

- juni ble Shanghai AI-enhjørningen MiniMax offisielt tilgjengelig for åpen kildekode MiniMax‑M1, verdens første åpne, storskala hybridoppmerksomhetsinferensmodell. Ved å kombinere en Mixture-of-Experts (MoE)-arkitektur med den nye Lightning Attention-mekanismen, leverer MiniMax-M1 store gevinster i inferenshastighet, håndtering av ultralang kontekst og ytelse for kompleks oppgave.
Bakgrunn og evolusjon
Bygger på grunnlaget for MiniMax-Tekst-01, som introduserte lynnedslag på et Mixture-of-Experts (MoE)-rammeverk for å oppnå 1 million token-kontekster under trening og opptil 4 millioner tokens ved inferens, representerer MiniMax-M1 neste generasjon av MiniMax-01-serien. Forgjengermodellen, MiniMax-Text-01, inneholdt 456 milliarder parametere totalt med 45.9 milliarder aktiverte per token, noe som demonstrerer ytelse på nivå med toppnivå LLM-er, samtidig som kontekstfunksjonene utvides betraktelig.
Viktige funksjoner i MiniMax-M1
- Hybrid MoE + Lightning-oppmerksomhetMiniMax-M1 kombinerer et sparsomt Mixture-of-Experts-design – 456 milliarder parametere totalt, men bare 45.9 milliarder aktivert per token – med Lightning Attention, en lineær kompleksitetsoppmerksomhet optimalisert for svært lange sekvenser.
- Ultralang kontekst: Støtter opptil 1 million input-tokens – omtrent åtte ganger grensen på 128 K for DeepSeek-R1 – som muliggjør dyp forståelse av massive dokumenter.
- Overlegen effektivitetNår 100 1 tokener genereres, krever MiniMax-M25s Lightning Attention bare ~30–1 % av beregningskapasiteten som brukes av DeepSeek-RXNUMX.
Modellvarianter
- MiniMax‑M1‑40K1 M tokenkontekst, 40 K tokeninferensbudsjett
- MiniMax‑M1‑80K1 M tokenkontekst, 80 K tokeninferensbudsjett
I bruksscenarier med TAU-benkverktøy overgikk 40K-varianten alle modeller med åpen vekt – inkludert Gemini 2.5 Pro – og demonstrerte dermed dens agentegenskaper.
Opplæringskostnader og oppsett
MiniMax-M1 ble trent ende-til-ende ved hjelp av storskala forsterkningslæring (RL) på tvers av et mangfoldig sett med oppgaver – fra avansert matematisk resonnement til sandkassebaserte programvareutviklingsmiljøer. En ny algoritme, CISPO (Clipped Importance Sampling for Policy Optimization) forbedrer opplæringseffektiviteten ytterligere ved å klippe ut viktighetssamplingvekter i stedet for oppdateringer på tokennivå. Denne tilnærmingen, kombinert med modellens lynraske oppmerksomhet, tillot full RL-opplæring på 512 H800 GPU-er å fullføres på bare tre uker til en total leiekostnad på 534,700 XNUMX dollar.
Tilgjengelighet og priser
MiniMax-M1 er utgitt under Apache 2.0 åpen kildekode-lisens og er umiddelbart tilgjengelig via:
- GitHub repository, inkludert modellvekter, treningsskript og evalueringsbenchmarks.
- SiliconCloud hosting, som tilbyr to varianter – 40 K-token («M1‑40K») og 80 K-token («M1‑80K») – med planer om å aktivere hele 1 M-token-trakten.
- Prisen er for øyeblikket satt til 4 yen per million tokens for input og 16 yen per million tokener for utdata, med volumrabatter tilgjengelig for bedriftskunder.
Utviklere og organisasjoner kan integrere MiniMax-M1 via standard API-er, finjustere domenespesifikke data eller distribuere lokale løsninger for sensitive arbeidsbelastninger.
Ytelse på oppgavenivå
| Oppgavekategori | Uthev | Relativ ytelse |
|---|---|---|
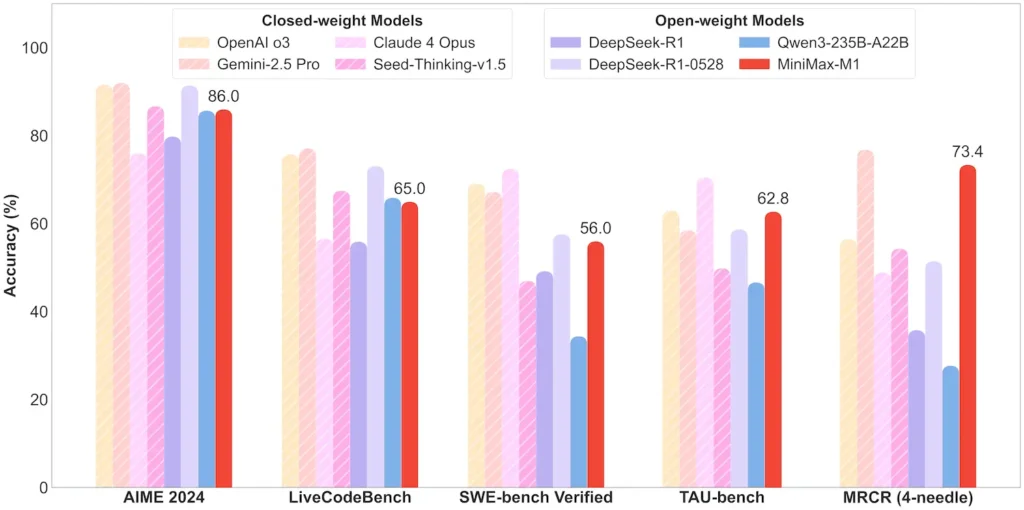
| Matematikk og logikk | AIME 2024: 86.0 % | > Qwen 3, DeepSeek-R1; nesten lukket kildekode |
| Lang kontekstforståelse | Linjal (4 K–1 M brikker): Stabil toppnivå | Overgår GPT-4 utover 128 K tokenlengde |
| Engineering programvare | SWE-bench (ekte GitHub-feil): 56 % | Best blant åpne modeller; nest ledende blant lukkede |
| Agent- og verktøybruk | TAU-bench (API-simulering) | 62–63.5 % vs. Gemini 2.5, Claude 4 |
| Dialog og assistent | Multiutfordring: 44.7 % | Matcher Claude 4, DeepSeek-R1 |
| Faktaspørsmål og spørsmål | Enkel QA: 18.5 % | Område for fremtidig forbedring |
Merk: prosenter og referansetall fra offisiell MiniMax-avsløring og uavhengige nyhetsrapporter
Tekniske innovasjoner
- Hybrid oppmerksomhetsstabel: Lyn oppmerksomhet lag (lineær kostnad) flettet sammen med periodisk Softmax Attention (kvadratisk, men mer uttrykksfull) for å balansere effektivitet og modelleringskraft.
- Sparsom MoE-ruting32 ekspertmoduler; hver token aktiverer bare ~10 % av de totale parameterne, noe som reduserer inferenskostnadene samtidig som kapasiteten bevares.
- CISPO forsterkningslæringEn ny «Clipped IS-weight Policy Optimization»-algoritme som beholder sjeldne, men viktige tokens i læringssignalet, og akselererer RL-stabilitet og -hastighet.
MiniMax-M1s åpne vektutgivelse låser opp ultralang kontekst, høyeffektiv inferens for alle – og bygger bro mellom forskning og distribuerbar storskala AI.
Komme i gang
CometAPI tilbyr et enhetlig REST-grensesnitt som samler hundrevis av AI-modeller – inkludert ChatGPT-familien – under et konsistent endepunkt, med innebygd API-nøkkeladministrasjon, brukskvoter og faktureringsdashboards. I stedet for å sjonglere flere leverandør-URL-er og legitimasjonsinformasjon.
For å begynne, utforsk modellenes muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.
Den nyeste integrasjonen av MiniMax-M1 API vil snart dukke opp på CometAPI, så følg med! Mens vi ferdigstiller opplastingen av MiniMax-M1-modellen, kan du utforske de andre modellene våre på Modeller-siden eller prøv dem i AI lekeplassMiniMaxs nyeste modell i CometAPI er Minimax ABAB7-Preview API og MiniMax Video-01 API ,se til:
