GLM-4.6 er den siste større utgivelsen i Z.ai’s (tidligere Zhipu AI) GLM-familie: en fjerdegenerasjons, storspråkmodell MoE (Mixture-of-Experts) tunet for agentbaserte arbeidsflyter, langkontekst-resonnering og koding i virkeligheten. Utgivelsen vektlegger praktisk agent-/verktøyintegrasjon, et svært stort kontekstvindu, og åpenvekt-tilgjengelighet for lokal utrulling.
Nøkkelfunksjoner
- Lang kontekst — innebygd 200K tokens kontekstvindu (utvidet fra 128K). (docs.z.ai)
- Koding og agentkapabilitet — markedsførte forbedringer på oppgaver for koding i virkeligheten og bedre verktøykalling for agenter.
- Effektivitet — rapportert ~30% lavere tokenforbruk vs GLM-4.5 på Z.ai’s tester.
- Utrulling og kvantisering — først annonsert FP8- og Int4-integrasjon for Cambricon-brikker; native FP8-støtte på Moore Threads via vLLM.
- Modellstørrelse og tensortype — publiserte artefakter indikerer en ~357B-parametermodell (BF16 / F32-tensorer) på Hugging Face.
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en ren tekst LLM (input- og outputmodaliteter: tekst). Kontekstlengde = 200K tokens; maks utdata = 128K tokens.
Kvantisering og maskinvarestøtte. Teamet rapporterer FP8/Int4-kvantisering på Cambricon-brikker og native FP8-kjøring på Moore Threads GPU-er ved bruk av vLLM for inferens — viktig for å redusere inferenskostnad og muliggjøre on-prem og nasjonale skydistribusjoner.
Verktøy og integrasjoner. GLM-4.6 distribueres gjennom Z.ai’s API, tredjeparts leverandørnettverk (f.eks., CometAPI), og integreres i kodeagenter (Claude Code, Cline, Roo Code, Kilo Code).
Tekniske detaljer
Modaliteter og formater. GLM-4.6 er en ren tekst LLM (input- og outputmodaliteter: tekst). Kontekstlengde = 200K tokens; maks utdata = 128K tokens.
Kvantisering og maskinvarestøtte. Teamet rapporterer FP8/Int4-kvantisering på Cambricon-brikker og native FP8-kjøring på Moore Threads GPU-er ved bruk av vLLM for inferens — viktig for å redusere inferenskostnad og muliggjøre on-prem og nasjonale skydistribusjoner.
Verktøy og integrasjoner. GLM-4.6 distribueres gjennom Z.ai’s API, tredjeparts leverandørnettverk (f.eks., CometAPI), og integreres i kodeagenter (Claude Code, Cline, Roo Code, Kilo Code).
Benchmark-ytelse
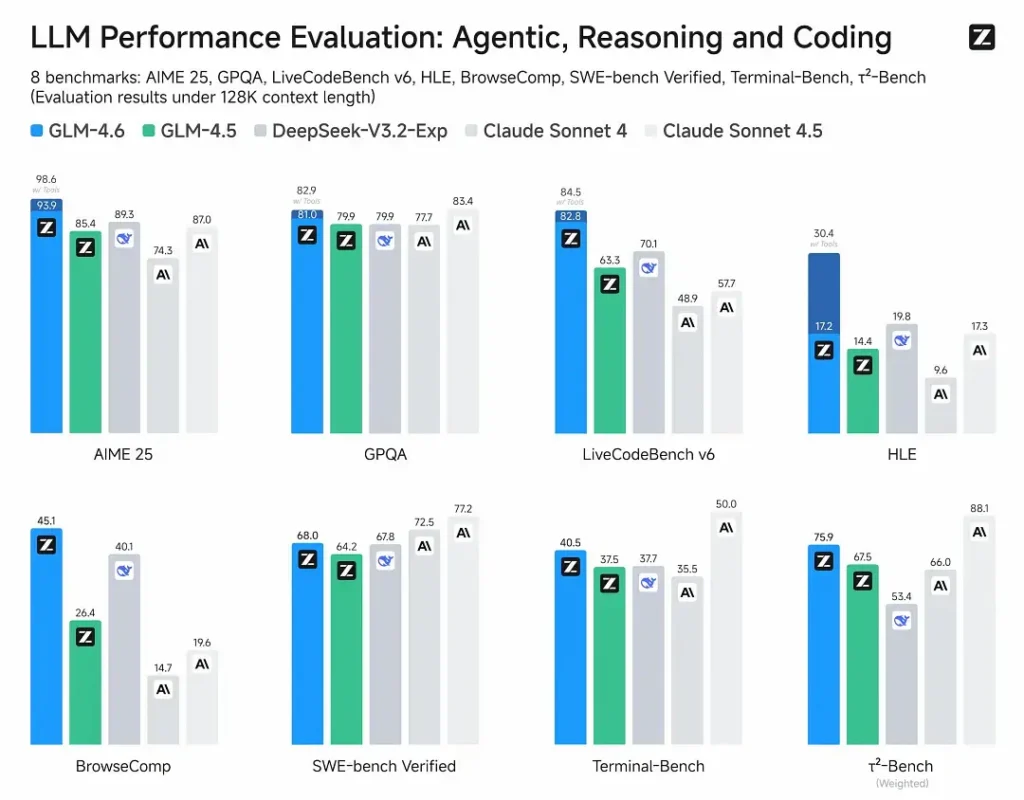
- Publiserte evalueringer: GLM-4.6 ble testet på åtte offentlige benchmarks som dekker agenter, resonnering og koding og viser klare gevinster over GLM-4.5. På menneskeevaluerte, virkelige kodingstester (utvidet CC-Bench) bruker GLM-4.6 ~15% færre tokens vs GLM-4.5 og oppnår en ~48.6% seiersrate vs Anthropic’s Claude Sonnet 4 (nær paritet på mange topplister).
- Posisjonering: resultater hevder at GLM-4.6 er konkurransedyktig med ledende innenlandske og internasjonale modeller (eksempler som nevnes inkluderer DeepSeek-V3.1 og Claude Sonnet 4).
Begrensninger og risiko
- Hallusinasjoner og feil: som alle nåværende LLM-er kan og vil GLM-4.6 gjøre faktiske feil — Z.ai’s dokumentasjon advarer eksplisitt om at utdata kan inneholde feil. Brukere bør anvende verifisering og retrieval/RAG for kritisk innhold.
- Modellkompleksitet og driftskostnad: 200K kontekst og svært store utdata øker minne- og latenserkrav betraktelig og kan heve inferenskostnader; kvantisering/inferens-ingeniørarbeid kreves for drift i skala.
- Domenegap: selv om GLM-4.6 rapporterer sterk agent-/kodeytelse, påpeker noen offentlige rapporter at den fortsatt ligger etter visse versjoner av konkurrerende modeller i spesifikke mikrobenchmarks (f.eks., noen kodingmetrikker vs Sonnet 4.5). Vurder per oppgave før du erstatter produksjonsmodeller.
- Sikkerhet og policy: åpne vekter øker tilgjengeligheten men reiser også spørsmål om forvaltning (mitigations, guardrails og red-teaming er fortsatt brukerens ansvar).
Bruksområder
- Agentbaserte systemer og verktøyorkestrering: lange agent-traces, planlegging med flere verktøy, dynamisk verktøykalling; modellens agentiske tuning er et sentralt salgsargument.
- Kodeassistenter for virkelige scenarier: flerskritt kodegenerering, kodereview og interaktive IDE-assistenter (integrert i Claude Code, Cline, Roo Code—per Z.ai). Forbedringer i token-effektivitet gjør den attraktiv for utviklerplaner med høy bruk.
- Langdokument-arbeidsflyter: oppsummering, syntese av flere dokumenter, lange juridiske/tekniske gjennomganger på grunn av 200K-vinduet.
- Innholdsskaping og virtuelle karakterer: utvidede dialoger, konsistent persona-vedlikehold i scenarier med mange omganger.
Hvordan GLM-4.6 sammenlignes med andre modeller
- GLM-4.5 → GLM-4.6: trinnvis endring i kontekststørrelse (128K → 200K) og token-effektivitet (~15% færre tokens på CC-Bench); forbedret agent-/verktøybruk.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai rapporterer nær paritet på flere topplister og en ~48.6% seiersrate på CC-Benchs oppgaver for koding i virkeligheten (dvs. tett konkurranse, med noen mikrobenchmarks der Sonnet fortsatt leder). For mange ingeniørteam posisjoneres GLM-4.6 som et kostnadseffektivt alternativ.
- GLM-4.6 vs andre langkontekstmodeller (DeepSeek, Gemini-varianter, GPT-4-familien): GLM-4.6 vektlegger stort kontekst og agentiske koding-arbeidsflyter; relative styrker avhenger av metrikk (token-effektivitet/agent-integrasjon vs rå nøyaktighet i kodingsyntese eller sikkerhetspipelines). Empirisk utvalg bør være oppgavedrevet.
Zhipu AI’s nyeste flaggskipsmodell GLM-4.6 lansert: 355B totale params, 32B aktive. Overgår GLM-4.5 i alle kjernekapabiliteter.
- Koding: På linje med Claude Sonnet 4, best i Kina.
- Kontekst: Utvidet til 200K (fra 128K).
- Resonnering: Forbedret, støtter verktøykalling under inferens.
- Søk: Forbedret verktøykalling og agentytelse.
- Skriving: Bedre samsvar med menneskelige preferanser i stil, lesbarhet og rollespill.
- Flerspråklig: Forbedret oversettelse på tvers av språk.