

19.–20. november 2025 lanserte OpenAI to beslektede, men ulike oppgraderinger: GPT-5.1-Codex-Max, en ny agentisk kodemodell for Codex som vektlegger langsiktig koding, token-effektivitet og «kompaktering» for å opprettholde økter med flere vinduer; og GPT-5.1 Pro, en oppdatert ChatGPT-modell på Pro-nivå, tunet for klarere og mer kapable svar i komplekst, profesjonelt arbeid.
Hva er GPT-5.1-Codex-Max, og hvilket problem prøver den å løse?
GPT-5.1-Codex-Max er en spesialisert Codex-modell fra OpenAI, tilpasset kodearbeidsflyter som krever vedvarende, langsiktig resonnering og utførelse. Der vanlige modeller kan snuble i svært lange kontekster — for eksempel multifil-refaktoriseringer, komplekse agent-løkker eller vedvarende CI/CD-oppgaver — er Codex-Max designet for å automatisk kompaktere og håndtere økt-tilstand på tvers av flere kontekstvinduer, slik at den kan fortsette å arbeide sammenhengende når ett prosjekt spenner over mange tusen (eller flere) tokens. OpenAI posisjonerer Codex-Max som neste steg mot å gjøre kodekapable agenter genuint nyttige for langvarig ingeniørarbeid.
Hva er GPT-5.1-Codex-Max, og hvilket problem prøver den å løse?
GPT-5.1-Codex-Max er en spesialisert Codex-modell fra OpenAI, tilpasset kodearbeidsflyter som krever vedvarende, langsiktig resonnering og utførelse. Der vanlige modeller kan snuble i svært lange kontekster — for eksempel multifil-refaktoriseringer, komplekse agent-løkker eller vedvarende CI/CD-oppgaver — er Codex-Max designet for å automatisk kompaktere og håndtere økt-tilstand på tvers av flere kontekstvinduer, slik at den kan fortsette å arbeide sammenhengende når ett prosjekt spenner over mange tusen (eller flere) tokens.
Den beskrives av OpenAI som «raskere, mer intelligent og mer tokeneffektiv i alle faser av utviklingssyklusen», og er eksplisitt ment å erstatte GPT-5.1-Codex som standardmodellen i Codex-grensesnitt.
Funksjonsoversikt
- Kompaktering for kontinuitet på tvers av flere vinduer: beskjærer og bevarer kritisk kontekst for å jobbe sammenhengende over millioner av tokens og timer. 0
- Forbedret token-effektivitet sammenlignet med GPT-5.1-Codex: opptil ~30 % færre «thinking»-tokens for tilsvarende resonneringsinnsats på noen kode-benchmarker.
- Langsiktig agentisk robusthet: internt observert å opprettholde fler-timers/fler-dagers agent-løkker (OpenAI dokumenterte >24-timers interne kjøringer).
- Plattformintegrasjoner: tilgjengelig i dag i Codex CLI, IDE-utvidelser, skyen og kodegjennomgangsverktøy; API-tilgang kommer.
- Støtte for Windows-miljø: OpenAI påpeker spesielt at Windows støttes for første gang i Codex-arbeidsflyter, noe som utvider rekkevidden til utviklere i praksis.
Hvordan sammenlignes den med konkurrerende produkter (f.eks. GitHub Copilot, andre kode-KI-er)?
GPT-5.1-Codex-Max posisjoneres som en mer autonom, langsiktig samarbeidspartner sammenlignet med verktøy for enkeltvise utfyllinger. Mens Copilot og lignende assistenter utmerker seg ved kortsiktige forslag i editoren, ligger Codex-Max sine styrker i å orkestrere flertrinnsoppgaver, opprettholde en sammenhengende tilstand på tvers av økter, og håndtere arbeidsflyter som krever planlegging, testing og iterasjon. Når det er sagt, er den beste tilnærmingen i de fleste team ofte hybrid: bruk Codex-Max for kompleks automatisering og vedvarende agent-oppgaver, og bruk lettere assistenter for linjenivåforslag.
Hvordan fungerer GPT-5.1-Codex-Max?
Hva er «kompaktering», og hvordan muliggjør det langvarig arbeid?
Et sentralt teknisk fremskritt er kompaktering — en intern mekanisme som beskjærer økt-historikk samtidig som de vesentlige delene av konteksten bevares, slik at modellen kan fortsette sammenhengende arbeid på tvers av flere kontekstvinduer. I praksis betyr det at Codex-økter som nærmer seg kontekstgrensen vil bli kompaktert (eldre eller mindre verdifulle tokens oppsummeres/bevares), slik at agenten får et nytt vindu og kan fortsette å iterere gjentatte ganger til oppgaven er fullført. OpenAI rapporterer interne kjøringer der modellen jobbet kontinuerlig i mer enn 24 timer.
Adaptiv resonnering og token-effektivitet
GPT-5.1-Codex-Max benytter forbedrede resonneringsstrategier som gjør den mer tokeneffektiv: I OpenAIs rapporterte interne benchmarker oppnår Max-modellen lik eller bedre ytelse enn GPT-5.1-Codex samtidig som den bruker betydelig færre «tenke»-tokens — OpenAI viser til omtrent 30 % færre «thinking»-tokens på SWE-bench Verified ved lik resonneringsinnsats. Modellen introduserer også en «Extra High (xhigh)»-modus for resonneringsinnsats i ikke-latensfølsomme oppgaver, som lar den bruke mer intern resonnering for å gi høyere kvalitetsutdata.
Systemintegrasjoner og agentisk verktøy
Codex-Max distribueres innen Codex-arbeidsflyter (CLI, IDE-utvidelser, sky og kodegjennomgangsflater) slik at den kan samhandle med faktiske utviklerverktøykjeder. Tidlige integrasjoner inkluderer Codex CLI og IDE-agenter (VS Code, JetBrains, osv.), med API-tilgang planlagt i etterkant. Designmålet er ikke bare smartere kodesyntese, men en KI som kan kjøre flertrinnsarbeidsflyter: åpne filer, kjøre tester, rette feil, refaktorere og kjøre på nytt.
Hvordan presterer GPT-5.1-Codex-Max på benchmarker og i virkelig arbeid?
Vedvarende resonnering og langsiktige oppgaver
Evalueringer peker på målbare forbedringer i vedvarende resonnering og langhorisont-oppgaver:
- OpenAIs interne evalueringer: Codex-Max kan jobbe med oppgaver i «mer enn 24 timer» i interne eksperimenter, og integrering av Codex med utviklerverktøy økte interne ingeniørproduktivitet-metrikker (f.eks. bruk og throughput for pull requests). Dette er OpenAIs interne påstander og indikerer oppgavenivåforbedringer i produktivitet i virkeligheten.
- Uavhengige evalueringer (METR): METRs uavhengige rapport målte den observed 50% time horizon (en statistikk som representerer medianen for hvor lenge modellen sammenhengende kan opprettholde en lang oppgave) for GPT-5.1-Codex-Max til omtrent 2 timer 40 minutter (med et bredt konfidensintervall), opp fra GPT-5s 2 timer 17 minutter i sammenlignbare målinger — en meningsfull forbedring i vedvarende koherens. METRs metode og konfidensintervaller vektlegger variasjon, men resultatet støtter narrativet om at Codex-Max forbedrer praktisk langhorisont-ytelse.
Kodebenchmarker
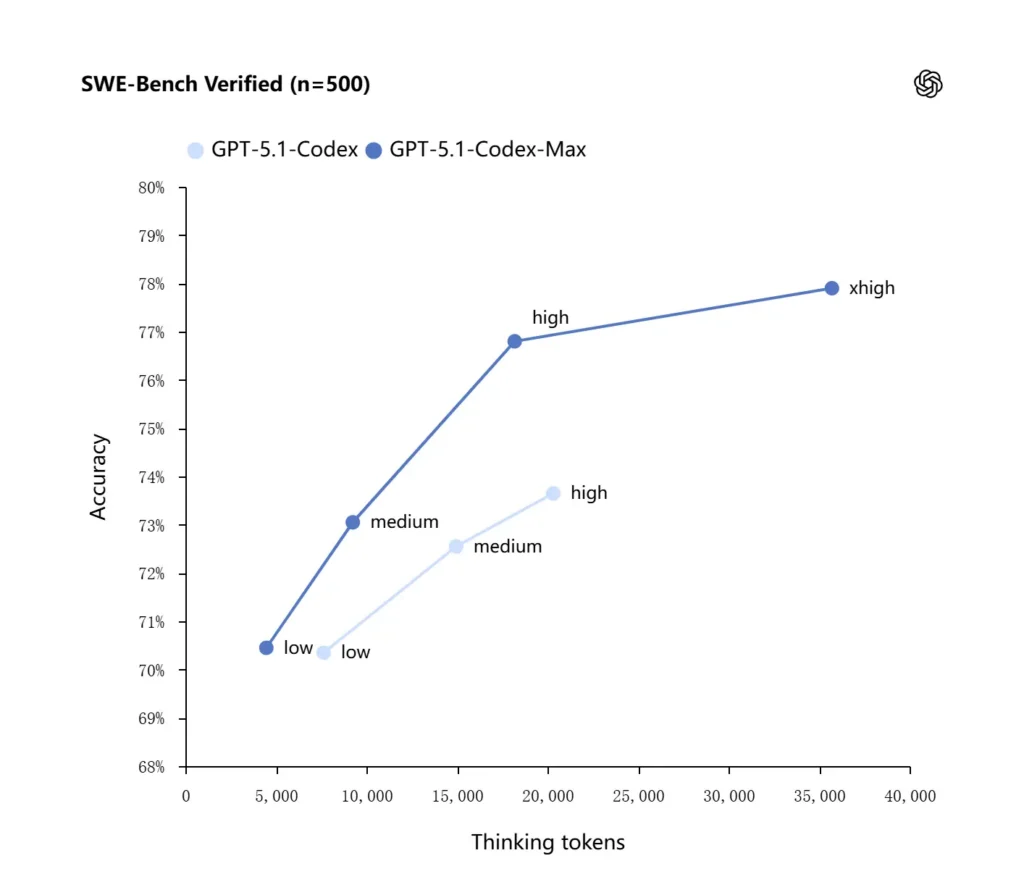
OpenAI rapporterer forbedrede resultater på avanserte kodeevalueringer, særlig SWE-bench Verified der GPT-5.1-Codex-Max overgår GPT-5.1-Codex med bedre token-effektivitet. Selskapet fremhever at for samme «medium» resonneringsinnsats gir Max-modellen bedre resultater samtidig som den bruker omtrent 30 % færre «thinking»-tokens; for brukere som tillater lengre intern resonnering, kan xhigh-modusen ytterligere heve svarene på bekostning av latens.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
Hvordan sammenlignes GPT-5.1-Codex-Max med GPT-5.1-Codex?
Forskjeller i ytelse og formål
- Omfang: GPT-5.1-Codex var en høyytelses kodevariant av GPT-5.1-familien; Codex-Max er uttrykkelig en agentisk, langsiktig etterfølger som er ment å være anbefalt standard i Codex- og Codex-lignende miljøer.
- Token-effektivitet: Codex-Max viser vesentlige gevinster i token-effektivitet (OpenAIs ~30 % færre «thinking»-tokens) på SWE-bench og i intern bruk.
- Konteksthåndtering: Codex-Max introduserer kompaktering og innebygd fler-vindu-håndtering for å opprettholde oppgaver som overskrider ett enkelt kontekstvindu; Codex ga ikke denne muligheten i samme skala.
- Verktøystatus: Codex-Max leveres som standardmodellen i Codex på tvers av CLI, IDE og kodegjennomgangsflater, og signaliserer en migrering for produksjonsklare utviklerarbeidsflyter.
Når bør du bruke hvilken modell?
- Bruk GPT-5.1-Codex for interaktiv kodehjelp, raske endringer, små refaktoriseringer og lav-latens-brukstilfeller der all relevant kontekst enkelt får plass i ett vindu.
- Bruk GPT-5.1-Codex-Max for multifil-refaktoriseringer, automatiserte agent-oppgaver som krever mange iterasjoner, CI/CD-lignende arbeidsflyter, eller når du trenger at modellen holder et prosjektnivåperspektiv på tvers av mange interaksjoner.
Praktiske prompt-mønstre og eksempler for best resultater?
Prompt-mønstre som fungerer godt
- Vær eksplisitt om mål og begrensninger: «Refaktorer X, bevar offentlig API, behold funksjonsnavn, og sørg for at testene A, B, C består.»
- Gi minimal, reproduserbar kontekst: lenk til feilet test, inkluder stack traces og relevante filutdrag i stedet for å dumpe hele repoer. Codex-Max vil kompaktere historikk ved behov.
- Bruk trinnvise instruksjoner for komplekse oppgaver: del store jobber opp i en sekvens av deloppgaver, og la Codex-Max iterere gjennom dem (f.eks. «1) kjør tester 2) fiks de 3 mest feilende testene 3) kjør linter 4) oppsummer endringer»).
- Be om forklaringer og diffs: be om både patchen og en kort begrunnelse slik at menneskelige anmeldere raskt kan vurdere sikkerhet og intensjon.
Eksempel-maler for prompt
Refaktoreringsoppgave
«Refactor the
payment/module to extract payment processing intopayment/processor.py. Keep public function signatures stable for existing callers. Create unit tests forprocess_payment()that cover success, network failure, and invalid card. Run the test suite and return failing tests and a patch in unified diff format.»
Feilretting + test
«A test
tests/test_user_auth.py::test_token_refreshfails with traceback . Investigate root cause, propose a fix with minimal changes, and add a unit test to prevent regression. Apply patch and run tests.»
Iterativ PR-generering
«Implement feature X: add endpoint
POST /api/exportwhich streams export results and is authenticated. Create the endpoint, add docs, create tests, and open a PR with summary and checklist of manual items.»
For de fleste av disse, start med medium innsats; bytt til xhigh når du trenger at modellen skal gjøre dyp resonnering på tvers av mange filer og flere testrunder.
Hvordan får du tilgang til GPT-5.1-Codex-Max
Hvor den er tilgjengelig i dag
OpenAI har integrert GPT-5.1-Codex-Max i Codex-verktøy i dag: Codex CLI, IDE-utvidelser, skyen og kodegjennomgangsstrømmer bruker Codex-Max som standard (du kan velge Codex-Mini). API-tilgjengelighet forberedes; GitHub Copilot har offentlige forhåndsvisninger som inkluderer GPT-5.1- og Codex-seriemodeller.
Utviklere kan få tilgang til GPT-5.1-Codex-Max og GPT-5.1-Codex API via CometAPI. For å komme i gang, utforsk modellkapabilitetene til CometAPI i Playground og se API-guiden for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du er logget inn på CometAPI og har hentet API-nøkkelen. CometAPI tilbyr en pris langt lavere enn den offisielle prisen for å hjelpe deg å integrere.
Klar til å starte?→ Registrer deg for CometAPI i dag!
Hvis du vil ha flere tips, guider og nyheter om KI, følg oss på VK, X og Discord!
Hurtigstart (praktisk steg-for-steg)
- Sørg for at du har tilgang: bekreft at ChatGPT/Codex-produktplanen din (Plus, Pro, Business, Edu, Enterprise) eller utvikler-API-planen din støtter GPT-5.1-/Codex-familiemodeller.
- Installer Codex CLI eller IDE-utvidelse: hvis du vil kjøre kodeoppgaver lokalt, installer Codex CLI eller Codex IDE-utvidelsen for VS Code / JetBrains / Xcode der det passer. Verktøyet vil bruke GPT-5.1-Codex-Max som standard i støttede oppsett.
- Velg resonneringsinnsats: start med medium innsats for de fleste oppgaver. For dyp debugging, komplekse refaktoriseringer, eller når du vil at modellen skal tenke mer og du ikke bryr deg om svartid, bytt til high eller xhigh. For små raske fiks, er low rimelig.
- Gi repository-kontekst: gi modellen et klart startpunkt — en repo-URL eller et sett med filer og en kort instruksjon (f.eks. «refaktorer payment-modulen til å bruke async I/O og legg til enhetstester, behold funksjonskontraktene»). Codex-Max vil kompaktere historikk når den nærmer seg kontekstgrenser og fortsette jobben.
- Iterer med tester: etter at modellen har produsert patcher, kjør testpakker og mat tilbake feil som del av den pågående økten. Kompaktering og kontinuitet på tvers av flere vinduer lar Codex-Max beholde viktig kontekst fra feilede tester og iterere.
Konklusjon:
GPT-5.1-Codex-Max representerer et betydelig steg mot agentiske kodeassistenter som kan opprettholde komplekse, langvarige ingeniøroppgaver med forbedret effektivitet og resonnering. De tekniske fremskrittene (kompaktering, moduser for resonneringsinnsats, opplæring for Windows-miljø) gjør den spesielt godt egnet for moderne ingeniørorganisasjoner — forutsatt at team kombinerer modellen med konservative driftskontroller, klare «mennesket-i-løkken»-policyer og robust overvåking. For team som tar den i bruk med omhu, har Codex-Max potensiale til å endre hvordan programvare designes, testes og vedlikeholdes — og gjøre repetitivt ingeniørarbeid om til et mer verdiskapende samarbeid mellom mennesker og modeller.