

GLM-5 er Zhipu AIs nye open-weight, agent-sentriske grunnlagsmodell bygget for langsiktig koding og flerstegs-agenter. Den er tilgjengelig via flere hostede API-er (inkludert CometAPI og leverandørendepunkter) og som en forskningsutgivelse med kode og vekter; du kan integrere den med standard OpenAI-kompatible REST-kall, strømming og SDK-er.
Hva er GLM-5 fra Z.ai?
GLM-5 er Z.ai sin femte generasjons flaggskip-grunnlagsmodell designet for agentisk ingeniørarbeid: planlegging over lang horisont, flerstegs verktøybruk og storstilt kode-/systemdesign. Offentlig lansert i februar 2026, er GLM-5 en Mixture-of-Experts (MoE)-modell med ~744 milliarder totale parametere og et aktivt parametersett i 40B-området per fremoverpass; arkitektur- og treningsvalg prioriterer lang-kontekst-koherens, verktøy-kalling og kostnadseffektiv inferens for produksjonsarbeidslaster. Disse designvalgene gjør at GLM-5 kan kjøre utvidede agentiske arbeidsflyter (for eksempel: browse → plan → skriv/test kode → iterer) samtidig som konteksten bevares over svært lange input.
Viktige tekniske høydepunkter :
- MoE-arkitektur på ~744B totalt / ~40B aktive parametere; skalert pretrening (~28.5T tokens rapportert) for å redusere gapet til de fremste lukkede modellene.
- Lang-kontekststøtte og optimaliseringer (deep sparse attention, DSA) for redusert driftskostnad sammenlignet med naiv tett skalering.
- Innebygde agentiske funksjoner: verktøy-/funksjonskalling, tilstandfulle økter og integrerte utdata (kan produsere
.docx,.xlsx,.pdf-artefakter som del av agent-arbeidsflyter i leverandørers UI-er). - Åpne vekter tilgjengelig (vekter publisert til modellnav) og hostede tilgangsalternativer (leverandør-API-er, inferens-mikrotjenester).
Hva er de viktigste fordelene med GLM-5?
Agentisk planlegging og minne over lange horisonter
GLM-5s arkitektur og tuning prioriterer konsistent flerstegsresonnement og minne på tvers av arbeidsflyter — en fordel for:
- autonome agenter (CI-pipelines, oppgaveorkestratorer),
- stor kodegenerering/refaktorering på tvers av mange filer, og
- dokumentintelligens som må holde på lange historikker.
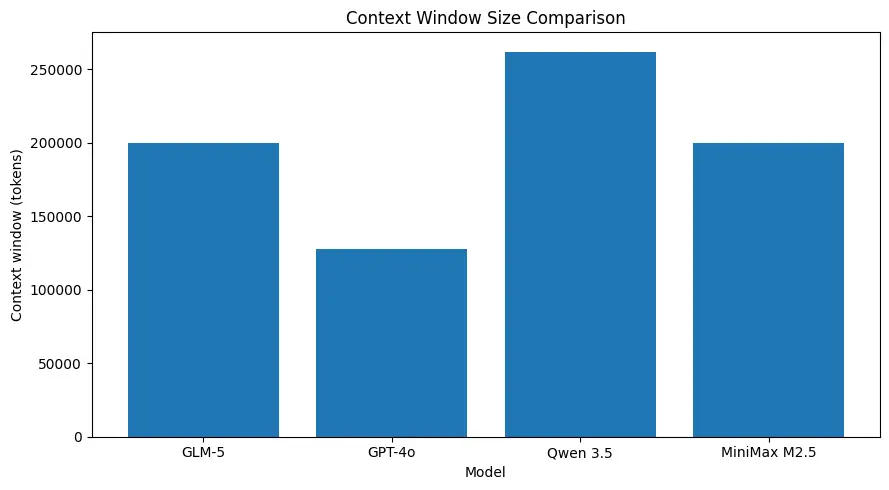
Store kontekstvinduer
GLM-5 støtter svært store kontekster (omtrent ~200k tokens i publiserte modellspecs), slik at du kan beholde mer av en økt i én forespørsel og redusere behovet for aggressiv oppdeling eller ekstern hukommelse for mange brukstilfeller. (Se sammenligningstabellen nedenfor.)
Sterk kodeytelse for systemnivå-oppgaver
GLM-5 rapporterer topp åpen-kilde-ytelse på programvareingeniør-benchmarker (SWE-bench og anvendte kode- + agent-suiter). På SWE-bench-Verified rapporteres ~77.8%; på kode-/terminal-stil agenttester (Terminal-Bench 2.0) ligger scorene på midten av 50-tallet — evidens på praktisk kodeevne som nærmer seg de fremste proprietære modellene. Disse metrikkene betyr at GLM-5 egner seg for oppgaver som kodegenerering, automatisert refaktorering, resonnering på tvers av flere filer og CI/CD-assistent-scenarier.
Avveiinger mellom kostnad og effektivitet
Fordi GLM-5 bruker MoE og «sparse»-oppmerksomhetsinnovasjoner, tar den sikte på å redusere inferenskostnad per kapabilitet sammenlignet med ren tett skalering. CometAPI tilbyr konkurransedyktige prisnivåer som gjør GLM-5 attraktiv for agentiske arbeidslaster med høy gjennomstrømning.
Hvordan bruker jeg GLM-5-API-et via CometAPI?
Kort svar: behandle CometAPI som en OpenAI-kompatibel gateway — sett base-URL og API-nøkkel, velg glm-5 som modell, og kall chat/completions-endepunktet. CometAPI tilbyr en OpenAI-lignende REST-overflate (endepunkter som /v1/chat/completions) pluss SDK-er og eksempelprosjekter som gjør migrering trivielt.
Nedenfor er en praktisk, produksjonsorientert kokebok: autentisering, grunnleggende chat-kall, strømming, funksjons-/verktøykalling og kostnads-/respons-håndtering.
De grunnleggende trinnene for å få tilgang til GLM-5 via CometAPI er:
- Registrer deg på CometAPI, hent en API-nøkkel.
- Finn nøyaktig modell-ID for GLM-5 i CometAPIs katalog (
"glm-5"avhengig av oppføringen). - Send en autentisert POST-forespørsel til CometAPI chat/completions-endepunktet (OpenAI-stil).
Grunnleggende detaljer (CometAPI-mønstre): plattformen støtter OpenAI-sti-er som https://api.cometapi.com/v1/chat/completions, Bearer-autentisering, model-parameter, system-/brukermeldinger, strømming og både curl-/python-eksempler i dokumentasjonen.
Eksempel: rask Python (requests) chat-fullføring med GLM-5
# Eksempel på Python requests (blokkerende)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # lagre nøkkelen din sikkertURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI-modellidentifikator for GLM-5 "messages": [ {"role": "system", "content": "Du er en hjelpsom DevOps-assistent."}, {"role": "user", "content": "Lag et bash-skript som sikkerhetskopierer /etc daglig og beholder 30 dager."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Eksempel: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Oppsummer det følgende arkitekturdokumentet..." }], "max_tokens": 600 }'
Strømmende svar (praktisk mønster)
CometAPI støtter OpenAI-lignende strømming (SSE / chunked). Den enkleste tilnærmingen i Python er å be om "stream": true og iterere over responsdata etter hvert som de kommer. Dette er viktig når du trenger lav latens og delvis output (bygg sanntids utviklerassistenter, strømmende UI-er).
# Strømming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Skriv et testskjelett for følgende funksjon..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Hver linje er en JSON-del (OpenAI-kompatibel). Parse forsiktig. print(chunk)
Referanse: OpenAI-stil strømming og CometAPI-kompatibilitetsdokumentasjon.
Funksjons-/verktøykalling (hvordan kalle et eksternt verktøy)
GLM-5 støtter funksjons- eller verktøykallingsmønstre som er kompatible med OpenAI-/aggregator-konvensjoner (gatewayen videresender strukturerte funksjonskall i modellresponsen). Eksempelbruk: be GLM-5 kalle et lokalt «run_tests»-verktøy; modellen returnerer en strukturert instruks du kan parse og kjøre.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"Du kan kalle verktøyet 'run_tests' for å kjøre enhetstester."}, {"role":"user","content":"Kjør tester for repo X og oppsummer feil."} ], "functions": [ {"name":"run_tests","description":"Kjør pytest i repoets rotkatalog","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Når modellen returnerer en function_call-payload, kjør verktøyet på serversiden, og før deretter verktøyresultatet tilbake som en melding med rollen "tool" og fortsett samtalen. Dette mønsteret muliggjør sikker verktøyinvokasjon og tilstandfulle agentflyter. Se CometAPIs dokumentasjon og eksempler for konkrete SDK-hjelpere.
Praktiske parametere og tuning
function_call: bruk for å muliggjøre strukturert verktøyinvokasjon og sikrere kjørebaner.
temperature: 0–0,3 for deterministiske systemutdata (kode, infrastruktur), høyere for idémyldring.
max_tokens: sett etter forventet output-lengde; GLM-5 støtter svært lange utdata når den er hostet (leverandørgrenser varierer).
top_p / nucleus-sampling: nyttig for å begrense usannsynlige haler.
stream: true for interaktive UI-er.
GLM-5 sammenlignet med Anthropics Claude Opus og andre toppmodeller
Kort svar: GLM-5 reduserer gapet til de fremste lukkede modellene i agentiske og kode-benchmarker samtidig som den tilbyr åpne vekter for distribusjon og ofte bedre kostnad per token når den hostes av aggregatorer. Nyansen: på noen absolutte kodebenchmarker (SWE-bench, Terminal-Bench-varianter) leder Anthropics Claude Opus (4.5/4.6) fortsatt med noen prosentpoeng i mange publiserte topplister — men GLM-5 er svært konkurransedyktig og overgår mange andre åpne modeller.
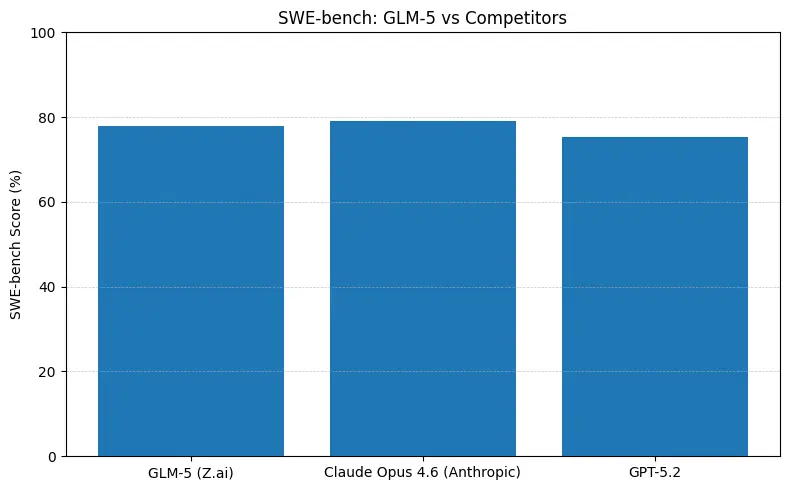
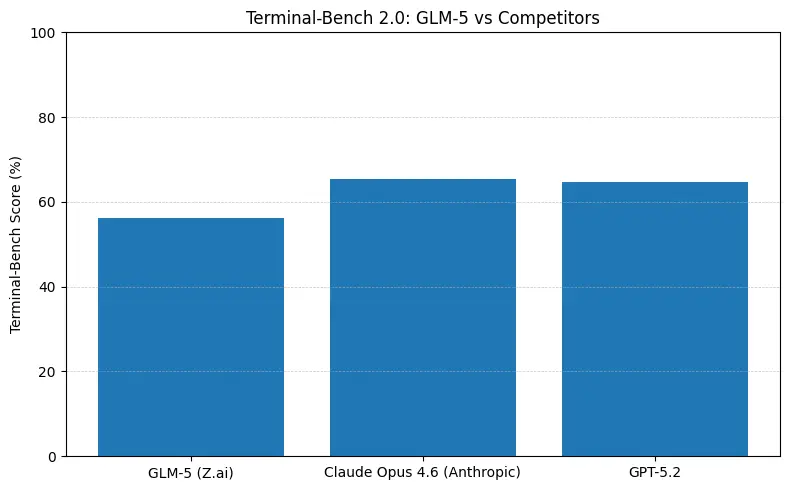
Hva tallene betyr i praksis
- SWE-bench (~kodekorrekthet / ingeniørarbeid): Claude Opus viser en marginal ledelse (≈79% vs GLM-5 ≈77.8%) på publiserte topplister; for mange reelle oppgaver vil det gapet gi færre manuelle endringer, men ikke nødvendigvis et annet arkitekturvalg for prototyping eller skalerte agentiske arbeidsflyter.
- Terminal-Bench (kommandolinje-agentiske oppgaver): Opus 4.6 leder (≈65.4% vs GLM-5 ≈56.2%) — hvis du trenger robust terminalautomatisering og høyest pålitelighet på out-of-distribution shell-operasjoner, er Opus ofte bedre i marginen.
- Agentisk og lang horisont: GLM-5 presterer svært godt på forretningssimuleringer over lang horisont (Vending-Bench 2 saldo $4,432 rapportert) og viser sterk planleggingskoherens for flerstegs arbeidsflyter. Hvis produktet ditt er en langvarig agent (finans, drift), er GLM-5 sterk.
Hvordan utformer jeg prompt og systemer for å få pålitelige GLM-5-utdata?
Systemmeldinger og eksplisitte begrensninger
Gi GLM-5 en streng rolle og klare begrensninger, spesielt for kode- eller verktøykallingsoppgaver. Eksempel:
{"role":"system","content":"Du er GLM-5, en ekspert-ingeniør. Returner konsis, testet Python-kode som følger PEP8 og inkluderer enhetstester."}
Be om tester og kort begrunnelse for hver ikke-trivielle endring.
Del opp komplekse oppgaver
I stedet for «skriv hele produktet», be om:
- designskisse,
- grensesnittsignaturer,
- implementasjon og tester,
- endelig integreringsskript.
Denne stegviseringen reduserer hallusinasjoner og gir deterministiske sjekkpunkter du kan validere.
Bruk lav temperatur for deterministisk kode
Når du ber om kode, sett temperature = 0–0,2 og max_tokens til en trygg øvre grense. For kreativ skriving eller idémyldring, øk temperaturen.
Beste praksis ved integrering av GLM-5 (via CometAPI eller direkte hoster)
Prompt engineering og systemprompter
- Bruk eksplisitte system-instruksjoner som definerer agentroller, retningslinjer for verktøytilgang og sikkerhetsbegrensninger. Eksempel: «Du er systemarkitekt: foreslå kun endringer når enhetstester passerer lokalt; list opp nøyaktige CLI-kommandoer som skal kjøres.»
- For kodeoppgaver, gi repository-kontekst (fillister, nøkkelkodeutdrag) og legg ved enhetstestresultater hvis tilgjengelig. GLM-5s lang-kontekst-håndtering hjelper — men hold alltid essensiell kontekst først (rolle, oppgave) og deretter støttende artefakter.
Økt- og tilstandshåndtering
- Bruk økt-ID-er for lange agentsamtaler og hold en komprimert «hukommelse» over tidligere steg (oppsummeringer) for å unngå kontekstoppblåsing. CometAPI og lignende gateways tilbyr økt-/tilstandshjelpere — men applikasjonsnivå kompakting er essensielt for langvarige agenter.
Verktøy og funksjonskall (sikkerhet + pålitelighet)
- Eksponer et smalt, reviderbart sett med verktøy. Ikke tillat vilkårlig skallekjøring uten menneskelig tilsyn. Bruk strukturerte funksjonsdefinisjoner og valider argumentene på serversiden.
- Logg alltid verktøykall og modellresponser for sporbarhet og etterprøvbar feilanalyse.
Kostnadskontroll og batching
- For agenter med høy volum, rute bakgrunnsprosessering til rimeligere modellvarianter når kvalitetshandelen er akseptabel (CometAPI lar deg bytte modell etter navn). Batch like forespørsler og reduser
max_tokensder det er mulig. Overvåk forholdet mellom input- og output-tokens — output-tokens er ofte dyrere.
Latens- og gjennomstrømningsoptimalisering
- Bruk strømming for interaktive økter. For bakgrunnsagentjobber, foretrekk asynkrone kjøremiljøer, arbeidskøer og rate-limitere. Hvis du selv-hoster (åpne vekter), tun accelerator-topologien din til MoE-arkitekturen — FPGA / Ascend / spesialisert silikon kan gi kostnadsgevinster.
Avsluttende merknader
GLM-5 representerer et praktisk, open-weight steg mot agentisk ingeniørarbeid: store kontekstvinduer, planleggingskapabiliteter og sterk kodeytelse gjør den attraktiv for utviklerverktøy, agentorkestrering og systemnivå-automatisering. Bruk CometAPI for rask integrasjon eller en skybasert modellhage for administrert hosting; valider alltid mot din arbeidslast og instrumenter tungt for kostnads- og hallusinasjonskontroller.
Utviklere kan få tilgang til GLM-5 via CometAPI nå. For å komme i gang, utforsk modellens kapabiliteter i Playground og se API-veiledningen for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du er logget inn på CometAPI og har skaffet API-nøkkelen. CometAPI tilbyr en pris langt lavere enn den offisielle prisen for å hjelpe deg å integrere.
Klar til å starte?→ Registrer deg for M2.5 i dag !
Hvis du vil ha flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!