

I det raskt utviklende landskapet innen kunstig intelligens har 2025 vært vitne til betydelige fremskritt innen store språkmodeller (LLM-er). Blant de fremste er Alibabas Qwen2.5, DeepSeeks V3- og R1-modeller, og OpenAIs ChatGPT. Hver av disse modellene bringer unike funksjoner og innovasjoner til bordet. Denne artikkelen fordyper seg i den siste utviklingen rundt Qwen2.5, og sammenligner funksjonene og ytelsen med DeepSeek og ChatGPT for å avgjøre hvilken modell som for tiden leder AI-kappløpet.
Hva er Qwen2.5?
Oversikt
Qwen 2.5 er Alibaba Clouds nyeste tette, dekoderbaserte store språkmodell, tilgjengelig i flere størrelser fra 0.5 til 72 milliarder parametere. Den er optimalisert for instruksjonsoppfølging, strukturerte utdata (f.eks. JSON, tabeller), koding og matematisk problemløsning. Med støtte for over 29 språk og en kontekstlengde på opptil 128 2.5 tokens, er QwenXNUMX designet for flerspråklige og domenespesifikke applikasjoner.
Viktige funksjoner
- flerspråklig StøtteStøtter over 29 språk, og henvender seg til en global brukerbase.
- Utvidet kontekstlengdeHåndterer opptil 128 XNUMX tokener, noe som muliggjør behandling av lange dokumenter og samtaler.
- Spesialiserte varianterInkluderer modeller som Qwen2.5-Coder for programmeringsoppgaver og Qwen2.5-Math for matematisk problemløsning.
- tilgjengelighetTilgjengelig via plattformer som Hugging Face, GitHub og et nylig lansert webgrensesnitt på chat.qwenlm.ai.
Hvordan bruke Qwen 2.5 lokalt?
Nedenfor finner du en trinnvis veiledning for 7 B Chat kontrollpunkt; større størrelser varierer bare i GPU-krav.
1. Maskinvarekrav
| Modell | vRAM for 8-bit | vRAM for 4-bit (QLoRA) | Diskstørrelse |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Én RTX 4090 (24 GB) er tilstrekkelig for 7 B-inferens med full 16-bits presisjon; to slike kort eller CPU-avlastning pluss kvantisering kan håndtere 14 B.
2. Installasjon
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Hurtig inferensskript
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
Ocuco trust_remote_code=True flagg er påkrevd fordi Qwen sender en spesialtilpasset Roterende posisjonsinnstøping innpakning.
4. Finjustering med LoRA
Takket være parametereffektive LoRA-adaptere kan du spesialtrene Qwen på ~50 K domenepar (f.eks. medisinsk) på under fire timer med et enkelt 24 GB GPU:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Den resulterende adapterfilen (~120 MB) kan slås sammen igjen eller lastes inn etter behov.
Valgfritt: Kjør Qwen 2.5 som et API
CometAPI fungerer som et sentralisert knutepunkt for APIer av flere ledende AI-modeller, og eliminerer behovet for å engasjere seg med flere API-leverandører separat. CometAPI tilbyr en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere Qwen API, og du får $1 på kontoen din etter registrering og innlogging! Velkommen til å registrere deg og oppleve CometAPI. For utviklere som ønsker å integrere Qwen 2.5 i applikasjoner:
Trinn 1: Installer nødvendige biblioteker:
bash
pip install requests
Trinn 2: Skaff deg API-nøkkel
- naviger til CometAPI.
- Logg på med din CometAPI-konto.
- Velg Dashbord.
- Klikk på "Get API Key" og følg instruksjonene for å generere nøkkelen din.
Trinn 3: Implementer API-kall
Bruk API-legitimasjonen til å sende forespørsler til Qwen 2.5. Erstatt med din faktiske CometAPI-nøkkel fra kontoen din.
For eksempel, i Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Denne integrasjonen muliggjør sømløs integrering av Qwen 2.5s funksjoner i ulike applikasjoner, noe som forbedrer funksjonaliteten og brukeropplevelsen. Velg “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” endepunkt for å sende API-forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsteksten er hentet fra nettstedets API-dokumentasjon. Nettstedet vårt tilbyr også en Apifox-test for enkelhets skyld.
Vennligst se Qwen 2.5 Max API for integreringsdetaljer. CometAPI har oppdatert det siste QwQ-32B API.For mer modellinformasjon i Comet API, se API-dok.
Beste praksis og tips
| Scenario | Anbefaling |
|---|---|
| Spørsmål og svar på lange dokumenter | Del opp passasjer i ≤16 100 tokener og bruk henteforsterkede ledetekster i stedet for naive XNUMX XNUMX kontekster for å redusere latens. |
| Strukturerte utganger | Sett prefikset for systemmeldingen med: You are an AI that strictly outputs JSON. Qwen 2.5s justeringstrening utmerker seg ved begrenset generering. |
| Kodeavslutning | Sett temperature=0.0 og top_p=1.0 for å maksimere determinismen, så sampl flere stråler (num_return_sequences=4) for rangering. |
| Sikkerhetsfiltrering | Bruk Alibabas åpen kildekode «Qwen‑Guardrails» regex-pakke eller OpenAIs tekstmoderering‑004 som et første steg. |
Kjente begrensninger for Qwen 2.5
- Rask injeksjonsfølsomhet. Eksterne revisjoner viser jailbreak-suksessrater på 18 % på Qwen 2.5‑VL – en påminnelse om at ren modellstørrelse ikke immuniserer mot fiendtlige instruksjoner.
- Ikke-latinsk OCR-støy. Når modellens ende-til-ende-pipeline er finjustert for visjonsspråklige oppgaver, forveksler den noen ganger tradisjonelle og forenklede kinesiske glyfer, noe som krever domenespesifikke korreksjonslag.
- GPU-minneklippe ved 128 K. FlashAttention-2 forskyver RAM, men en tett foroverpassering på 72 B over 128 K tokens krever fortsatt >120 GB vRAM; utøvere bør bruke WindowAttend eller KV-cache.
Veikart og samfunnsøkosystem
Qwen-teamet har hintet til Qwen 3.0, rettet mot en hybrid rutingsryggrad (Dense + MoE) og enhetlig forhåndstrening av tale, syn og tekst. I mellomtiden er økosystemet allerede vert for:
- Q-Agent – en ReAct-lignende tankekjede-agent som bruker Qwen 2.5‑14B som policy.
- Kinesisk finansiell alpakka – en LoRA på Qwen2.5‑7B trent med 1 million regulatoriske innleveringer.
- Åpne tolk-pluginen – bytter GPT-4 mot et lokalt Qwen-sjekkpunkt i VS-koden.
Sjekk Hugging Face-siden «Qwen2.5-kolleksjonen» for en kontinuerlig oppdatert liste over kontrollpunkter, adaptere og evalueringsseler.
Sammenlignende analyse: Qwen2.5 vs. DeepSeek og ChatGPT
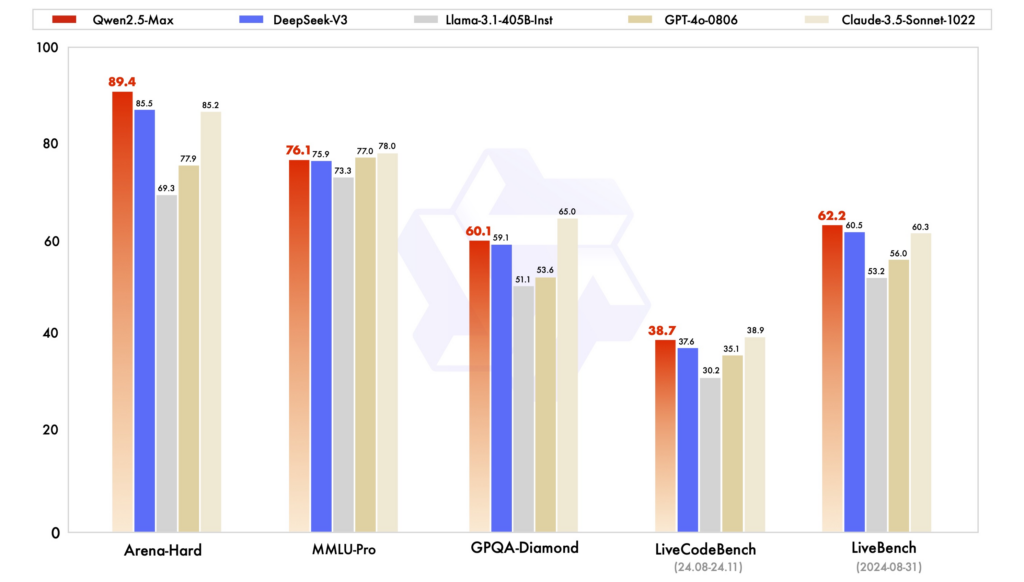
Ytelsesreferanser: I diverse evalueringer har Qwen2.5 vist sterk ytelse i oppgaver som krever resonnering, koding og flerspråklig forståelse. DeepSeek-V3, med sin MoE-arkitektur, utmerker seg i effektivitet og skalerbarhet, og leverer høy ytelse med reduserte beregningsressurser. ChatGPT er fortsatt en robust modell, spesielt i generelle språkoppgaver.
Effektivitet og kostnad: DeepSeeks modeller er kjent for sin kostnadseffektive trening og inferens, og utnytter MoE-arkitekturer for å kun aktivere nødvendige parametere per token. Qwen2.5, selv om den er kompakt, tilbyr spesialiserte varianter for å optimalisere ytelsen for spesifikke oppgaver. ChatGPTs trening involverte betydelige beregningsressurser, noe som gjenspeiles i driftskostnadene.
Tilgjengelighet og tilgjengelighet med åpen kildekode: Qwen2.5 og DeepSeek har tatt i bruk prinsipper for åpen kildekode i varierende grad, med modeller tilgjengelig på plattformer som GitHub og Hugging Face. Qwen2.5s nylige lansering av et webgrensesnitt forbedrer tilgjengeligheten. ChatGPT, selv om det ikke er åpen kildekode, er bredt tilgjengelig gjennom OpenAIs plattform og integrasjoner.
Konklusjon
Qwen 2.5 ligger på et sweet spot mellom Premium-tjenester med lukket vekt og helt åpne hobbymodellerDens blanding av permissiv lisensiering, flerspråklig styrke, langkontekstkompetanse og et bredt spekter av parameterskalaer gjør den til et overbevisende grunnlag for både forskning og produksjon.
Etter hvert som LLM-landskapet med åpen kildekode raser fremover, demonstrerer Qwen-prosjektet det åpenhet og ytelse kan sameksistereFor både utviklere, dataforskere og beslutningstakere er det å mestre Qwen 2.5 i dag en investering i en mer pluralistisk og innovasjonsvennlig fremtid med kunstig intelligens.