

Kling O1 – utgitt som en del av Kling AIs «Omni»-lanseringsuke – posisjonerer seg som en enkelt, enhetlig multimodal videofundamentmodell som godtar tekst, bilder og videoer i samme forespørsel, og som både kan generere og redigere video i iterative arbeidsflyter på regissørnivå. Klings team omtaler O1 som «verdens første enhetlige multimodale videomodell i stor skala». Klings interne tester hevder betydelige seire sammenlignet med Googles Veo 3.1 og Runway Aleph.
Hva er Kling O1?
Kling O1 (ofte markedsført som Video O1 or Omni One) er en nylig utgitt videogrunnmodell fra Kling AI som forener generering og redigering av tekst, bilder og video i et enkelt, promptdrevet rammeverk. I stedet for å behandle tekst-til-video, bilde-til-video og videoredigering som separate rørledninger, aksepterer Kling O1 blandede input (tekst + flere bilder + valgfri referansevideo) i en enkelt prompt, resonnerer over dem og produserer sammenhengende korte klipp eller redigerer eksisterende opptak med finjustert kontroll. Selskapet posisjonerte utrullingen som en del av en «Omni Launch» og beskriver O1 som en «multimodal videomotor» bygget rundt et Multimodal Visual Language (MVL)-paradigme og en Chain-of-Thought (CoT) resonneringsvei for å tolke komplekse, flerdelte kreative instruksjoner.
Klings budskap vektlegger tre praktiske arbeidsflyter: (1) tekst → videogenerering, (2) bilde/element → video (komposisjon og bytte av motiv/rekvisitt ved bruk av eksplisitte referanser), og (3) videoredigering/opptaksfortsettelse (restyling, legge til/fjerning av objekter, kontroll av startbilde/sluttbilde). Modellen støtter flerelementprompter (inkludert en "@"-syntaks for å målrette bestemte referansebilder) og har regissørlignende kontroller som forankring av start-/sluttbilde og videofortsettelse for å bygge fleropptakssekvenser.
5 viktige høydepunkter ved Kling O1
1) Ekte enhetlig multimodal input (MVL)
Kling O1s flaggskipfunksjon er å behandle tekst, stillbilder (flere referanser) og video som førsteklasses, samtidige inndata. Brukere kan legge inn flere referansebilder (eller et kort referanseklipp). og en instruksjon i naturlig språk; modellen vil analysere alle inndataene sammen for å produsere eller redigere en sammenhengende utdata. Dette reduserer friksjon mellom verktøykjeden og muliggjør arbeidsflyter som «bruk subjekt fra» @image1, plasser dem i miljøet fra @image2, match bevegelse til ref_video.mp4, og anvende filmatisk fargegrad X.» Denne «multimodale visuelle språket» (MVL)-innrammingen er kjernen i Klings pitch.
Hvorfor det betyr noe: Ekte kreative arbeidsflyter krever ofte kombinasjon av referanser: en karakter fra ett element, en kamerabevegelse fra et annet og en narrativ instruksjon i tekst. Å samle disse inndataene muliggjør generering i ett trinn og færre manuelle komposisjonstrinn.
2) Redigering + generering i én modell (multielementmodus)
De fleste tidligere systemer skilte generering (tekst→video) fra bildenøyaktig redigering. O1 kombinerer dem bevisst: den samme modellen som lager et klipp fra bunnen av kan også redigere eksisterende opptak – bytte objekter, gi klær nytt style, fjerne rekvisitter eller forlenge et opptak – alt via instruksjoner i naturlig språk. Denne konvergensen er en stor forenkling av arbeidsflyten for produksjonsteam.
O1-modellen oppnår dyp integrering av flere videooppgaver i kjernen:
- Tekst-til-video-generering
- Generering av bilde-/emnereferanse
- Videoredigering og maling
- Omstiling av video
- Neste/forrige bildegenerering
- Nøkkelbildebegrenset videogenerering
Den største betydningen av denne designen ligger i: Komplekse prosesser som tidligere krevde flere modeller eller uavhengige verktøy, kan nå fullføres i én enkelt motor. Dette reduserer ikke bare opprettelses- og beregningskostnadene betydelig, men legger også grunnlaget for utviklingen av en «enhetlig modell for videoforståelse og -generering».
3) Sammenhengen i videogenerering
Identitetskonsistens: O1-modellen forbedrer tverrmodale konsistensmodelleringsmuligheter, og opprettholder stabiliteten til referanseobjektets struktur, materiale, belysning og stil under genereringsprosessen:
- Den støtter referansebilder med flere visninger for motivmodellering;
- den støtter konsistens i motivene på tvers av ulike bilder (karakter-, objekt- og scenefunksjoner forblir kontinuerlige på tvers av ulike bilder);
- Den støtter hybride referanser for flere motiver, noe som muliggjør generering av gruppeportretter og interaktiv scenekonstruksjon.
Denne mekanismen forbedrer koherensen og «identitetskonsistensen» i videogenerering betydelig, noe som gjør den egnet for scenarier med ekstremt høye krav til konsistens, for eksempel reklame og generering av bilder på filmnivå.
Forbedret hukommelse: O1-modellen har også «minne», som forhindrer at utdatastilen blir ustabil på grunn av lange kontekster eller endring av instruksjoner. Den kan til og med:
- huske flere tegn samtidig;
- la forskjellige karakterer samhandle i videoen;
- opprettholde konsistens i stil, klær og holdning.
4) Presis komposisjon med «@»-syntaks og start-/sluttrammekontroll
Kling introduserte en komposisjonsforkortelse (rapportert som et «@»-omtalesystem) slik at du kan referere til bestemte bilder i ledeteksten (f.eks. @image1, @image2) for å tilordne roller til ressurser på en pålitelig måte. Kombinert med eksplisitt Start + End-rammespesifikasjon, muliggjør dette kontroll på regissørnivå over hvordan elementer overgår, beveger seg eller endrer form i det genererte klippet – et produksjonsfokusert funksjonssett som skiller O1 fra mange forbrukerorienterte generatorer.
5) Høy kvalitet, lengre utganger og stabling av flere oppgaver
Kling O1 skal etter sigende produsere kinoaktige 1080p-utganger (30 fps), og – med tidligere Kling-versjoner som setter scenen – skryter selskapet av generering av lengre klipp (rapportert opptil 2 minutter i nylige produktbeskrivelser). Den støtter også stabling av flere kreative oppgaver i én forespørsel (generering, legging av et motiv, endring av belysning og redigering av komposisjon). Disse egenskapene gjør den konkurransedyktig med tekst-→-videomotorer på høyere nivå.
Hvorfor det betyr noe: Lengre klipp med høy kvalitet og muligheten til å kombinere redigeringer reduserer behovet for å sette sammen mange korte klipp og forenkler produksjonen fra ende til ende.
Hvordan er Kling O1 oppbygd, og hva er de underliggende mekanismene?
O1 rundt en Multimodalt visuelt språk (MVL) kjerne: en modell som lærer felles innebygging for språk + bilder + bevegelsessignaler (videobilder og optiske flyt-lignende funksjoner), og deretter bruker diffusjons- eller transformatorbaserte dekodere for å syntetisere temporalt koherente bilder. Modellen beskrives som å utføre conditioning på flere referanser (tekst; én-til-mange-bilder; korte videoklipp) for å produsere en latent videorepresentasjon som deretter dekodes til bilder per bilde samtidig som tidsmessig konsistens bevares via oppmerksomhet på tvers av bildet eller spesialiserte tidsmoduler.
1. Multimodal transformator + lang kontekstarkitektur
O1-modellen benytter Kelings egenutviklede multimodale Transformer-arkitektur, som integrerer tekst-, bilde- og videosignaler, og støtter lang tidsmessig kontekstminne (Multimodal Long Context).
Dette gjør det mulig for modellen å forstå tidsmessig kontinuitet og romlig konsistens under videogenerering.
2. MVL: Multimodalt visuelt språk
MVL er kjerneinnovasjonen i denne arkitekturen.
Den justerer språklige og visuelle signaler i transformatoren gjennom et enhetlig semantisk mellomlag, og dermed:
- Tillate en enkelt inndataboks å blande multimodale instruksjoner;
- Forbedre modellens nøyaktige forståelse av beskrivelser i naturlig språk;
- Støtter svært fleksibel generering av interaktive videoer.
Innføringen av MVL markerer et skifte i videogenerering fra «tekstdrevet» til «semantisk-visuell samdrevet».
3. Tankekjede-inferensmekanisme
O1-modellen introduserer en «tankekjede»-inferenssti i videogenereringsfasen.
Denne mekanismen lar modellen utføre hendelseslogikk og tidsdeduksjon før generering, og dermed opprettholde en naturlig forbindelse mellom handlinger og hendelser i videoen.
Inferens- og redigeringsrørledninger
- Generasjon: feed: (tekst + valgfrie bildereferanser + valgfrie videoreferanser + genereringsinnstillinger) → modellen produserer latente videobilder → dekoder til bilder → valgfri farge-/temporal etterbehandling.
- Instruksjonsbasert redigering: feed: (original video + tekstinstruksjon + valgfrie bildereferanser) → modellen kartlegger internt den forespurte redigeringen til et sett med pikselromtransformasjoner og syntetiserer deretter redigerte bilder samtidig som uendret innhold bevares. Fordi alt er i én modell, brukes de samme kondisjonerings- og temporale modulene for både oppretting og redigering.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
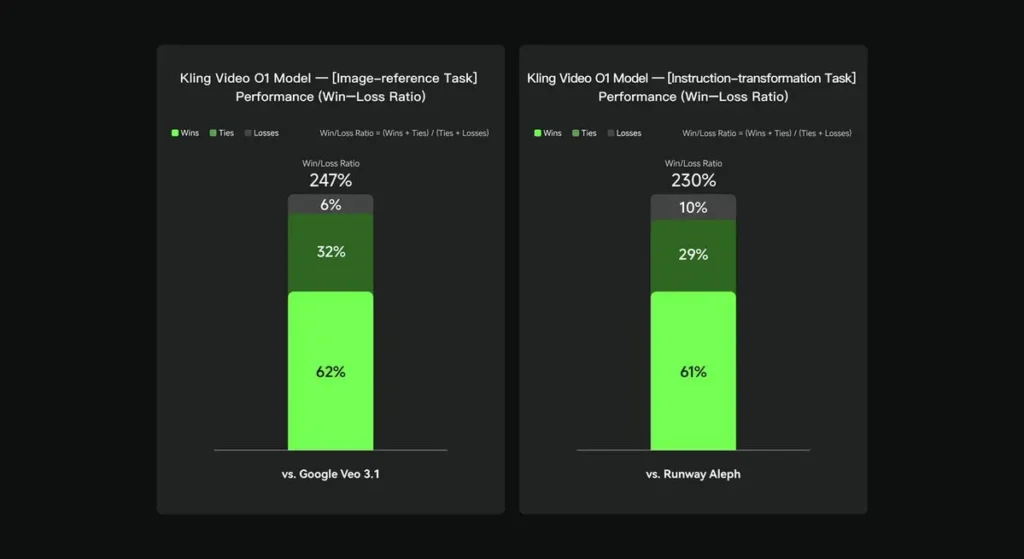
I interne evalueringer overgikk Keling Video O1 eksisterende internasjonale konkurrenter betydelig på flere viktige områder. Ytelsesresultater (basert på Keling AIs selvbygde evalueringssett):
- Oppgave «Bildereferanse»: O1 overgår Google Veo 3.1 totalt sett, med en seiersrate på 247 %;
- Oppgave «Instruksjonstransformasjon»: O1 utkonkurrerer Runway Aleph, med en seiersrate på 230 %.
Konkurrentbilde (sammenligning på funksjonsnivå)
| Evne / Modell | Kling O1 | Google Veo 3.1 | Rullebane (Aleph / Gen-4.5) |
|---|---|---|---|
| Enhetlig multimodal ledetekst (tekst + bilder + video) | **Ja (kjerne salgsargument)**multimodale flyter med én forespørsel. | Delvis — tekst→video + referanser finnes; mindre vekt på én samlet MVL. | Runway fokuserer på generering + redigering, men ofte som separate moduser; den nyeste Gen-4.5 reduserer gapet. |
| Konversasjons-/tekstbaserte pikselredigeringer | Ja — «rediger som en samtale» (ingen masker). | Delvis — redigering finnes, men maske-/nøkkelbilde-arbeidsflyter er fortsatt vanlige. | Runway har sterke redigeringsverktøy; Runway hevder sterke instruksjonstransformasjoner (varierer etter utgivelse). |
| Kontroll av start-/sluttbilde og kamerareferanse | Ja — eksplisitte start-/sluttbilde- og referansekamerabevegelser beskrevet. | Begrenset / i utvikling | Rullebane: forbedrede kontroller; ikke helt samme brukeropplevelse. |
| Langklippgenerering (høy kvalitet) | opptil ~2 minutter (1080p, 30fps) med produktmateriell og innlegg fra fellesskapet; | Veo 3.1: sterk koherens, men tidligere versjoner hadde kortere standardinnstillinger; varierer med modell/innstilling. | Runway Gen-4.5: sikter mot høy kvalitet; lengde/gjengivelse varierer. |
Konklusjon:
Kling O1s offentlige krav på berømmelse er arbeidsflytforening: gir én enkelt modell mandat til å forstå tekst, bilder og video, og til å utføre både generering og rik instruksjonsbasert redigering innenfor det samme semantiske systemet. For skapere og team som ofte beveger seg mellom trinnene «opprett», «rediger» og «utvid», kan denne konsolideringen dramatisk forenkle iterasjonshastighet og verktøykompleksitet. Forbedret tidsmessig konsistens, start-/sluttrammekontroll og pragmatiske plattformintegrasjoner som gjør den tilgjengelig for skapere.
Kling Video o1 API vil snart være tilgjengelig på CometAPI.
Utviklere har tilgang Kling 2.5 Turb og Veo 3.1 API gjennom CometAPI, de nyeste modellene som er oppført er per artikkelens publiseringsdato. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.
Klar til å dra? → Registrer deg for CometAPI i dag !
Hvis du vil vite flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!