

OpenAI publiserte en forhåndsvisning av forskningen gpt-oss-sikkerhet, en åpenvekts inferensmodellfamilie utviklet for å la utviklere håndheve sin egen sikkerhetspolicyer på tidspunktet for slutning. I stedet for å levere en fast klassifikator eller en svartboks-modereringsmotor, er de nye modellene finjustert til grunn fra en utviklerlevert policy, avgir en tankekjede (CoT) som forklarer resonnementet sitt, og produserer strukturerte klassifiseringsresultater. gpt-oss-safeguard, som ble annonsert som en forhåndsvisning av forskningen, presenteres som et par resonneringsmodeller—gpt-oss-safeguard-120b og gpt-oss-safeguard-20b—finjustert fra gpt-oss-familien og eksplisitt designet for å utføre sikkerhetsklassifisering og policyhåndhevelsesoppgaver under inferens.
Hva er gpt-oss-safeguard?
gpt-oss-safeguard er et par åpne, tekstbaserte resonneringsmodeller som har blitt ettertrent fra gpt-oss-familien til tolke en policy skrevet på naturlig språk og merke tekst i henhold til den policyenDet særegne trekket er at politikken er gitt på slutningstidspunktet (policy-as-input), ikke bakt inn i statiske klassifiseringsvekter. Modellene er primært utviklet for sikkerhetsklassifiseringsoppgaver – f.eks. moderering av flere policyer, innholdsklassifisering på tvers av flere regulatoriske regimer eller kontroller av samsvar med policyer.
Hvorfor er dette viktig
Tradisjonelle modereringssystemer er vanligvis avhengige av (a) faste regelsett som er kartlagt til klassifikatorer som er trent på merkede eksempler, eller (b) heuristikker/regekser for nøkkelorddeteksjon. gpt-oss-safeguard forsøker å endre paradigmet: i stedet for å trene klassifikatorer på nytt når policyen endres, oppgir du en policytekst (for eksempel bedriftens policy for akseptabel bruk, plattformvilkår eller en regulators retningslinje), og modellen resonnerer om et gitt innholdsstykke bryter med denne policyen. Dette lover smidighet (policyendringer uten omtrening) og tolkbarhet (modellen sender ut sin resonnementskjede).
Dette er kjernefilosofien – «Å erstatte memorering med resonnering, og gjetting med forklaring.»
Dette representerer et nytt stadium innen innholdssikkerhet, der man går fra «passiv læring av regler» til «aktiv forståelse av regler».
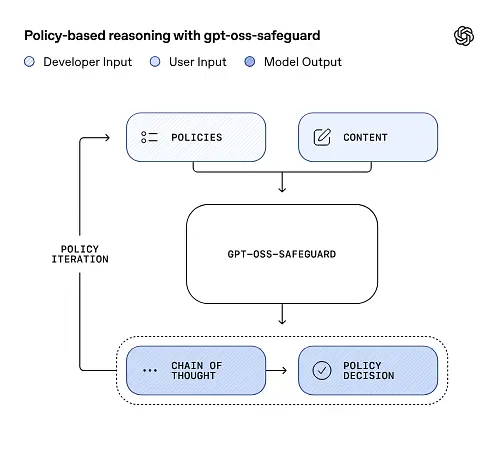
gpt-oss-safeguard kan lese sikkerhetspolicyene som er definert av utviklerne direkte og følge disse policyene for å foreta vurderinger under inferens.
Hvordan fungerer gpt-oss-safeguard?
Policy-as-input-resonnement
Ved slutningstidspunktet oppgir du to ting: policytekst og kandidatinnhold skal merkes. Modellen behandler policyen som den primære instruksjonen og utfører deretter trinnvis resonnement for å avgjøre om innholdet er tillatt, ikke tillatt eller krever ytterligere modereringstrinn. Ved slutning gjør modellen:
- produserer en strukturert utdata som inkluderer en konklusjon (etikett, kategori, konfidens) og et menneskelig lesbart resonnementspor som forklarer hvorfor konklusjonen ble nådd.
- inntar retningslinjene og innholdet som skal klassifiseres,
- resonnerer internt gjennom policyens klausuler ved hjelp av tankekjedelignende trinn, og
For eksempel:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Den vil svare:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Tankekjede (CoT) og strukturerte resultater
gpt-oss-safeguard kan sende ut et fullstendig CoT-spor som en del av hver inferens. CoT-en er ment å være inspiserbar – samsvarsteam kan lese hvorfor modellen kom til en konklusjon, og ingeniører kan bruke sporet til å diagnostisere tvetydighet i policyen eller modellfeilmoduser. Modellen støtter også strukturerte utganger– for eksempel en JSON som inneholder en dom, brutte retningslinjeparagrafer, alvorlighetsgrad og foreslåtte utbedringstiltak – noe som gjør det enkelt å integrere i modereringsprosesser.
Justerbare nivåer av «resonnementsinnsats»
For å balansere latens, kostnad og grundighet støtter modellene konfigurerbar resonneringsinnsats: lav / middels / høyHøyere innsats øker dybden i tankekjeden og gir generelt mer robuste, men langsommere og mer kostbare, slutninger. Dette lar utviklere prioritere arbeidsbelastninger – bruk lav innsats for rutineinnhold og høy innsats for kanttilfeller eller innhold med høy risiko.
Hva er modellstrukturen, og hvilke versjoner finnes?
Modellfamilie og avstamning
gpt-oss-safeguard er etterutdannet varianter av OpenAIs tidligere gpt-oss åpne modeller. Safety-familien inkluderer for øyeblikket to utgitte størrelser:
- gpt-oss-safeguard-120b – en modell på 120 milliarder parametere beregnet for svært nøyaktige resonneringsoppgaver som fortsatt kjører på en enkelt 80 GB GPU i optimaliserte kjøretider.
- gpt-oss-safeguard-20b – en modell på 20 milliarder parametere optimalisert for rimeligere inferens og kant- eller lokale miljøer (kan kjøre på 16 GB VRAM-enheter i enkelte konfigurasjoner).
Arkitekturnotater og kjøretidsegenskaper (hva du kan forvente)
- Aktive parametere per token: Den underliggende gpt-oss-arkitekturen bruker teknikker som reduserer antall parametere som aktiveres per token (en blanding av tett og sparsom oppmerksomhet / blanding av eksperter-stildesign i den overordnede gpt-oss).
- Praktisk sett passer 120B-klassen på enkeltstående store akseleratorer, og 20B-klassen er designet for å operere på 16 GB VRAM-oppsett i optimaliserte kjøretider.
Sikkerhetsmodeller var ikke trent med ytterligere biologiske eller cybersikkerhetsdata, og at analyser av verst tenkelige misbruksscenarioer utført for gpt-oss-utgivelsen omtrent gjelder for sikkerhetsvariantene. Modellene er ment for klassifisering snarere enn innholdsgenerering for sluttbrukere.
Hva er målene med gpt-oss-safeguard
Mål
- Fleksibilitet i retningslinjene: la utviklere definere enhver policy i naturlig språk og la modellen bruke den uten innsamling av tilpassede etiketter.
- Forklaring: avsløre resonnement slik at beslutninger kan revideres og retningslinjer itereres.
- tilgjengelighet: tilby et åpent alternativ slik at organisasjoner kan kjøre sikkerhetsresonnement lokalt og inspisere modellens indre deler.
Sammenligning med klassiske klassifikatorer
Fordeler kontra tradisjonelle klassifikatorer
- Ingen omskolering for endringer i retningslinjene: Hvis modereringspolicyen din endres, bør du oppdatere policydokumentet i stedet for å samle inn etiketter og trene en klassifikator på nytt.
- Rikere resonnement: CoT-resultater kan avsløre subtile politiske interaksjoner og gi narrativ begrunnelse som er nyttig for menneskelige granskere.
- Tilpassbarhet: En enkelt modell kan anvende mange forskjellige policyer samtidig under inferens.
Ulemper kontra tradisjonelle klassifikatorer
- Ytelsesgrenser for noen oppgaver: OpenAIs evaluering bemerker at Høykvalitets klassifikatorer trent på titusenvis av merkede eksempler kan utkonkurrere gpt-oss-safeguard på spesialiserte klassifiseringsoppgaver. Når målet er nøyaktighet i rå klassifisering og du har merkede data, kan en dedikert klassifikator som er trent på den fordelingen være bedre.
- Latens og kostnad: Resonnement med CoT er beregningsintensivt og tregere enn en lett klassifikator; dette kan gjøre rent sikkerhetsbaserte pipelines dyre i stor skala.
Kort sagt: gpt-oss-safeguard brukes best der policy smidighet og reviderbarhet er prioriteter eller når merkede data er knappe – og som en komplementær komponent i hybride pipelines, ikke nødvendigvis som en drop-in-erstatning for en skalaoptimalisert klassifiserer.
Hvordan presterte gpt-oss-safeguard i OpenAIs evalueringer?
OpenAI publiserte baseline-resultater i en 10-siders teknisk rapport som oppsummerer interne og eksterne evalueringer. Viktige konklusjoner (utvalgte, lastbærende målinger):
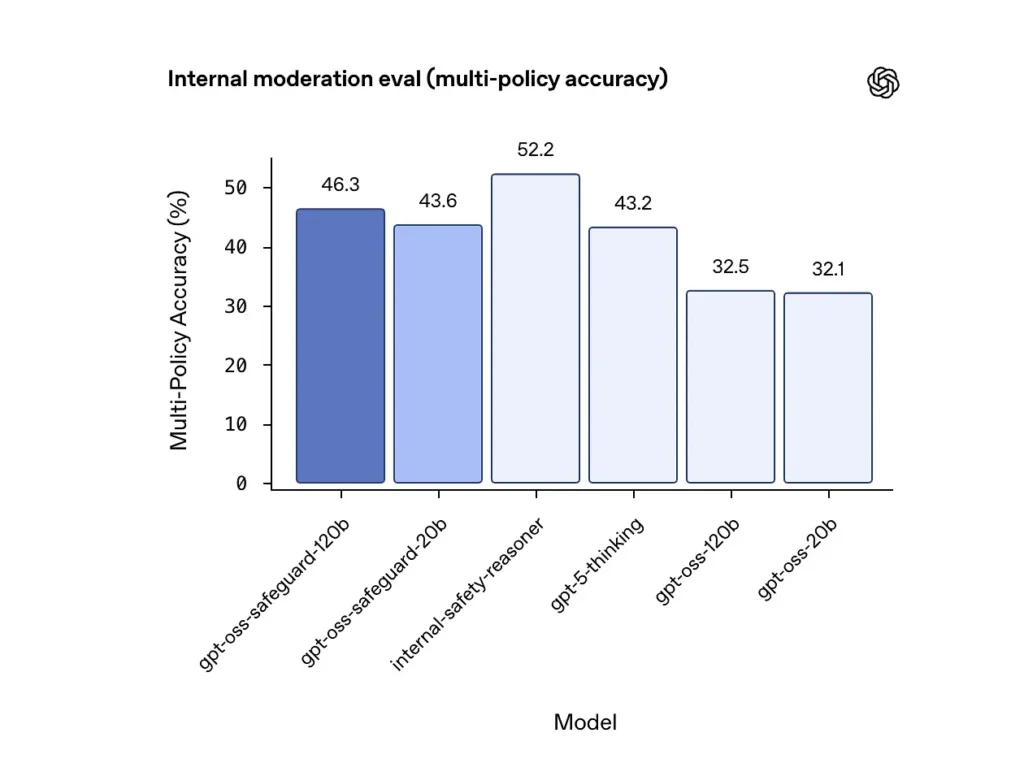
Nøyaktighet i flere policyer (intern evaluering)
OpenAI evaluerte nøyaktigheten av flere policyer ved å gi modellen flere retningslinjer samtidig og teller en prediksjon som korrekt bare hvis den samsvarte med de gylne etikettene på tvers alle retningslinjer. Resultater:
- gpt-oss-safeguard-120b: 46.3% nøyaktighet i flere policyer
- gpt-oss-safeguard-20b: 43.6%
- Til sammenligning: gpt-5-tenkning: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
OpenAIs interne «sikkerhetsresonnerings»-ensemble scoret 52.2 % i samme test. Disse tallene viser at sikkerhetsmodellene overgår gpt-oss-basismodellene betydelig på flerpolicyoppgaven, og de overgikk til og med den større gpt-5-tenkningsgrunnlinjen i den interne flerpolicymålingen.
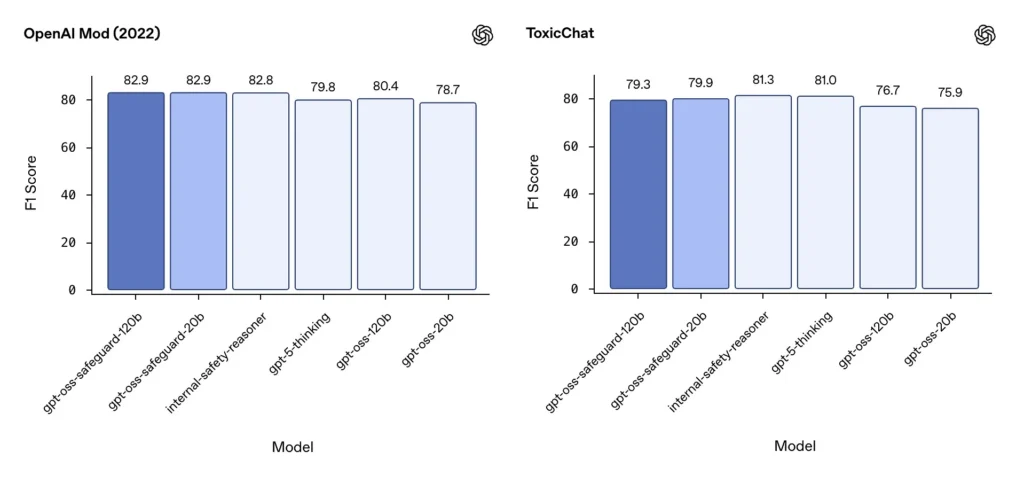
Moderering F1 (eksterne referansepunkter)
På OpenAIs modereringsdatasett fra 2022 og den offentlige ToxicChat-referanseindeksen oppnådde gpt-oss-safeguard-modellene solide F1-poengsummer:
- OpenAI-mod (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
Disse poengsummene plasserer gpt-oss-safeguard nær eller litt bak spesialiserte OpenAI-interne systemer på noen benchmarks, og generelt foran de ufinjusterte gpt-oss-motpartene.
Observerte begrensninger
OpenAI markerer to praktiske begrensninger:
- Klassifikatorer trent på store, oppgavespesifikke merkede datasett kan fortsatt overgå sikkerhetsmodeller når klassifiseringsnøyaktighet er det eneste målet.
- Kostnader for beregning og latens: CoT-resonnement øker inferenstid og beregningsforbruk, noe som kompliserer skalering til plattformnivåtrafikk med mindre det er paret med triageklassifikatorer og asynkrone pipelines.
Flerspråklig paritet
gpt-oss-safeguard yter på nivå med de underliggende gpt-oss-modellene på tvers av mange språk i MMMLU-stiltester, noe som indikerer at de finjusterte safeguard-variantene beholder bred resonneringsevne.
Hvordan kan team få tilgang til og distribuere gpt-oss-safeguard?
OpenAI tilbyr vektene under Apache 2.0 og lenker modellene for nedlasting (Hugging Face). Fordi gpt-oss-safeguard er en åpen vektmodell, anbefales lokal og selvstyrt distribusjon (anbefales for personvern og tilpasning).
- Last ned modellvekter (fra OpenAI / Hugging Face) og lagre dem på dine egne servere eller virtuelle skymaskiner. Apache 2.0 tillater modifisering og kommersiell bruk.
- RuntimeBruk standard inferenskjøretider som støtter store transformermodeller (ONNX Runtime, Triton eller optimaliserte leverandørkjøretider). Fellesskapskjøretider som Ollama og LM Studio legger allerede til støtte for gpt-oss-familier.
- maskinvare120B krever vanligvis GPU-er med mye minne (f.eks. 80 GB A100/H100 eller multi-GPU sharding), mens 20B kan kjøres billigere og har alternativer optimalisert for 16 GB VRAM-oppsett. Planlegg kapasitet for topp gjennomstrømning og kostnader for evaluering av flere policyer.
Administrerte og tredjeparts kjøretider
Hvis det er upraktisk å kjøre din egen maskinvare, CometAPI legger raskt til støtte for gpt-oss-modeller. Disse plattformene kan gi enklere skalering, men gjeninnføre avveininger for dataeksponering med tredjeparter. Evaluer personvern, tjenestenivåavtaler og tilgangskontroller før du velger administrerte kjøretider.
Effektive modereringsstrategier med gpt-oss-safeguard
1) Bruk en hybrid pipeline (triage → begrunnelse → vurdering)
- Triage-lag: Små, raske klassifikatorer (eller regler) filtrerer ut trivielle tilfeller. Dette reduserer belastningen på den dyre sikkerhetsmodellen.
- Sikkerhetslag: kjør gpt-oss-safeguard for tvetydige, høyrisiko- eller flerpolicykontroller der policynyanser er viktige.
- Menneskelig vurdering: eskalerer saker og anker på kanten av plattformen, og lagrer CoT som bevis for åpenhet. Denne hybride designen balanserer gjennomstrømning og presisjon.
2) Policy engineering (ikke prompt engineering)
- Behandle policyer som programvareartefakter: versjoner dem, test dem mot datasett og hold dem eksplisitte og hierarkiske.
- Skriv retningslinjer med eksempler og moteksempler. Inkluder tydeliggjørende instruksjoner når det er mulig (f.eks. «Hvis brukerintensjonen er tydelig utforskende og historisk, merk den som X; hvis intensjonen er operasjonell og i sanntid, merk den som Y»).
3) Konfigurer resonneringsinnsatsen dynamisk
- Bruk lav innsats for bulkprosessering og høy innsats for flagget innhold, anker eller vertikaler med stor innvirkning (juridisk, medisin, finans).
- Juster terskler med tilbakemeldinger fra mennesker for å finne det optimale punktet for kostnad/kvalitet.
4) Valider CoT og se etter hallusinerte resonnement
CoT er verdifull, men den kan hallusinere: sporet er en modellgenerert begrunnelse, ikke sannheten på bakken. Revider CoT-utdata rutinemessig; instrumentdetektorer for hallusinerte sitater eller uoverensstemmelser i resonnementet. OpenAI dokumenterer hallusinerte tankekjeder som en observert utfordring og foreslår tiltak for å redusere situasjonen.
5) Bygg datasett fra systemdrift
Logg modellbeslutninger og menneskelige korrigeringer for å lage merkede datasett som kan forbedre triageklassifiseringer eller informere omskrivinger av policyer. Over tid reduserer et lite, merket datasett av høy kvalitet pluss en effektiv klassifisering ofte avhengigheten av full CoT-inferens for rutineinnhold.
6) Overvåk beregning og kostnader; bruk asynkrone flyter
For forbrukerrettede applikasjoner med lav latens, bør du vurdere asynkrone sikkerhetskontroller med en kortsiktig konservativ brukeropplevelse (f.eks. midlertidig skjul innhold i påvente av gjennomgang) i stedet for å utføre høyinnsatsskrevende CoT synkront. OpenAI bemerker at Safety Reasoner bruker asynkrone flyter internt for å administrere latens for produksjonstjenester.
7) Vurder personvern og distribusjonssted
Fordi vektene er åpne, kan du kjøre inferens helt lokalt for å overholde streng datastyring eller redusere eksponering for tredjeparts API-er – verdifullt for regulerte bransjer.
Konklusjon:
gpt-oss-safeguard er et praktisk, transparent og fleksibelt verktøy for policydrevet sikkerhetsresonnementDen skinner når du trenger det reviderbare beslutninger knyttet til eksplisitte retningslinjer, når retningslinjene dine endres ofte, eller når du ønsker å holde sikkerhetskontroller på stedet. Det er ikke en mirakelkur som automatisk vil erstatte spesialiserte klassifikatorer med høyt volum – OpenAIs egne evalueringer viser at dedikerte klassifikatorer trent på store merkede korpora kan utkonkurrere disse modellene på rå nøyaktighet for smale oppgaver. Behandle i stedet gpt-oss-safeguard som en strategisk komponent: den forklarbare resonneringsmotoren i hjertet av en lagdelt sikkerhetsarkitektur (rask triage → forklarbar resonnering → menneskelig tilsyn).
Komme i gang
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører – som OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering, forenkler CometAPI dramatisk integreringen av AI-funksjoner i applikasjonene dine. Enten du bygger chatboter, bildegeneratorer, musikkomponister eller datadrevne analysepipeliner, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig – alt samtidig som du utnytter de nyeste gjennombruddene på tvers av AI-økosystemet.
Den nyeste integrasjonen gpt-oss-safeguard vil snart dukke opp på CometAPI, så følg med! Mens vi ferdigstiller opplastingen av gpt-oss-safeguard-modellen, kan utviklere få tilgang. GPT-OSS-20B API og GPT-OSS-120B API gjennom Comet API, den nyeste modellversjonen er alltid oppdatert med den offisielle nettsiden. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.
Klar til å dra? → Registrer deg for CometAPI i dag !
Hvis du vil vite flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!