
Qwen3-Max-Preview er Alibabas nyeste flaggskip-forhåndsvisningsmodell i Qwen3-familien – en modell i Mixture-of-Experts (MoE)-stil med over billioner parametere og et ultralangt kontekstvindu på 262 XNUMX tokener, utgitt i forhåndsvisning for bedrifts-/skybruk. Den er rettet mot *dyp resonnering, forståelse av lange dokumenter, koding og agentarbeidsflyter.
Grunnleggende informasjon og overskrifter
- Navn / Etikett:
qwen3-max-preview(Undervise). - Scale: Over 1 billion parametere (flaggskip med billioner av parametere). Dette er den viktigste markedsførings-/statistikkmilepælen for utgivelsen.
- Kontekstvindu: 262,144-symboler (støtter svært lange inndata og transkripsjoner av flere filer).
- Modus(er): Instruksjonsinnstilt «Instruct»-variant med støtte for tenker (bevisst tankekjede) og ikke-tenkende raske moduser i Qwen3-familien.
- Tilgjengelighet: Forhåndsvisningstilgang via Qwen Chat, Alibaba Cloud Model Studio (OpenAI-kompatible eller DashScope-endepunkter) og rutingsleverandører som CometAPI.
Tekniske detaljer (arkitektur og moduser)
- Arkitektur: Qwen3-Max følger Qwen3-designlinjen som bruker en blanding av tett + Ekspertblanding (MoE) komponenter i større varianter, pluss tekniske valg for å optimalisere inferenseffektiviteten for svært store parameterantall.
- Tenkemodus kontra ikke-tenkemodus: Qwen3-serien introduserte en tenkemodus (for utganger i flertrinns tankekjedestil) og ikke-tenkende modus for raskere og mer konsise svar; plattformen eksponerer parametere for å veksle mellom disse atferdene.
- Kontekstbuffering / ytelsesfunksjoner: Model Studio-lister kontekstbuffer støtte for store forespørsler for å redusere gjentatte inndatakostnader og forbedre gjennomstrømningen i gjentatte kontekster.
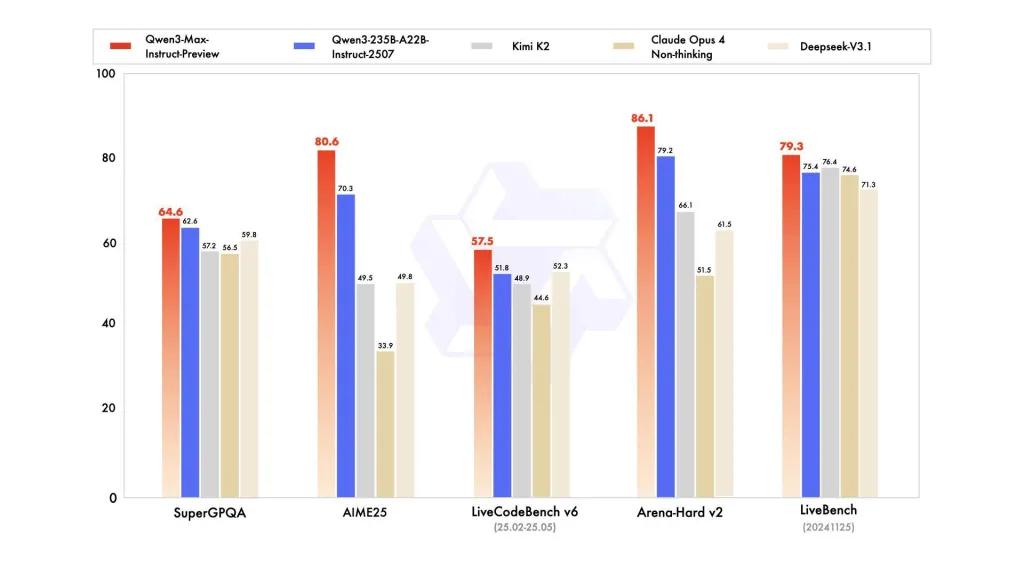
Benchmark ytelse
Rapporter refererer til SuperGPQA, LiveCodeBench-varianter, AIME25 og andre konkurranse-/benchmark-suiter der Qwen3-Max ser ut til å være konkurransedyktig eller ledende.
Begrensninger og risikoer (praktiske og sikkerhetsmessige merknader)
- Opasitet for full treningsoppskrift / vekter: Som en forhåndsvisning kan det fullstendige opplærings-/data-/vektutgivelses- og reproduserbarhetsmaterialet være begrenset sammenlignet med tidligere Qwen3-utgivelser med åpen vekt. Noen Qwen3-familiemodeller ble utgitt med åpen vekt, men Qwen3-Max leveres som en kontrollert forhåndsvisning for skytilgang. reduserer reproduserbarheten for uavhengige forskere.
- Hallusinasjoner og fakta: Leverandørrapporter hevder reduksjoner i hallusinasjoner, men bruk i den virkelige verden vil fortsatt finne faktiske feil og overdrevne påstander – standard LLM-forbehold gjelder. Uavhengig evaluering er nødvendig før utrulling med høy innsats.
- Kostnad i stor skala: Med et stort kontekstvindu og høy kapasitet, tokenkostnader kan være betydelig for svært lange ledetekster eller produksjonsgjennomstrømning. Bruk mellomlagring, chunking og budsjettkontroller.
- Hensyn knyttet til regulatoriske forhold og datasuverenitet: Bedriftsbrukere bør sjekke Alibaba Cloud-regioner, dataopphold og samsvarsimplikasjoner før de behandler sensitiv informasjon. (Model Studio-dokumentasjonen inkluderer regionspesifikke endepunkter og merknader.)
Bruksmåter
- Dokumentforståelse / oppsummering i stor skala: juridiske briefinger, tekniske spesifikasjoner og kunnskapsbaser med flere filer (fordel: 262 XNUMX token vindu).
- Langkontekstkoderesonnement og kodehjelp på repositoriumsnivå: forståelse av kode i flere filer, store PR-gjennomganger, forslag til refaktorering på repository-nivå.
- Kompleks resonnement og tankekjedeoppgaver: mattekonkurranser, planlegging i flere trinn, agentiske arbeidsflyter der «tenke»-spor hjelper sporbarheten.
- Flerspråklig, spørsmål og svar for bedrifter og strukturert datautvinning: støtte for store flerspråklige korpus og strukturerte utdatamuligheter (JSON/tabeller).
Slik kaller du Qqwen3-max-preview API fra CometAPI
qwen3-max-preview API-priser i CometAPI, 20 % avslag på den offisielle prisen:
| Skriv inn tokens | $0.24 |
| Output tokens | $2.42 |
Nødvendige trinn
- Logg på cometapi.com. Hvis du ikke er vår bruker ennå, vennligst registrer deg først
- Få tilgangslegitimasjons-API-nøkkelen til grensesnittet. Klikk "Legg til token" ved API-tokenet i det personlige senteret, hent tokennøkkelen: sk-xxxxx og send inn.
- Få url til dette nettstedet: https://api.cometapi.com/
Bruk metoden
- Velg endepunktet «qwen3-max-preview» for å sende API-forespørselen og angi forespørselsteksten. Forespørselsmetoden og forespørselsteksten er hentet fra nettstedets API-dokumentasjon. Nettstedet vårt tilbyr også Apifox-testing for enkelhets skyld.
- Erstatt med din faktiske CometAPI-nøkkel fra kontoen din.
- Sett inn spørsmålet eller forespørselen din i innholdsfeltet – det er dette modellen vil svare på.
- . Behandle API-svaret for å få det genererte svaret.
API-kall
CometAPI tilbyr et fullt kompatibelt REST API – for sømløs migrering. Viktige detaljer for API-dok:
- Kjerneparametere:
prompt,max_tokens_to_sample,temperature,stop_sequences - endepunkt:
https://api.cometapi.com/v1/chat/completions - Modellparameter: qwen3-max-forhåndsvisning
- Autentisering:
Bearer YOUR_CometAPI_API_KEY - Innholdstype:
application/json.
Erstatt
CometAPI_API_KEYmed nøkkelen din; merk deg basis-URL.
Python (forespørsler) – OpenAI-kompatibel
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Tips: bruke max_input_tokens, max_output_tokensog Model Studios kontekstbuffer funksjoner når du sender veldig store kontekster for å kontrollere kostnader og gjennomstrømning.
Se også Qwen3-koder