
grok-kode-rask-1 er xAIs hastighetsfokusert, kostnadseffektiv agentkodingsmodell utviklet for å drive IDE-integrasjoner og automatiserte kodeagenter. Den legger vekt på lav latency, agentisk atferd (verktøykall, trinnvise resonneringsspor) og en kompakt kostnadsprofil for daglige utviklerarbeidsflyter.
Viktige funksjoner (i korte trekk)
- Høy gjennomstrømning / lav latens: fokusert på veldig rask token-utdata og raske fullføringer for IDE-bruk.
- Agentisk funksjonskall og verktøy: støtter funksjonskall og ekstern verktøyorkestrering (kjør tester, linters, filhenting) for å aktivere flertrinns kodeagenter.
- Stort kontekstvindu: designet for å håndtere store kodebaser og kontekster med flere filer (leverandører lister opp 256k kontekstvinduer i markedsplassadaptere).
- Synlig resonnement / spor: Svar kan inkludere trinnvise resonnementsspor som er ment å gjøre agentbeslutninger inspiserbare og feilsøkbare.
Tekniske detaljer
Arkitektur og opplæring: xAI sier at grok-code-fast-1 ble bygget fra bunnen av med en ny arkitektur og et før-treningskorpus rikt på programmeringsinnhold; modellen ble deretter kurert etter trening på høykvalitets, virkelige pull-request/kodedatasett. Denne ingeniørpipelinen er rettet mot å lage modellen. praktiske interne arbeidsflyter for agenter (IDE + verktøybruk).
Servering og kontekst: grok-code-fast-1 og typiske bruksmønstre forutsetter strømmingsutganger, funksjonskall og rik kontekstinjeksjon (filopplastinger/-samlinger). Flere skybaserte markedsplasser og plattformadaptere lister det allerede opp med stor kontekststøtte (256 000 kontekster i noen adaptere).
Brukervennlighetsfunksjoner: Synlig spor av resonnement (modellen viser planleggings-/verktøybruken), veiledning for rask utvikling og eksempelintegrasjoner, og integrasjoner med tidlige lanseringspartnere (f.eks. GitHub Copilot, Cursor).
Referanseytelse (hva den scorer på)
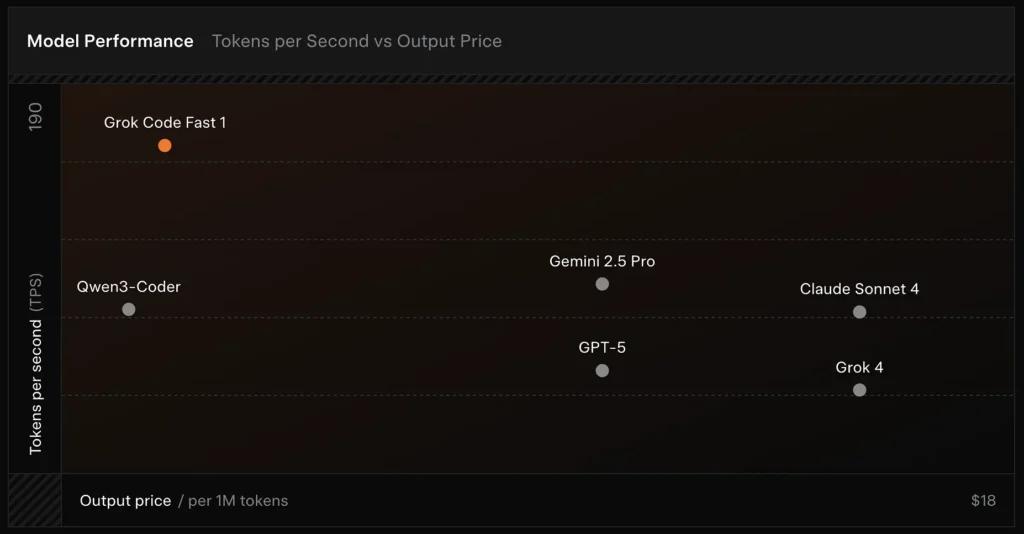
SWE-Bench-verifisert: xAI rapporterer en 70.8% poengsum på deres interne sele over SWE-Bench-Verified-delsettet – en referanseindeks som ofte brukes til sammenligninger av programvareutviklingsmodeller. En nylig praktisk evaluering rapporterte en gjennomsnittlig menneskelig vurdering ≈ 7.6 på en blandet kodepakke – konkurrerende med noen verdifulle modeller (f.eks. Gemini 2.5 Pro), men hengende etter større multimodale/«best-resonnerende» modeller som Claude Opus 4 og xAIs egen Grok 4 på vanskelighetsgradige resonneringsoppgaver. Referanseverdier viser også variasjon etter oppgave: utmerket for vanlige feilrettinger og konsis kodegenerering, svakere på noen nisje- eller bibliotekspesifikke problemer (Tailwind CSS-eksempel).
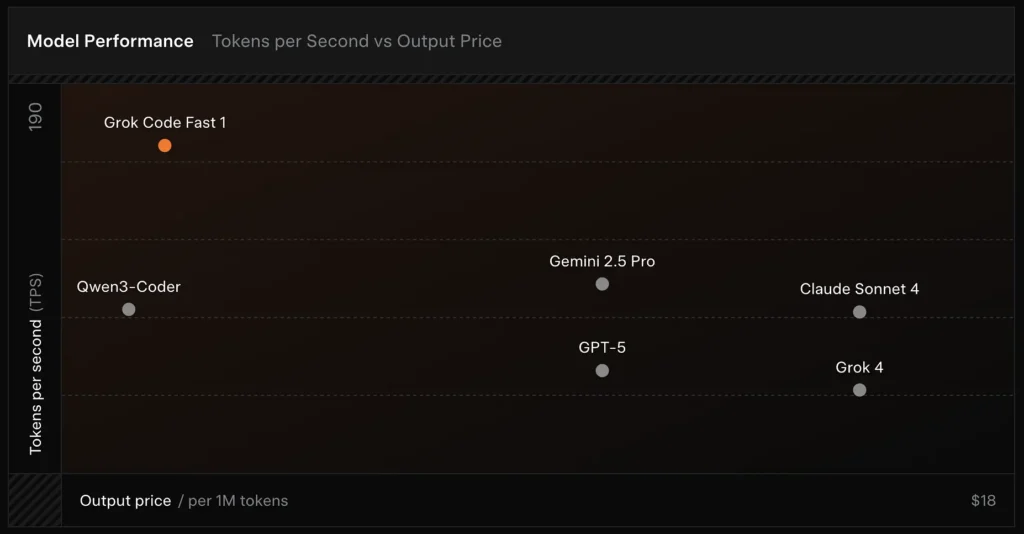
Sammenligning:
- mot Grok 4: Grok-code-fast-1 bytter bort absolutt korrekthet og dypere resonnement for mye lavere kostnad og raskere gjennomstrømningGrok 4 er fortsatt alternativet med høyere kapasitet.
- mot Claude Opus / GPT-klassen: Disse modellene leder ofte an i komplekse, kreative eller vanskelige resonneringsoppgaver; Grok-code-fast-1 konkurrerer godt på rutinemessige utvikleroppgaver med stort volum der latens og kostnad er viktig.
Begrensninger og risikoer
Praktiske begrensninger observert så langt:
- Domenehull: ytelsesdipp på nisjebiblioteker eller uvanlig innrammede problemer (eksempler inkluderer Tailwind CSS-kanttilfeller).
- Avveining mellom resonnement og tokenkostnad: Fordi modellen kan sende ut interne resonnementstokener, kan svært agentisk/utførlig resonnement øke lengden (og kostnaden) på utgangen av slutninger.
- Nøyaktighet / kanttilfeller: Grok-code-fast-1 er sterk på rutineoppgaver, men hallusinere eller produsere feil kode for nye algoritmer eller motstridende problemstillinger; det kan underprestere toppmodeller fokusert på resonnement på krevende algoritmiske referansepunkter.
Typiske brukstilfeller
- IDE-assistanse og rask prototyping: raske fullføringer, trinnvis kodeskriving og interaktiv feilsøking.
- Automatiserte agenter / kodearbeidsflyter: agenter som orkestrerer tester, kjører kommandoer og redigerer filer (f.eks. CI-hjelpere, bot-anmeldere).
- Daglige ingeniøroppgaver: generering av kodeskjeletter, refaktorering, forslag til feilsortering og stillasbygging av prosjekter med flere filer der lav latens vesentlig forbedrer utviklerflyten.
Hvordan kalle grok-code-fast-1 API fra CometAPI
grok-code-fast-1 API-priser i CometAPI, 20 % avslag på den offisielle prisen:
- Inndata-tokens: $0.16/M tokens
- Output tokens: $2.0/M tokens
Nødvendige trinn
- Logg på cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
- Få tilgangslegitimasjons-API-nøkkelen til grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
Bruk metoden
- Velg "
grok-code-fast-1” endepunkt for å sende API-forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsteksten er hentet fra vårt API-dokument for nettstedet vårt. Vårt nettsted gir også Apifox-test for din bekvemmelighet. - Erstatt med din faktiske CometAPI-nøkkel fra kontoen din.
- Sett inn spørsmålet eller forespørselen din i innholdsfeltet – det er dette modellen vil svare på.
- . Behandle API-svaret for å få det genererte svaret.
CometAPI tilbyr et fullt kompatibelt REST API – for sømløs migrering. Viktige detaljer for API-dok:
- Grunnadresse: https://api.cometapi.com/v1/chat/completions
- Modellnavn: "
grok-code-fast-1" - Autentisering: Bærertoken via
Authorization: Bearer YOUR_CometAPI_API_KEYheader - Innholdstype:
application/json.
API-integrasjon og eksempler
Python-kodebit for en Chatfullføring kall gjennom CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Se også Grok 4