

Kinas Z.ai (tidligere Zhipu AI) har nok en gang skapt overskrifter med lanseringen av sin åpen kildekode GLM 4.5-serie. GLM-4.5 er posisjonert som et kostnadseffektivt og høytytende alternativ til eksisterende store språkmodeller, og lover å omforme tokenøkonomien og demokratisere tilgangen for både oppstartsbedrifter, bedrifter og forskningsinstitusjoner. Denne omfattende artikkelen utforsker GLM-4.5-seriens opprinnelse, prisstruktur og reelle verdi – og tar for seg de to viktigste spørsmålene alle interessenter tenker på: hvor mye koster det, og er det verdt det?
Hva er GLM 4.5-serien?
Z.ais GLM 4.5-serie er bygget på et «agentisk» AI-rammeverk, som betyr at modellen autonomt kan dekomponere komplekse oppgaver i mindre, sekvensielle deloppgaver – noe som forbedrer presisjonen og reduserer redundant beregning. Dette står i kontrast til mer monolittiske LLM-er som håndterer ledetekster i én omgang. Ifølge Z.ai integrerer GLM 4.5 resonnement og handlingsplanlegging i kjernearkitekturen, noe som muliggjør flertrinns arbeidsflyter som generering av datavisualisering eller ende-til-ende-dokumentbehandling uten ekstern orkestrering.
GLM 4.5-serien, utviklet av Z.ai, representerer den nyeste generasjonen av store språkmodeller med åpen kildekode, Mixture-of-Experts (MoE), som er utformet for å forene avansert resonnement, kodegenerering og agentfunksjoner innenfor én arkitektur. Den kommer i to hovedvarianter: flaggskipet GLM 4.5 (355 B totale parametere, 32 B aktive) og lighteren GLM 4.5‑Air (106 B totalt, 12 B aktive). Begge variantene utnytter en hybrid slutningsmekanisme – «tenkemodus» for kompleks, verktøyaktivert resonnering og «ikke-tenkemodus» for raske og enkle fullføringer – som dekker et bredt spekter av brukstilfeller fra fullstack-utvikling til autonome agentarbeidsflyter.
sentrale tekniske spesifikasjoner:
- ParametreGLM 4.5 har 355 milliarder parametere, med et aktivt delsett på 32 milliarder engasjerte per inferanse for å optimalisere maskinvarebruk og gjennomstrømning.
- **Blanding av eksperter (MoE)**Serien utnytter MoE-arkitektur, og ruter tokens dynamisk til ekspertundernettverk for effektivitet.
- KontekstvinduUtvidet til 128 XNUMX tokens på utvalgte plattformer (f.eks. SiliconFlow), med plass til store dokumenter og kodebaser.
- GenerasjonshastighetHøyhastighetsvarianter overstiger 100 tokens/sek, egnet for sanntidsapplikasjoner.
- Hybride inferensmoduserBrukere kan veksle mellom «tenkemodus» (full MoE-aktivering for dyp resonnering) og «ikke-tenkemodus» (minimal aktivering for raske responser underveis), noe som gir utviklere finjustert kontroll over ytelse kontra hastighet.
Hvilke varianter finnes i serien?
- **GLM 4.5 (Standard)**355 B totalt / 32 B aktive parametere. Primært utviklet for balansert ytelse på tvers av resonnement, koding og agentoppgaver.
- GLM 4.5‑AirEn lettvektsversjon med totalt 106 B / 12 B aktive parametere, skreddersydd for scenarier med strenge maskinvare- eller latensbegrensninger – og leverer konkurransedyktig nøyaktighet i sin klasse.
Hvor mye koster GLM 4.5-serien?
Hva er prisene på input- og output-tokens?
I følge Z.ais offentlige API-prisopplysninger er GLM 4.5 priset til:
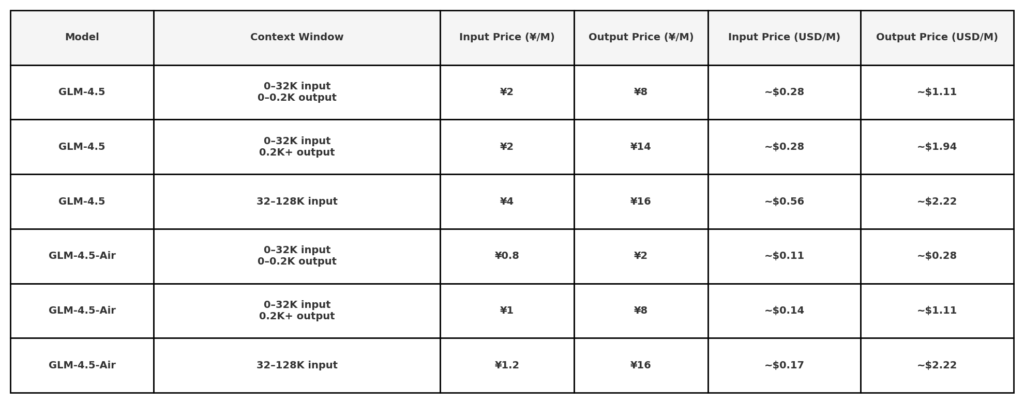
Merk: Svært lave priser ($0.11/$0.28) kan være begrenset til korte tokenlengder eller spesifikke kampanjer. 50 % rabatt på alle modeller i en begrenset periode, gyldig til 31. august 2025. Andre modeller, se prisside for kontor.
På CometAPI leveres serien med litt forskjellige nivåbaserte priser, se GLM‑4.5 API:
| Modell | introdusere | Pris |
glm-4.5 | Vår kraftigste resonneringsmodell, med 355 milliarder parametere | Inndatatokener $0.48 Utdatatokens $1.92 |
glm-4.5-air | Kostnadseffektiv Lettvekt Sterk Ytelse | Inndatatokener $0.16 Utdatatokens $1.07 |
glm-4.5-x | Høy ytelse, sterk resonnering, ultrarask respons | Inndatatokener $1.60 Utdatatokens $6.40 |
glm-4.5-airx | Lettvekt Sterk ytelse Ultrarask respons | Inndatatokener $0.02 Utdatatokens $0.06 |
glm-4.5-flash | Sterk ytelse Utmerket for resonnering, koding og agenter | Inndatatokener $3.20 Utdatatokens $12.80 |
Hvordan er prisene på GLM 4.5 sammenlignet med DeepSeek og Western LLMs?
På verdenskonferansen for AI i 2025 posisjonerte Z.ai eksplisitt GLM 4.5 som en utfordrer til DeepSeek – den tidligere kostnadslederen i Kina – og lovet «en brøkdel av tokenkostnaden» og halvparten av maskinvareavtrykket til DeepSeeks R1-modell.
- DeepSeek R1Omtrent 0.14 USD i input, 0.60 USD i output per million tokens.
- GLM 4.5: Hevdes å underby DeepSeek med 20–30 % på både input og output.
- Vestlige referansepunkterOpenAIs GPT-4 og Googles Gemini koster fra 3–15 USD per million tokens, noe som posisjonerer GLM 4.5 som en betydelig kostnadsreduksjon.
Denne prisstrategien gjenspeiler Kinas bredere økonomiske modell for kunstig intelligens: slankere databehandling, mindre modeller og aggressiv underprising for å vinne markedsandeler.
Er GLM 4.5-serien verdt det?
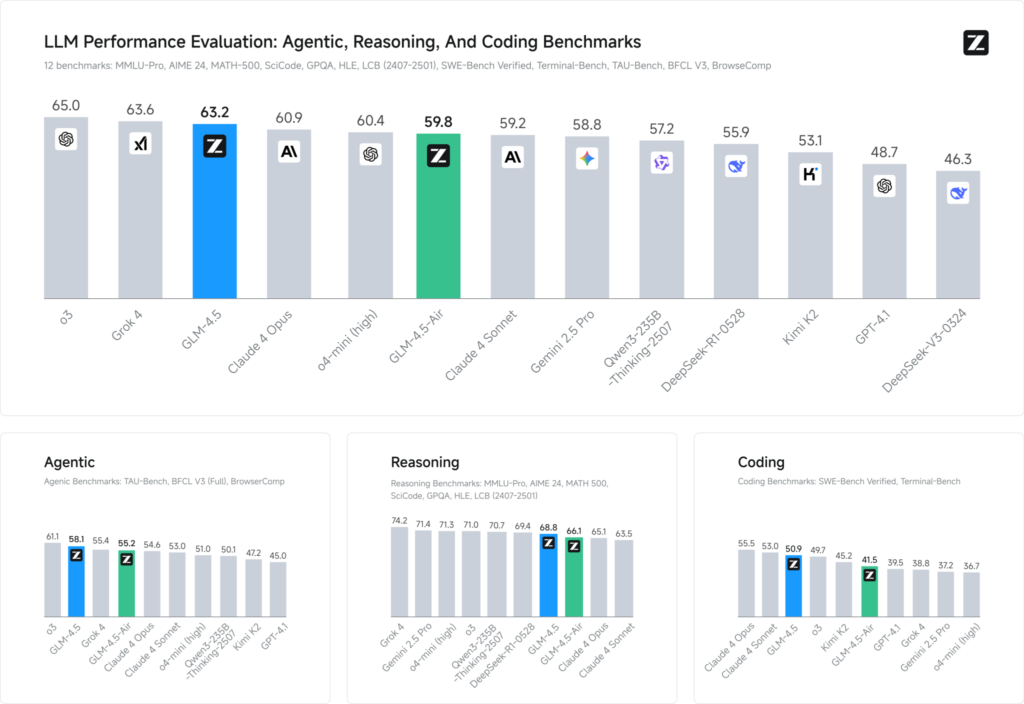
Referanseevalueringer på tvers av 12 representative datasett (som spenner over MMLU Pro, MATH 500, SciCode, Terminal-Bench og TAU-Bench) avslører at GLM 4.5 sikrer en global #3-rangering bak xAIs Grok 4 og OpenAIs o3 – men likevel rangerer som nummer 1 blant åpen kildekode-tilbud.
I kodeoppgaver (LiveCodeBench, SWE-Bench) bidrar GLM 4.5s Mixture-of-Experts-design til førsteklasses kodegenereringskvalitet, mens i resonnering (AIME 24, MMLU Pro) gir flertrinnsplanleggingen robust nøyaktighet sammenlignbar med motparter i lukket kildekode. Den lette Air-varianten opprettholder konkurransedyktige poengsummer innenfor parametergruppen (100 B-skala), noe som gjør den til et fristende valg for edge-distribusjoner og innebygde systemer.
Performance Benchmarks
- IntelligensindeksGLM 4.5-poeng 66 på en sammensatt intelligensindeks (MMLU Pro, MATH 500, AIME 24), som overgår mange åpen kildekode- og kommersielle mellomnivåmodeller.
- InferenslatensGjennomsnitt for tid til første token 0.89 sekunder, konkurransedyktig for komplekse resonneringsoppgaver, men noe lavere i gjennomstrømning (≈45.7 tokens/s) sammenlignet med noen optimaliserte modeller med lukket kildekode.
- AgentarbeidsflytDemonstrerer robust beherskelse av flertrinnsverktøybruk og dynamisk kodegenerering, med direkte seiersrater på ~54 % mot Kimi K2 og 81 % mot Qwen3‑Coder i uavhengige kodeevalueringer.
Hvilke praktiske brukstilfeller viser avkastning på investeringen?
- Fullstack-utviklingGLM-4.5 kan stillase hele webapplikasjoner – fra frontend-layouter i HTML/CSS/JavaScript til backend-databaseskjemaer – gjennom flertrinnsledetekster, og redusere prototypesykluser fra dager til timer.
- Kompleks dokumentanalyseDet utvidede kontekstvinduet på 128 K gir juridiske, finansielle og vitenskapelige firmaer muligheten til å analysere flersiders kontrakter eller forskningsrapporter i én omgang, noe som reduserer segmenteringskostnader.
- Automatiserte agentarbeidsflyterHybrid inferens tillater opprettelse av autonome skript (f.eks. webskrapingsroboter, handelsagenter) som resonnerer gjennom flertrinnsprosesser med minimal menneskelig inngripen.
Kvantitative casestudier antyder opptil 60 prosent reduksjon i utviklertimer for kodesentriske oppgaver og 40 prosent raskere behandlingstid på langformatinnholdsanalyse.
Hva er de potensielle ulempene og hensynene?
Ingen teknologi er uten avveininger. Potensielle brukere bør være oppmerksomme på regulatoriske, driftsmessige og økosystemmessige faktorer.
Begrensninger
Støtte og tjenestenivåavtalerLeverandører av åpen kildekode tilbyr kanskje ikke tjenestenivåavtaler på bedriftsnivå eller døgnåpen support, i motsetning til kommersielle motparter.
GjennomstrømningsbegrensningerSelv om kontekstvinduet er enormt, henger token-per-sekund-hastighetene bak noen slutningsoptimaliserte motparter med lukket kildekode, noe som potensielt påvirker sanntidsapplikasjoner.
DriftsoverheadSelvhostende MoE-modeller krever nøye orkestrering (ekspertruting, minnehåndtering) for å unngå ytelsesflaskehalser og kostnadsoverskridelser.
Hvilke infrastrukturinvesteringer er nødvendige?
- Beregn fotavtrykk: Selv med MoE-effektivitet krever hosting av GLM-4.5s standardvariant GPU-er med ≥80 GB minne og robuste NVLink-sammenkoblinger for slutning med lav latens.
- Finjustering av overheadkostnader: Tilpassing av modellen for domenespesifikke oppgaver kan kreve betydelige GPU-sykluser, noe som øker de oppstartskostnadene før besparelser på tokenfakturering realiseres.
- Vedlikehold: Lokale implementeringer flytter ansvaret for oppdateringer, sikkerhetsoppdateringer og skalering fra leverandøren til interne DevOps-team.
Hvordan kan du komme i gang med GLM-4.5?
Å starte en GLM-4.5-integrasjon innebærer noen få enkle trinn – spesielt gitt den åpne kildekode-strategien og den omfattende tredjepartsstøtten.
Hvilke API-er og plattformer støtter GLM-4.5?
- CometAPI APIFullstendig OpenAI-kompatibelt endepunkt, med SDK-er i Python, JavaScript og Java.
- Direkte Z.ai-endepunktTilbyr offisiell støtte og tidlig tilgangsfunksjoner som orkestrering med flere agenter.
- FellesskapsspeilRaskt voksende mengde åpen kildekode-kjøretider (f.eks. Ollama, AutoGPT-CLI) som muliggjør lokal inferens.
Hvor kan utviklere finne verktøy og dokumentasjon?
- Z.ai offisielle dokumenter: Omfattende veiledninger om installasjon, rask prosjektering og MoE-optimalisering.
- GitHub Repositories: Eksempelnotatbøker for kodegenerering, henting-utvidet generering (RAG) og agentrammeverk som er kompatible med store orkestreringsverktøy.
- Fellesskapsfora: Aktive diskusjonsforum på plattformer som Hugging Face, hvor utøvere deler finjusteringsoppskrifter, biblioteker med spørsmål og ytelsestester.
Konklusjon
GLM-4.5-serien setter et dristig krav i dagens hyperkonkurransepregede AI-landskap: uovertruffen kostnadsytelse for både utviklere, bedrifter og forskningsinstitusjoner. Med tokenpriser så lave som 0.11 dollar per million input-tokens og 0.28 dollar per million output-tokens – ytterligere redusert med en 50 prosent kampanjerabatt – og benchmark-ytelse som konkurrerer med eller overgår større proprietære modeller, leverer GLM-4.5 betydelig avkastning på investeringen for kodesentriske applikasjoner, langsiktig forståelse og agentiske arbeidsflyter.
Komme i gang
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører – som OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering, forenkler CometAPI dramatisk integreringen av AI-funksjoner i applikasjonene dine. Enten du bygger chatboter, bildegeneratorer, musikkomponister eller datadrevne analysepipeliner, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig – alt samtidig som du utnytter de nyeste gjennombruddene på tvers av AI-økosystemet.
Utviklere har tilgang GLM-4.5 Air API og GLM‑4.5 API gjennom CometAPI, de nyeste Claude Models-versjonene som er oppført er per artikkelens publiseringsdato. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.