

Qwen2.5-VL-32B API har fått oppmerksomhet for sitt fremragende prestasjon i ulike komplekse oppgaver, og kombinerer begge bilde- og tekstdata for en beriket forståelse av verden. Utviklet av Alibaba, denne 32 milliarder parametermodellen er en oppgradering av den tidligere Qwen2.5-VL serie, flytter grensene for AI-drevet resonnement og visuell forståelse.

Oversikt over Qwen2.5-VL-32B
Qwen2.5-VL-32B er en banebrytende, åpen kildekode multimodal modell designet for å håndtere en rekke oppgaver som involverer både tekst og bilder. Med sin 32 milliarder parametere, tilbyr den en kraftig arkitektur forum bildegjenkjenning, matematisk resonnement, generering av dialog, og mye mer. Den er forbedret læringsevner, basert på forsterkende læring, lar den generere svar som passer bedre med menneskelige preferanser.
Viktige funksjoner og funksjoner
Qwen2.5-VL-32B demonstrerer bemerkelsesverdige evner på tvers av flere domener:
Bildeforståelse og beskrivelse: Denne modellen utmerker seg bildeanalyse, nøyaktig identifisere objekter og scener. Det kan generere detaljerte, naturlige språkbeskrivelser og til og med gi finkornet innsikt inn i objektattributter og deres relasjoner.
Matematisk resonnement og logikk: Modellen er utstyrt for å løse komplekse matematiske problemer—alt fra geometri til algebra– ved å ansette flertrinns resonnement med klar logikk og strukturerte utganger.
Tekstgenerering og dialog: Med sin avanserte språkmodell genererer Qwen2.5-VL-32B sammenhengende og kontekstuelt relevante svar basert på inndatatekst eller bilder. Den støtter også dialog med flere svinger, noe som åpner for mer naturlige og kontinuerlige interaksjoner.
Visuelle spørsmålssvar: Modellen kan svare på spørsmål knyttet til bildeinnhold, som f.eks objektgjenkjenning og scenebeskrivelse, som gir sofistikert visuell logikk og slutningsevner.
Teknisk grunnlag for Qwen2.5-VL-32B
For å forstå kraften bak Qwen2.5-VL-32B, er det avgjørende å utforske de tekniske prinsippene. Nedenfor er de viktigste aspektene som bidrar til ytelsen:
- Multimodal foropplæring: Modellen er forhåndsopplært med store datasett bestående av begge tekst- og bildedata. Dette gjør det mulig å lære ulike visuelle og språklige funksjoner, noe som letter sømløs tverrmodal forståelse.
- Transformatorarkitektur: Bygget på den robuste Transformatorarkitektur, utnytter modellen både encoder og dekoder strukturer for å behandle bilde- og tekstinndata, og genererer svært nøyaktige utdata. Dens selvoppmerksomhet mekanisme gjør det mulig å fokusere på kritiske komponenter i inngangsdataene, noe som øker presisjonen.
- Optimalisering av forsterkende læring: Qwen2.5-VL-32B drar nytte av forsterkende læring, der den finjusteres basert på tilbakemeldinger fra mennesker. Denne prosessen sikrer at modellens svar er flere i tråd med menneskelige preferanser mens du optimerer flere mål som f.eks nøyaktighet, logikkog flyt.
- Visuell språkjustering: Gjennom kontrastiv læring og tilpasningsstrategier, sikrer modellen at begge deler visuelle funksjoner og tekstlig informasjon er riktig integrert i språkrom, noe som gjør den svært effektiv for multimodale oppgaver.
Prestasjonshøydepunkter
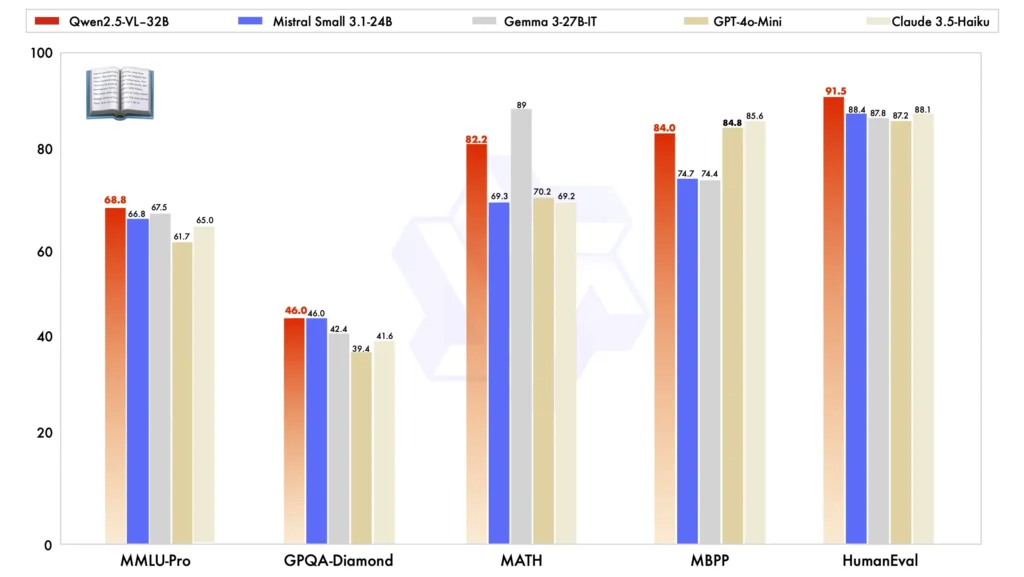
Sammenlignet med andre modeller i stor skala, skiller Qwen2.5-VL-32B seg ut i flere viktige referanser, og viser frem sin overlegen ytelse i begge multimodal og ren tekstoppgaver:
Modellsammenligning: Mot andre modeller som Mistral-Small-3.1-24B og Gemma-3-27B-IT, Qwen2.5-VL-32B demonstrerer betydelig forbedrede egenskaper. Spesielt det til og med utkonkurrerer den større Qwen2-VL-72B i ulike oppgaver.
Multimodal oppgaveytelse: I kompleks multimodale oppgaver slik som MMMU, MMMU-Proog MathVista, Qwen2.5-VL-32B utmerker seg, og leverer presise resultater som skiller den fra andre modeller av lignende størrelse.
MM-MT-benk benchmark: Sammenlignet med forgjengeren, Qwen2-VL-72B-Instruct, viser den nye versjonen betydelig forbedring, spesielt i sin logisk resonnement og multimodalt resonnement evner.
Ren tekstytelse: I ren tekstbaserte oppgaver har Qwen2.5-VL-32B dukket opp som topp utøver i sin klasse, tilbyr forbedret tekstgenerering, resonnement, og generell nøyaktighet.
Prosjektressurser
For utviklere og AI-entusiaster som ønsker å utforske Qwen2.5-VL-32B videre, er flere nøkkelressurser tilgjengelige:
- Offesiell nettside: Qwen2.5-VL-32B-prosjekt
- HuggingFace Model: HuggingFace Qwen2.5-VL-32B-Instruct
Virkelige applikasjoner
Qwen2.5-VL-32Bs allsidighet gjør den egnet for et bredt spekter av praktiske applikasjoner på tvers av ulike bransjer:
Intelligent kundeservice: Modellen kan brukes til automatisk å håndtere kundehenvendelser, og utnytte dens evne til å forstå og generere tekstbaserte og bildebaserte svar.
Opplæringshjelp: Ved å løse matematiske problemer, tolking bildeinnhold, og forklarer konsepter, kan det forbedre læringsprosessen for elevene betydelig.
Bildekommentar: I innholdsstyringssystemer kan Qwen2.5-VL-32B automatisere genereringen av bildetekster og beskrivelser, noe som gjør det til et uvurderlig verktøy for media og kreative næringer.
Autonom kjøring: Ved å analysere veiskilt og trafikkforhold gjennom sine visuelle prosesseringsevner, kan modellen gi sanntidsinnsikt for å forbedre kjøresikkerhet.
Content Creation: I media og reklame kan modellen generere tekst basert på visuelle stimuli, og hjelper innholdsskapere med å produsere overbevisende fortellinger for videoer og annonser.
Fremtidsutsikter og utfordringer
Mens Qwen2.5-VL-32B representerer et sprang fremover innen multimodal AI, er det fortsatt utfordringer og muligheter foran seg. Finjustering modellen for mer spesifikke oppgaver, integrere den med sanntidsapplikasjoner og forbedre den skalerbarhet å håndtere mer komplekse multimodale datasett er områder som krever pågående forskning og utvikling.
Etter hvert som flere AI-modeller blir utgitt med lignende funksjoner, etiske hensyn rundt AI-generert innhold, Biasog personvern fortsette å få oppmerksomhet. Å sikre at Qwen2.5-VL-32B og lignende modeller er opplært og brukt på en ansvarlig måte, vil være avgjørende for deres langsiktige suksess.
Beslektede emner:Den beste 8 mest populære AI-modellsammenlikningen fra 2025
Konklusjon
Qwen2.5-VL-32B er et kraftig verktøy i arsenalet av AI-modeller designet for å takle multimodale oppgaver med imponerende nøyaktighet og raffinement. Ved å integrere avansert forsterkning læring, transformatorarkitekturog visuelt-språklig justering, det ikke bare overgår tidligere modeller men åpner også for spennende muligheter for bransjer som spenner fra utdanning til autonom kjøring. Som åpen kildekode-teknologi tilbyr den et enormt potensial for utviklere og AI-brukere til å eksperimentere, optimalisere og implementere i virkelige applikasjoner.
Hvordan ringe Qwen2.5-VL-32B API fra CometAPI
1.Logg inn til cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
2.Få tilgangslegitimasjons-API-nøkkelen av grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
-
Få nettadressen til dette nettstedet: https://api.cometapi.com/
-
Velg Qwen2.5-VL-32B-endepunktet for å sende API-forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsinstansen hentes fra vår nettside API-dok. Vår nettside tilbyr også Apifox-test for enkelhets skyld.
-
Behandle API-svaret for å få det genererte svaret. Etter å ha sendt API-forespørselen, vil du motta et JSON-objekt som inneholder den genererte fullføringen.