

I 2025–2026 fortsatte AI-verktøylandskapet å konsolidere seg: gateway-API-er (som CometAPI) ble utvidet for å gi OpenAI-lignende tilgang til hundrevis av modeller, mens sluttbruker-LLM-apper (som AnythingLLM) fortsatte å forbedre sin «Generic OpenAI»-leverandør slik at desktop- og local-first-apper kan kalle ethvert OpenAI-kompatibelt endepunkt. Det gjør det i dag enkelt å rute AnythingLLM-trafikk gjennom CometAPI og få fordelene med modellvalg, kostnadsruting og samlet fakturering — samtidig som du fortsatt bruker AnythingLLMs lokale UI og RAG-/agentfunksjoner.
Hva er AnythingLLM, og hvorfor vil du koble det til CometAPI?
Hva er AnythingLLM?
AnythingLLM er en åpen kildekode-basert, alt-i-ett AI-applikasjon og lokal/skylient for å bygge chatassistenter, retrieval-augmented generation (RAG)-arbeidsflyter og LLM-drevne agenter. Den tilbyr et elegant UI, et utvikler-API, arbeidsområde-/agentfunksjoner og støtte for lokale og skybaserte LLM-er — designet for å være privat som standard og utvidbar via plugins. AnythingLLM eksponerer en Generic OpenAI-leverandør som lar den kommunisere med OpenAI-kompatible LLM-API-er.
Hva er CometAPI?
CometAPI er en kommersiell API-aggregeringsplattform som eksponerer 500+ AI-modeller gjennom ett OpenAI-lignende REST-grensesnitt og samlet fakturering. I praksis lar den deg kalle modeller fra flere leverandører (OpenAI, Anthropic, Google/Gemini-varianter, bilde-/lydmodeller osv.) via de samme endepunktene https://api.cometapi.com/v1 og én enkelt API-nøkkel (format sk-xxxxx). CometAPI støtter standard OpenAI-lignende endepunkter som /v1/chat/completions, /v1/embeddings osv., noe som gjør det enkelt å tilpasse verktøy som allerede støtter OpenAI-kompatible API-er.
Hvorfor integrere AnythingLLM med CometAPI?
Tre praktiske grunner:
- Modellvalg og leverandørfleksibilitet: AnythingLLM kan bruke «enhver OpenAI-kompatibel» LLM via sin Generic OpenAI-wrapper. Hvis du peker denne wrapperen mot CometAPI, får du umiddelbar tilgang til hundrevis av modeller uten å endre AnythingLLMs UI eller flyter.
- Kostnads-/driftsoptimalisering: Ved å bruke CometAPI kan du bytte modeller (eller nedskalere til rimeligere modeller) sentralt for kostnadskontroll, og beholde samlet fakturering i stedet for å håndtere flere leverandørnøkler.
- Raskere eksperimentering: Du kan A/B-teste ulike modeller (f.eks.
gpt-4o,gpt-4.5, Claude-varianter eller åpne multimodale modeller) via det samme AnythingLLM-UI-et — nyttig for agenter, RAG-svar, oppsummering og multimodale oppgaver.
Hvilket miljø og hvilke betingelser må du forberede før integrering?
System- og programvarekrav (på høyt nivå)
- Desktop eller server som kjører AnythingLLM (Windows, macOS, Linux) — desktopinstallasjon eller selvhostet instans. Bekreft at du bruker en nyere build som eksponerer innstillingene LLM Preferences / AI Providers.
- CometAPI-konto og en API-nøkkel (hemmeligheten i
sk-xxxxx-stil). Du vil bruke denne hemmeligheten i AnythingLLMs Generic OpenAI-leverandør. - Nettverkstilkobling fra maskinen din til
https://api.cometapi.com(ingen brannmur som blokkerer utgående HTTPS). - Valgfritt, men anbefalt: et moderne Python- eller Node-miljø for testing (Python 3.10+ eller Node 18+), curl og en HTTP-klient (Postman / HTTPie) for å sanity-sjekke CometAPI før du kobler det til AnythingLLM.
AnythingLLM-spesifikke betingelser
LLM-leverandøren Generic OpenAI er den anbefalte ruten for endepunkter som etterligner OpenAIs API-flate. AnythingLLMs dokumentasjon advarer om at denne leverandøren er utviklerfokusert, og at du bør forstå inputene du oppgir. Hvis du bruker streaming eller endepunktet ditt ikke støtter streaming, inkluderer AnythingLLM en innstilling for å deaktivere streaming for Generic OpenAI.
Sikkerhets- og driftsjekkliste
- Behandle CometAPI-nøkkelen som enhver annen hemmelighet — ikke commit den til repos; lagre den i OS-nøkkelringer eller miljøvariabler der det er mulig.
- Hvis du planlegger å bruke sensitive dokumenter i RAG, må du forsikre deg om at personvern- og sikkerhetsgarantiene for endepunktet oppfyller dine compliance-behov (sjekk CometAPIs dokumentasjon/vilkår).
- Bestem maks tokens og kontekstvindugrenser for å forhindre ukontrollerte kostnader.
Hvordan konfigurerer du AnythingLLM til å bruke CometAPI (trinn for trinn)?
Nedenfor følger en konkret trinnsekvens — etterfulgt av eksempel på miljøvariabler og kodebiter for å teste tilkoblingen før du lagrer innstillingene i AnythingLLM-UI-et.
Trinn 1 — Hent CometAPI-nøkkelen din
- Registrer deg eller logg inn på CometAPI.
- Gå til «API Keys» og generer en nøkkel — du får en streng som ser ut som
sk-xxxxx. Hold den hemmelig.
Trinn 2 — Verifiser at CometAPI fungerer med en rask forespørsel
Bruk curl eller Python til å kalle et enkelt chat completion-endepunkt for å bekrefte tilkobling.
Curl-eksempel
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-xxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o",
"messages": ,
"max_tokens": 50
}'
Hvis dette returnerer en 200 og et JSON-svar med en choices-matrise, fungerer nøkkelen og nettverket ditt. (CometAPIs dokumentasjon viser den OpenAI-lignende API-flaten og endepunktene).
Python-eksempel (requests)
import requests
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": "Bearer sk-xxxxx", "Content-Type": "application/json"}
payload = {
"model": "gpt-4o",
"messages": ,
"max_tokens": 64
}
r = requests.post(url, json=payload, headers=headers, timeout=15)
print(r.status_code, r.json())
Trinn 3 — Konfigurer AnythingLLM (UI)
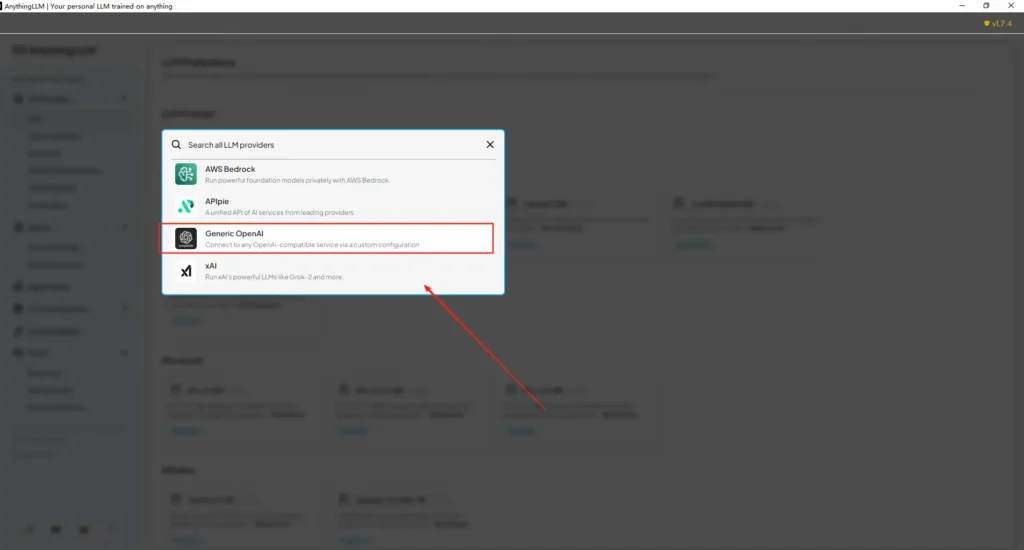
Åpne AnythingLLM → Settings → AI Providers → LLM Preferences (eller lignende sti i din versjon). Bruk leverandøren Generic OpenAI og fyll inn feltene slik:
API-konfigurasjon (eksempel)
• Gå inn i AnythingLLMs innstillingsmeny, og finn LLM Preferences under AI Providers.
• Velg Generic OpenAI som modellleverandør, og skriv innhttps://api.cometapi.com/v1i URL-feltet.
• Lim innsk-xxxxxfra CometAPI i feltet for API-nøkkel. Fyll inn Token context window og Max Tokens i henhold til den faktiske modellen. Du kan også tilpasse modellnavn på denne siden, for eksempel ved å legge til modellengpt-4o.
Dette samsvarer med AnythingLLMs veiledning for «Generic OpenAI» (utvikler-wrapper) og CometAPIs OpenAI-kompatible base-URL-tilnærming.
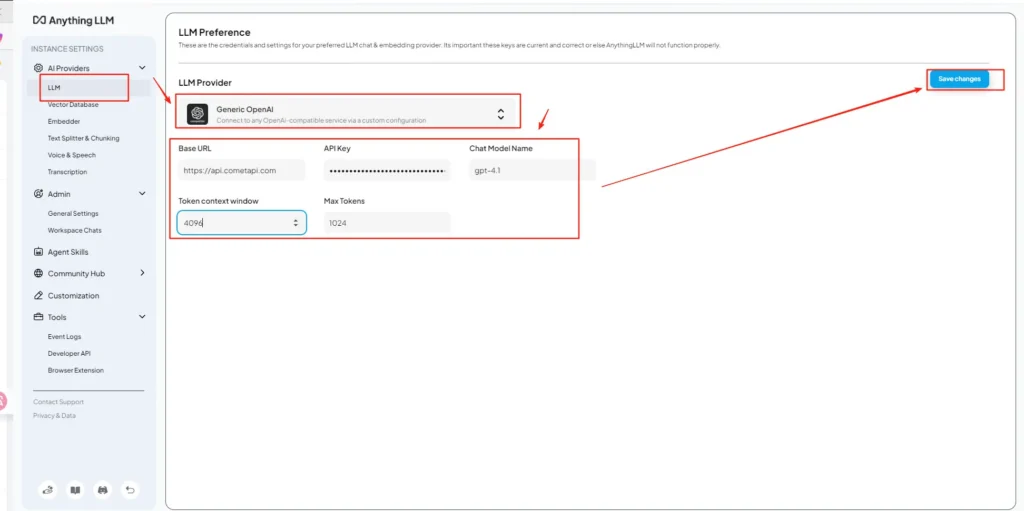
Trinn 4 — Angi modellnavn og token-grenser
På samme innstillingsskjerm legger du til eller tilpasser modellnavn nøyaktig slik CometAPI publiserer dem (f.eks. gpt-4o, minimax-m2, kimi-k2-thinking), slik at AnythingLLM-UI-et kan presentere disse modellene for brukerne. CometAPI publiserer modellstrenger for hver leverandør.
Trinn 5 — Test i AnythingLLM
Start en ny chat eller bruk et eksisterende arbeidsområde, velg Generic OpenAI-leverandøren (hvis du har flere leverandører), velg ett av CometAPI-modellnavnene du la til, og kjør en enkel prompt. Hvis du får sammenhengende completions, er integrasjonen på plass.
Hvordan AnythingLLM bruker disse innstillingene internt
AnythingLLMs Generic OpenAI-wrapper bygger OpenAI-lignende forespørsler (/v1/chat/completions, /v1/embeddings), så når du har angitt base-URL og oppgitt CometAPI-nøkkelen, vil AnythingLLM rute chatter, agentkall og embedding-forespørsler gjennom CometAPI transparent. Hvis du bruker AnythingLLM-agenter (@agent-flytene), vil de arve samme leverandør.
Hva er beste praksis og mulige fallgruver?
Beste praksis
- Bruk modelltilpassede kontekstinnstillinger: Match AnythingLLMs Token Context Window og Max Tokens med modellen du velger i CometAPI. Uoverensstemmelser fører til uventet trunkering eller mislykkede kall.
- Sikre API-nøklene dine: Lagre CometAPI-nøkler i miljøvariabler og/eller Kubernetes/secret manager; legg dem aldri inn i git. AnythingLLM lagrer nøkler i sine lokale innstillinger hvis du skriver dem inn i UI-et — behandle vertslagringen som sensitiv.
- Start med rimeligere / mindre modeller for eksperimentflyter: Bruk CometAPI til å prøve modeller med lavere kostnad under utvikling, og reserver premiummodeller til produksjon. CometAPI reklamerer eksplisitt med kostnadsbytte og samlet fakturering.
- Overvåk bruk og sett varsler: CometAPI tilbyr bruksdashbord — sett budsjetter/varsler for å unngå uventede regninger.
- Test agenter og verktøy isolert: AnythingLLM-agenter kan utløse handlinger; test dem med trygge promter og på staging-instanser først.
Vanlige fallgruver
- Konflikter mellom UI og
.env: Ved selvhosting kan UI-innstillinger overskrive.env-endringer (og omvendt). Sjekk den genererte/app/server/.envhvis ting tilbakestilles etter omstart. Community-saker rapporterer atLLM_PROVIDERtilbakestilles. - Mangler i modellnavn: Bruk av et modellnavn som ikke er tilgjengelig på CometAPI, vil føre til 400/404 fra gatewayen. Bekreft alltid tilgjengelige modeller i CometAPIs modelliste.
- Token-grenser og streaming: Hvis du trenger streamingsvar, må du verifisere at CometAPI-modellen støtter streaming (og at AnythingLLMs UI-versjon støtter det). Noen leverandører har ulik streaming-semantikk.
Hvilke praktiske brukstilfeller muliggjør denne integrasjonen?
Retrieval-Augmented Generation (RAG)
Bruk AnythingLLMs dokumentlastere + vektor-DB med CometAPI-LLM-er for å generere kontekstbevisste svar. Du kan eksperimentere med rimelige embedding-modeller + dyrere chatmodeller, eller holde alt på CometAPI for samlet fakturering. AnythingLLMs RAG-flyter er en primær innebygd funksjon.
Agentautomatisering
AnythingLLM støtter @agent-arbeidsflyter (bla gjennom sider, kalle verktøy, kjøre automatiseringer). Ved å rute agentenes LLM-kall gjennom CometAPI får du valg av modeller for kontroll-/tolkningstrinn uten å endre agentkode.
A/B-testing med flere modeller og kostnadsoptimalisering
Bytt modeller per arbeidsområde eller funksjon (f.eks. gpt-4o for produksjonssvar, gpt-4o-mini for utvikling). CometAPI gjør modellbytter enkle og sentraliserer kostnadene.
Multimodale pipelines
CometAPI tilbyr bilde-, lyd- og spesialiserte modeller. AnythingLLMs multimodale støtte (via leverandører) kombinert med CometAPIs modeller muliggjør bildebildebeskrivelser, multimodal oppsummering eller lydtranskripsjonsflyter gjennom det samme grensesnittet.
Konklusjon
CometAPI fortsetter å posisjonere seg som en gateway for flere modeller (500+ modeller, OpenAI-lignende API) — noe som gjør den til en naturlig partner for apper som AnythingLLM, som allerede støtter en Generic OpenAI-leverandør. På samme måte gjør AnythingLLMs Generic-leverandør og nyere konfigurasjonsalternativer det enkelt å koble til slike gateways. Denne konvergensen forenkler eksperimentering og migrering til produksjon i slutten av 2025.
Slik kommer du i gang med Comet API
CometAPI er en samlet API-plattform som aggregerer over 500 AI-modeller fra ledende leverandører — som OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere — i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering forenkler CometAPI integreringen av AI-funksjoner i applikasjonene dine betydelig. Enten du bygger chatboter, bildegeneratorer, musikkkomponister eller datadrevne analysepipelines, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig — samtidig som du tar i bruk de nyeste gjennombruddene i AI-økosystemet.
For å komme i gang kan du utforske modellkapasitetene til CometAPI i Playground og lese API-guiden for detaljerte instruksjoner. Før tilgang må du sørge for at du har logget inn på CometAPI og skaffet deg API-nøkkelen. CometAPI tilbyr en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med integrasjonen.
Klar til å sette i gang?→ Registrer deg for CometAPI i dag !
Hvis du vil vite mer om tips, guider og AI-nyheter, følg oss på VK, X og Discord!