI i Playground, og se API-guiden for detaljerte instruksjoner. Før tilgang, sørg for at du er innlogget på CometAPI og har hentet API-nøkkelen. CometAPI tilbyr en pris langt under offisiell pris for å hjelpe deg å integrere.
Klar til start?→ Gratis prøve av GPT-5.2 og Gemini 3 Pro !
Hvis du vil