

DeepSeek har lansert DeepSeek V3.2 som etterfølgeren til V3.x-serien og en ledsagende variant, DeepSeek-V3.2-Speciale, som selskapet posisjonerer som en høyytelses, resonnement-først-utgave for bruk i agenter/verktøy. V3.2 bygger på eksperimentelt arbeid (V3.2-Exp) og introduserer høyere resonneringsevne, en Speciale-utgave optimalisert for «gull-nivå» ytelse i matematikk/konkurranseprogrammering, og det DeepSeek beskriver som et først-i-sitt-slag to-modus «tenking + verktøy»-system som tett integrerer intern steg-for-steg-resonnering med ekstern verktøykalling og agent-arbeidsflyter.
Hva er DeepSeek V3.2 — og hvordan skiller V3.2-Speciale seg?
DeepSeek-V3.2 er den offisielle etterfølgeren til DeepSeeks eksperimentelle V3.2-Exp-gren. DeepSeek beskriver den som en «resonnerings-først» modellfamilie bygget for agenter, dvs. modeller som er trent ikke bare for naturlig samtalekvalitet, men spesielt for flertrinns inferens, verktøykalling og pålitelig trinnvis resonnement i miljøer som inkluderer eksterne verktøy (API-er, kodekjøring, datakoblere).
Hva er DeepSeek-V3.2 (basis)
- Posisjonert som den ordinære produksjonsetterfølgeren til den eksperimentelle V3.2-Exp-linjen; ment for bred tilgjengelighet via DeepSeeks app/nett/API.
- Bevarer en balanse mellom beregningseffektivitet og robust resonnement for agent-oppgaver.
Hva er DeepSeek-V3.2-Speciale
DeepSeek-V3.2-Speciale er en variant som DeepSeek markedsfører som en høyere-kapasitets «Special Edition» finstemt for konkurransenivå-resonnement, avansert matematikk og agentytelse. Markedsført som en variant med høyere kapasitet som «flytter grensene for resonnementsevner». DeepSeek tilbyr per nå Speciale som en API-kun-modell med midlertidig tilgangsruting; tidlige benchmarker antyder at den er posisjonert for å konkurrere med høyende lukkede modeller i resonnement- og kodebenchmarker.
Hvilken arv og hvilke ingeniørvalg ledet til V3.2?
V3.2 arver en rekke iterative ingeniørgrep som DeepSeek offentliggjorde gjennom 2025: V3 → V3.1 (Terminus) → V3.2-Exp (et eksperimentelt steg) → V3.2 → V3.2-Speciale. Den eksperimentelle V3.2-Exp introduserte DeepSeek Sparse Attention (DSA) — en finkornet sparse attention-mekanisme som sikter mot å senke minne- og beregningskostnader for svært lange kontekstvinduer samtidig som den bevarer utdata-kvaliteten. DSA-forskningen og kostnadsreduksjonsarbeidet fungerte som en teknisk springplanke for den offisielle V3.2-familien.
Hva er nytt i offisielle DeepSeek 3.2?
1) Forbedret resonneringsevne — hvordan er resonnementet forbedret?
DeepSeek markedsfører V3.2 som «resonnerings-først». Det betyr at arkitektur og finjustering fokuserer på å utføre flertrinns inferens pålitelig, opprettholde interne resonneringskjeder og støtte den typen strukturert overveielse agenter trenger for å bruke eksterne verktøy korrekt.
Konkret omfatter forbedringene:
- Opplæring og RLHF (eller tilsvarende tilpasningsprosedyrer) finstemt for å oppmuntre eksplisitt trinnvis problemløsning og stabile mellomtilstander (nyttig for matematisk resonnement, flertrinns kodegenerering og logiske oppgaver).
- Arkitektur- og tapsfunksjonsvalg som bevarer lengre kontekstvinduer og lar modellen referere til tidligere resonneringstrinn med høy trofasthet.
- Praktiske moduser (se «to-modus» nedenfor) som lar samme modell operere enten i en raskere «chat»-stil-modus eller i en mer overveiende «tenke»-modus der den bevisst arbeider gjennom mellomtrinn før den handler.
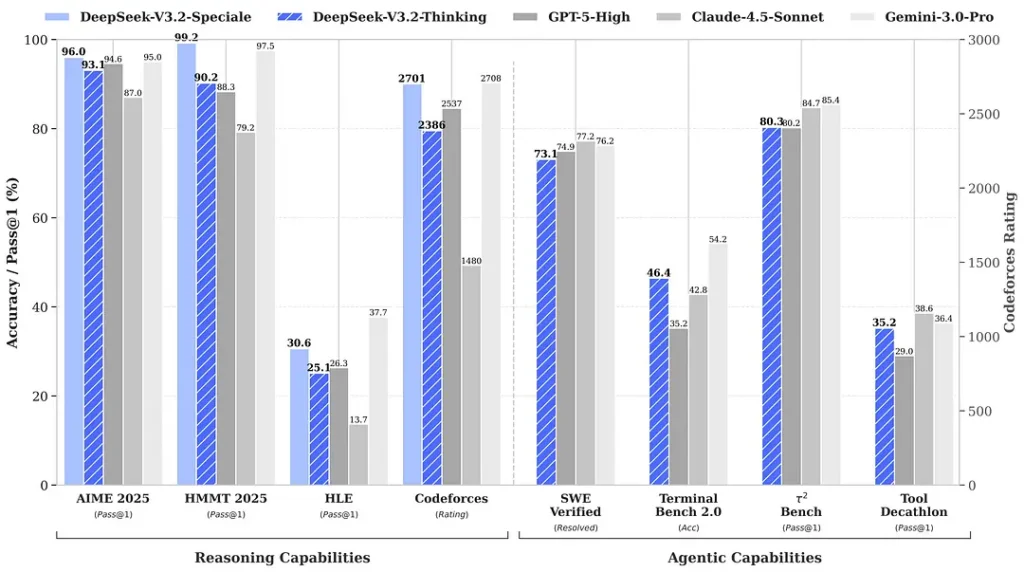
Benchmarker rundt lanseringen hevder merkbare gevinster i matte- og resonnementstester; uavhengige tidlige fellesskapsbenchmarker rapporterer også imponerende resultater på konkurransesett:
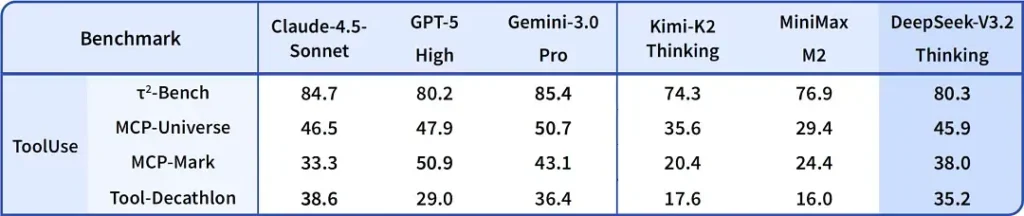
2) Gjennombruddsytelse i Special Edition — hvor mye bedre?
DeepSeek-V3.2-Speciale hevdes å levere et trinn opp i resonneringsnøyaktighet og agentorkestrering sammenlignet med standard V3.2. Leverandøren rammer inn Speciale som et ytelsesnivå målrettet mot tunge resonnementslaster og krevende agentoppgaver; den er for øyeblikket kun tilgjengelig via API og tilbys som et midlertidig, mer kapabelt endepunkt (DeepSeek har indikert at Speciale-tilgjengeligheten vil være begrenset innledningsvis). Speciale-versjonen integrerer den tidligere matematiske modellen DeepSeek-Math-V2; den kan bevise matematiske teoremer og verifisere logisk resonnement på egen hånd; den har oppnådd bemerkelsesverdige resultater i flere verdensklasse-konkurranser:
- 🥇 IMO (International Mathematical Olympiad) Gullmedalje
- 🥇 CMO (Chinese Mathematical Olympiad) Gullmedalje
- 🥈 ICPC (International Computer Programming Contest) Andreplass (menneskelig konkurranse)
- 🥉 IOI (International Olympiad in Informatics) Tiendeplass (menneskelig konkurranse)
| Benchmark | GPT-5 High | Gemini-3.0 Pro | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | DeepSeek-V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025 | 94.6 (13k) | 95.0 (15k) | 94.5 (24k) | 93.1 (16k) | 96.0 (23k) |
| HMMT Feb 2025 | 88.3 (16k) | 97.5 (16k) | 89.4 (31k) | 92.5 (19k) | 99.2 (27k) |
| HMMT Nov 2025 | 89.2 (20k) | 93.3 (15k) | 89.2 (29k) | 90.2 (18k) | 94.4 (25k) |
| IMOAnswerBench | 76.0 (31k) | 83.3 (18k) | 78.6 (37k) | 78.3 (27k) | 84.5 (45k) |
| LiveCodeBench | 84.5 (13k) | 90.7 (13k) | 82.6 (29k) | 83.3 (16k) | 88.7 (27k) |
| CodeForces | 2537 (29k) | 2708 (22k) | — | 2386 (42k) | 2701 (77k) |
| GPQA Diamond | 85.7 (8k) | 91.9 (8k) | 84.5 (12k) | 82.4 (7k) | 85.7 (16k) |
| HLE | 26.3 (15k) | 37.7 (15k) | 23.9 (24k) | 25.1 (21k) | 30.6 (35k) |
3) Førstegangsimplementering av et to-modus «tenking + verktøy»-system
En av de mest praktisk interessante påstandene i V3.2 er en to-modus arbeidsflyt som skiller (og lar deg velge mellom) rask samtaleoperasjon og en tregere, mer overveiende «tenke»-modus som er tett integrert med verktøybruk.
- «Chat / rask»-modus: Designet for lav latens, brukerrettet chat med konsise svar og færre interne resonneringsspor — bra for uformell hjelp, korte spørsmål/svar og hastighetsfølsomme applikasjoner.
- «Tenking / resonnering»-modus: Optimalisert for rigorøs kjede av tanker, trinnvis planlegging og orkestrering av eksterne verktøy (API-er, databaseforespørsler, kodekjøring). I tenkemodus produserer modellen mer eksplisitte mellomtrinn, som kan inspiseres eller brukes til å drive sikre, korrekte verktøykall i agentsystemer.
Dette mønsteret (en to-modus-design) var til stede i tidligere eksperimentelle grener, og DeepSeek har integrert det dypere i V3.2 og Speciale — Speciale støtter for øyeblikket kun tenkemodus (derav API-begrensningen). Evnen til å veksle mellom hastighet og overveielse er verdifull for ingeniørarbeid fordi den lar utviklere velge riktig kompromiss mellom latens og pålitelighet når de bygger agenter som må samhandle med virkelige systemer.
Hvorfor det er bemerkelsesverdig: Mange moderne systemer tilbyr enten en sterk kjede-av-tanker-modell (for å forklare resonnement) eller et separat lag for agent/verktøy-orkestrering. DeepSeeks innramming antyder en tettere kobling — modellen kan «tenke» og deretter deterministisk kalle verktøy, og bruke verktøysvar til å informere videre tenkning — som er mer sømløst for utviklere som bygger autonome agenter.
Hvor får du DeepSeek v3.2
Kort svar — du kan få DeepSeek v3.2 på flere måter avhengig av behov:
- Offisiell web/app (bruk på nett) — prøv DeepSeeks nettgrensesnitt eller mobilapp for å bruke V3.2 interaktivt.
- API-tilgang — DeepSeek eksponerer V3.2 via sitt API (dokumentasjon inkluderer modellnavn /
base_urlog priser). Registrer deg for en API-nøkkel og kall v3.2-endepunktet. - Nedlastbare/åpne vekter (Hugging Face) — modellen (V3.2 / V3.2-Exp-varianter) er publisert på Hugging Face og kan lastes ned (open-weight). Bruk
huggingface-hubellertransformersfor å hente filene. - CometAPI — En AI-API-aggregasjonsplattform som tilbyr hostede endepunkter for V3.2-Exp. Prisen er lavere enn den offisielle prisen.
Noen praktiske merknader:
- Hvis du vil ha vekter for lokal kjøring, gå til modellens side på Hugging Face (godta lisens/tilgangsbetingelser der) og bruk
huggingface-cliellertransformersfor å laste ned; GitHub-repoet viser vanligvis de eksakte kommandoene. - Hvis du vil ha produksjonsbruk via API, følg dokumentasjonen på plattformen du ønsker, for eksempel CometAPI, for endepunktsnavn og korrekt
base_urlfor V3.2-varianten.
DeepSeek-V3.2-Speciale:* Kun åpen for forskningsbruk, støtter «Thinking Mode»-dialog, men støtter ikke verktøykall.
- Maksimalt utdata kan nå 128K tokens (ekstra lang Thinking Chain).
- For øyeblikket gratis å teste til 15. desember 2025.
Avsluttende tanker
DeepSeek-V3.2 representerer et meningsfullt steg i modningen av resonnement-sentriske modeller. Kombinasjonen av forbedret flertrinnsresonnering, spesialiserte høyytelsesutgaver (Speciale) og en produksjonsklar «tenking + verktøy»-integrasjon er bemerkelsesverdig for alle som bygger avanserte agenter, kodeassistenter eller forskningsarbeidsflyter som må flette sammen overveielse med eksterne handlinger.
Utviklere kan få tilgang til DeepSeek V3.2 via CometAPI. For å begynne, utforsk modellfunksjonene i CometAPI i Playground og se API guide for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du er innlogget på CometAPI og har fått en API-nøkkel. CometAPI tilbyr en pris langt under den offisielle prisen for å hjelpe deg å integrere.
Klar til å komme i gang?→ Registrer deg for CometAPI i dag!
Hvis du vil ha flere tips, veiledninger og nyheter om AI, følg oss på VK, X og Discord!