

Alibabas siste fremskritt innen kunstig intelligens, Qwen3-koder, markerer en betydelig milepæl i det raskt utviklende landskapet innen AI-drevet programvareutvikling. Qwen23-Coder ble avduket 2025. juli 3 og er en åpen kildekode, agentisk kodemodell designet for å autonomt håndtere komplekse programmeringsoppgaver, fra å generere standardkode til feilsøking på tvers av hele kodebaser. Modellen er bygget på banebrytende ekspertarkitektur (MoE) og kan skryte av 480 milliarder parametere med 35 milliarder aktivert per token, og oppnår en optimal balanse mellom ytelse og beregningseffektivitet. I denne artikkelen utforsker vi hva som skiller Qwen3-Coder fra andre, undersøker dens referanseytelse, pakker ut de tekniske innovasjonene, veileder utviklere gjennom optimal bruk og vurderer modellens mottakelse og fremtidsutsikter.
Hva er Qwen3‑Coder?
Qwen3‑Coder er den nyeste agentiske kodemodellen fra Qwen-familien, offisielt annonsert 22. juli 2025. Flaggskipvarianten Qwen3‑Coder‑480B‑A35B‑Instruct er designet som en «mest agentisk kodemodell hittil», og har 480 milliarder parametere totalt med en Mixture‑of‑Experts (MoE)-design som aktiverer 35 milliarder parametere per token. Den støtter kontekstvinduer på opptil 256 XNUMX tokener og skalerer til én million tokener gjennom ekstrapoleringsteknikker, noe som imøtekommer behovet for kodeforståelse og -generering på reposkala.
Åpen kildekode under Apache 2.0
I tråd med Alibabas forpliktelse til fellesskapsdrevet utvikling er Qwen3-Coder utgitt under Apache 2.0-lisensen. Denne tilgjengeligheten med åpen kildekode sikrer åpenhet, fremmer tredjepartsbidrag og akselererer adopsjon i både akademia og industri. Forskere og ingeniører kan få tilgang til forhåndstrente vekter og finjustere modellen for spesialiserte domener, fra fintech til vitenskapelig databehandling.
Evolusjon fra Qwen2.5
Qwen2.5-Coder bygger videre på suksessen til Qwen0.5-Coder, som tilbød modeller fra 32 milliarder til 3 milliarder parametere og oppnådde SOTA-resultater på tvers av kodegenereringsbenchmarks, og utvider forgjengerens muligheter gjennom større, forbedrede datapipelines og nye treningsregimer. Qwen2.5-Coder ble trent på over 5.5 billioner tokener med grundig datarensing og syntetisk datagenerering. Qwen3-Coder videreutvikler dette ved å innta 7.5 billioner tokener med et kodeforhold på 70 %, og utnytter tidligere modeller for å filtrere og omskrive støyende input for overlegen datakvalitet.
Hva er de viktigste innovasjonene som skiller Qwen3-Coder fra hverandre?
Flere viktige innovasjoner skiller Qwen3-Coder fra andre:
- AgentoppgaveorkestreringI stedet for bare å generere kodesnutter, kan Qwen3-Coder autonomt kjede sammen flere operasjoner – lese dokumentasjon, aktivere verktøy og validere utdata – uten menneskelig inngripen.
- Forbedret tenkningsbudsjettUtviklere kan konfigurere hvor mye databehandling som skal brukes til hvert trinn i resonnementet, noe som gir mulighet for en tilpassbar avveining mellom hastighet og grundighet, noe som er avgjørende for storskala kodesyntese.
- Sømløs verktøyintegrasjonQwen3-Coders kommandolinjegrensesnitt, «Qwen Code», tilpasser funksjonskallprotokoller og tilpassede ledetekster for å integreres med populære utviklerverktøy, noe som gjør det enkelt å bygge det inn i eksisterende CI/CD-pipelines og IDE-er.
Hvordan presterer Qwen3‑Coder sammenlignet med konkurrentene?
Referanseoppgjør
I følge Alibabas publiserte ytelsesmålinger overgår Qwen3-Coder ledende innenlandske alternativer – som DeepSeeks codex-stilmodeller og Moonshot AIs K2 – og matcher eller overgår kodingsmulighetene til de beste amerikanske tilbudene på tvers av flere referansepunkter. I tredjepartsevalueringer:
- Aider PolyglotQwen3-Coder-480B oppnådde en poengsum på 61.8%, som illustrerer sterk flerspråklig kodegenerering og resonnement.
- MBPP og HumanEvalUavhengige tester rapporterer at Qwen3-Coder-480B-A35B yter bedre enn GPT-4.1 både når det gjelder funksjonell korrekthet og kompleks håndtering av prompter, spesielt i flertrinns kodeutfordringer.
- 480B-parametervarianten oppnådde over 85 % utførelsessuksess på SWE-Benk Verifisert pakke – overgår både DeepSeeks toppmodell (78 %) og Moonshots K2 (82 %), og matcher Claude Sonnet 4 med 86 %.
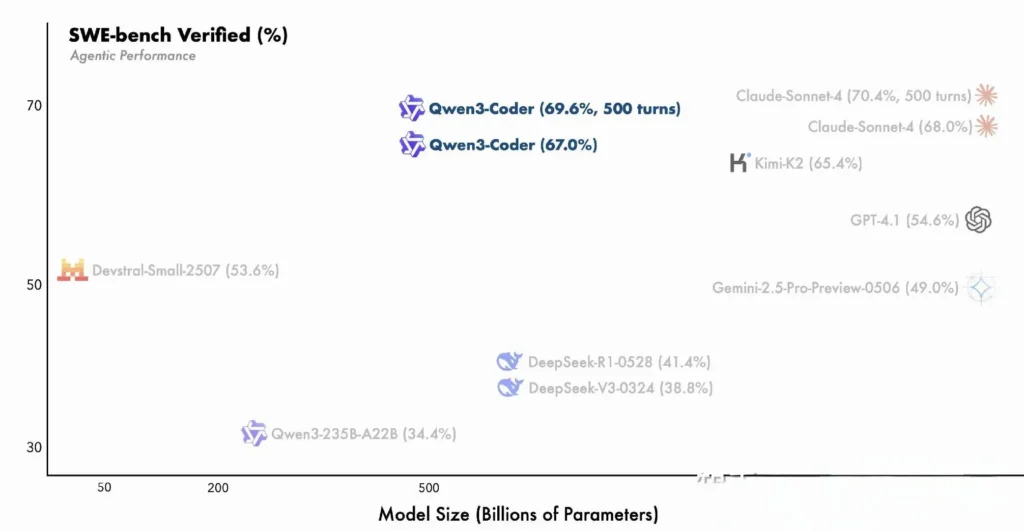
Sammenligning med proprietære modeller
Alibaba hevder at Qwen3-Coders agentfunksjoner samsvarer med Anthropics Claude og OpenAIs GPT-4 i ende-til-ende-kodingsarbeidsflyter, en bemerkelsesverdig bragd for en åpen kildekode-modell. Tidlige testere rapporterer at flertrinnsplanleggingen, dynamiske verktøyanrop og automatiserte feilretting kan håndtere komplekse oppgaver – som å bygge fullstack-webapplikasjoner eller integrere CI/CD-pipelines – med minimale menneskelige spørsmål. Disse funksjonene styrkes av modellens evne til å selvvalidere gjennom kodekjøring, en funksjon som er mindre uttalt i rent generative LLM-er.
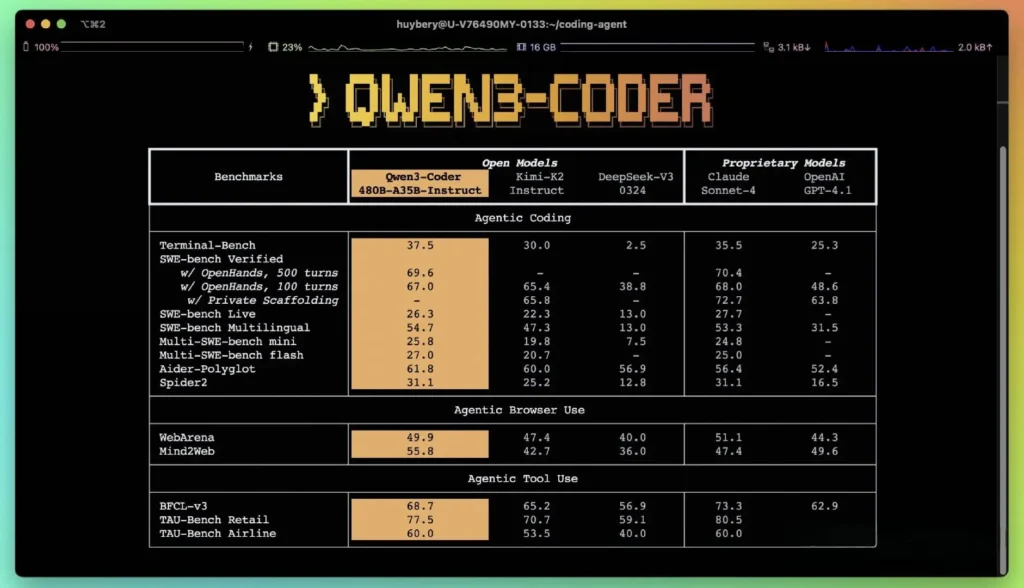
Hva er de tekniske nyvinningene bak Qwen3‑Coder?
Arkitektur for blanding av eksperter (MoE)
Kjernen i Qwen3‑Coder ligger en toppmoderne MoE-design. I motsetning til tette modeller som aktiverer alle parametere for hvert token, engasjerer MoE-arkitekturer selektivt spesialiserte undernettverk (eksperter) skreddersydd for bestemte tokentyper eller oppgaver. I Qwen3‑Coder er 480 milliarder parametere totalt fordelt på tvers av flere eksperter, med bare 35 milliarder parametere aktive per token. Denne tilnærmingen reduserer inferenskostnadene med over 60 % sammenlignet med tilsvarende tette modeller, samtidig som den opprettholder høy kvalitet i kodesyntese og feilsøking.
Tenkemodus og ikke-tenkemodus
Qwen3‑Coder låner fra innovasjonene i den bredere Qwen3-familien og integrerer en dobbeltmodusinferens rammeverk:
- Tenkemodus tildeler et større «tenkebudsjett» til komplekse resonneringsoppgaver med flere trinn, som algoritmedesign eller refaktorering på tvers av filer.
- Ikke-tenkende modus gir raske, kontekstdrevne svar som er egnet for enkle kodefullføringer og API-brukssnutter.
Denne enhetlige modusbytingen eliminerer behovet for å sjonglere separate modeller for chatteoptimaliserte kontra resonnementoptimaliserte oppgaver, noe som effektiviserer utviklernes arbeidsflyter.
Forsterkningslæring med automatisert testcase-syntese
En enestående innovasjon er Qwen3-Coders innebygde kontekstvindu på 256 XNUMX tokener – dobbelt så stor som den typiske kapasiteten til ledende åpne modeller – og støtte for opptil én million tokener via ekstrapoleringsmetoder (f.eks. YaRN). Dette lar modellen behandle hele repositorier, dokumentasjonssett eller flerfilsprosjekter i én omgang, noe som bevarer avhengigheter på tvers av filer og reduserer gjentatte spørsmål. Empiriske tester viser at utvidelse av kontekstvinduer gir avtagende, men fortsatt betydelige gevinster i langsiktig oppgaveytelse, spesielt i miljødrevne forsterkningslæringsscenarier.
Hvordan kan utviklere få tilgang til og bruke Qwen3‑Coder?
Utgivelsesstrategien for Qwen3-Coder vektlegger åpenhet og enkel adopsjon:
- Vekter av åpen kildekode-modellerAlle modellsjekkpunkter er tilgjengelige på GitHub under Apache 2.0, noe som muliggjør full åpenhet og fellesskapsdrevne forbedringer.
- **Kommandolinjegrensesnitt (Qwen-kode)**CLI er forked fra Google Gemini Code, og støtter tilpassede ledetekster, funksjonskall og plugin-arkitekturer for å integreres sømløst med eksisterende byggesystemer og IDE-er.
- Sky- og lokale implementeringerForhåndskonfigurerte Docker-bilder og Kubernetes Helm-diagrammer forenkler skalerbare distribusjoner i skymiljøer, mens lokale kvantiseringsoppskrifter (2–8-bits dynamisk kvantisering) muliggjør effektiv lokal inferens, selv på standard-GPU-er.
- API-tilgang via CometAPIUtviklere kan også samhandle med Qwen3-Coder gjennom vertsbaserte endepunkter på plattformer som CometAPI, som tilbyr åpen kildekode (
qwen3-coder-480b-a35b-instruct) og kommersielle versjoner (qwen3-coder-plus; qwen3-coder-plus-2025-07-22)til samme pris. Den kommersielle versjonen er 1 mill. lang. - Klemme ansiktetAlibaba har gjort Qwen3-Coder-vektene og tilhørende biblioteker fritt tilgjengelige på både Hugging Face og GitHub, pakket under en Apache 2.0-lisens som tillater akademisk og kommersiell bruk uten royalties.
API- og SDK-integrasjon via CometAPI
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører – som OpenAIs GPT-serie, Googles Gemini, Anthropics Claude, Midjourney, Suno og flere – i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering, forenkler CometAPI dramatisk integreringen av AI-funksjoner i applikasjonene dine. Enten du bygger chatboter, bildegeneratorer, musikkomponister eller datadrevne analysepipeliner, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig – alt samtidig som du utnytter de nyeste gjennombruddene på tvers av AI-økosystemet.
Utviklere kan samhandle med Qwen3-koder gjennom et kompatibelt OpenAI-lignende API, tilgjengelig via CometAPI. CometAPI, som tilbyr åpen kildekode (qwen3-coder-480b-a35b-instruct) og kommersielle versjoner (qwen3-coder-plus; qwen3-coder-plus-2025-07-22)til samme pris. Den kommersielle versjonen er 1 MB lang. Eksempelkode for Python (ved bruk av den OpenAI-kompatible klienten) med beste praksis som anbefaler samplingsinnstillinger på temperatur = 0.7, top_p = 0.8, top_k = 20 og repetition_penalty = 1.05. Utdatalengder kan strekke seg opptil 65,536 XNUMX tokens, noe som gjør den egnet for store kodegenereringsoppgaver.
For å begynne, utforsk modellenes muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.
Hurtigstart på Hugging Face og Alibaba Cloud
Utviklere som er ivrige etter å eksperimentere med Qwen3‑Coder kan finne modellen på Hugging Face under repositoriet. Qwen/Qwen3‑koder‑480B‑A35B‑instruksjonIntegrasjonen er strømlinjeformet via transformers bibliotek (versjon ≥ 4.51.0 for å unngå KeyError: 'qwen3_moe') og OpenAI-kompatible Python-klienter. Et minimalt eksempel:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
Definere tilpassede verktøy og agentarbeidsflyter
En av Qwen3‑Coders mest fremtredende funksjoner er dynamisk verktøypåkallingUtviklere kan registrere eksterne verktøy – lintere, formatterere, testkjørere – og la modellen kalle dem autonomt under en kodeøkt. Denne funksjonen forvandler Qwen3-Coder fra en passiv kodeassistent til en aktiv kodeagent, som er i stand til å kjøre tester, justere kodestil og til og med distribuere mikrotjenester basert på samtaleintensjoner.
Hvilke potensielle bruksområder og fremtidige retninger muliggjør Qwen3‑Coder?
Ved å kombinere åpen kildekode-frihet med ytelse i bedriftsklassen baner Qwen3-Coder vei for en ny generasjon AI-drevne utviklingsverktøy. Fra automatiserte koderevisjoner og sikkerhetskontroller til kontinuerlige refaktoreringstjenester og AI-drevne dev-ops-assistenter, inspirerer modellens allsidighet allerede både oppstartsbedrifter og interne innovasjonsteam.
Arbeidsflyter for programvareutvikling
Tidlige brukere rapporterer en reduksjon på 30–50 prosent i tid brukt på standardkoding, avhengighetshåndtering og innledende stillasering, slik at ingeniører kan fokusere på design- og arkitekturoppgaver med høy verdi. Kontinuerlige integrasjonspakker kan utnytte Qwen3-Coder til å automatisk generere tester, oppdage regresjoner og til og med foreslå ytelsesoptimaliseringer basert på sanntidskodeanalyse.
Enterprises Play
Etter hvert som selskaper innen finans, helsevesen og e-handel integrerer Qwen3-Coder i forretningskritiske systemer, vil tilbakemeldingsløkker mellom brukerteam og Alibabas FoU akselerere forbedringer – som domenespesifikk finjustering, forbedrede sikkerhetsprotokoller og strammere IDE-plugins. Dessuten oppmuntrer Alibabas åpen kildekode-strategi til bidrag fra det globale samfunnet, noe som fremmer et levende økosystem av utvidelser, referanseindekser og biblioteker for beste praksis.
Konklusjon
Oppsummert representerer Qwen3-Coder en milepæl innen åpen kildekode-AI for programvareutvikling: en kraftig, agentisk modell som ikke bare skriver kode, men orkestrerer hele utviklingsprosessen med minimal menneskelig tilsyn. Ved å gjøre teknologien fritt tilgjengelig og enkel å integrere, demokratiserer Alibaba tilgangen til avanserte AI-verktøy og legger grunnlaget for en æra der programvareutvikling blir stadig mer samarbeidsbasert, effektiv og intelligent.
Spørsmål og svar
Hva gjør Qwen3‑Coder «agentisk»?
Agentisk AI refererer til modeller som kan planlegge og utføre flertrinnsoppgaver autonomt. Qwen3-Coders evne til å aktivere eksterne verktøy, kjøre tester og administrere kodebaser uten menneskelig inngripen eksemplifiserer dette paradigmet.
Er Qwen3‑Coder egnet for produksjonsbruk?
Selv om Qwen3‑Coder viser sterk ytelse på benchmarks og tester i den virkelige verden, bør bedrifter gjennomføre domenespesifikke evalueringer og implementere tiltak (f.eks. pipelines for utdataverifisering) før de integrerer det i kritiske produksjonsarbeidsflyter.
Hvordan gagner arkitekturen «Mixture-of-Experts» utviklere?
MoE reduserer inferenskostnader ved å kun aktivere relevante delnettverk per token, noe som muliggjør raskere generering og lavere beregningskostnader. Denne effektiviteten er avgjørende for å skalere AI-kodingsassistenter i skymiljøer.