

Gemini Embedding 2 er Googles første nativt multimodale embedding-modell som kartlegger tekst, bilder, lyd, video og PDF-er til ett enkelt semantisk vektorrom med 3,072 dimensjoner (med konfigurerbare utgangsstørrelser). Den introduserer Matryoshka Representation Learning for å tilby nestede / trunkerte embeddinger, forbedret flerspråklig ytelse (100+ språk), og optimaliserte kontroller for oppgavespesifikke embeddinger (f.eks. task:search, task:code).
Hva er Gemini Embedding 2?
Gemini Embedding 2 er en samlet embedding-modell fra Google som kartlegger flere inndatamodaliteter — tekst, bilder, lyd, video og dokumenter — til ett enkelt semantisk vektorrom. Hver embedding er (som standard) en 3,072-dimensjonal flyttallsvektor som representerer den semantiske betydningen av input slik at semantisk like elementer (uavhengig av modalitet) er nær hverandre i vektorrommet. De viktigste egenskapene er:
- Bred språk- og formatdekning: én enkelt modell som aksepterer tekst, bilder, lyd, video og dokumenter og plasserer dem i ett semantisk vektorrom. Gemini Embedding 2 er dokumentert å fange semantisk hensikt på tvers av 100+ språk og å akseptere vanlige filformater (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), med konkrete grenser per forespørsel (f.eks. opptil noen få bilder eller titalls sekunder med lyd/video per forespørsel — se «Slik bruker du» nedenfor).
- Ekte multimodalitet: én enkelt modell som aksepterer tekst, bilder, lyd, video og dokumenter og plasserer dem i ett semantisk vektorrom slik at du kan sammenligne eller hente på tvers av modaliteter (f.eks. tekst → bilde, lyd → tekst).
- Stor standarddimensionalitet med fleksibel trunkering: modellen genererer som standard 3072-dimensjonale vektorer, men bruker Matryoshka Representation Learning (MRL) til å konsentrere den viktigste semantiske informasjonen i de første dimensjonene, slik at du kan trunkere til 1536, 768 (eller lavere) med bare moderate fall i gjenfinningskvalitet. Dette reduserer avveininger mellom lagring og beregningskostnad.
Hvorfor dette er viktig. Historisk sett var embeddings stort sett bare tekst eller krevde separate encodere per modalitet med komplekse kryssmodale justeringslag. Gemini Embedding 2 fjerner denne barrieren ved å støtte flere formater nativt — slik at en tekstforespørsel kan hente et bilde eller et kort klipp etter semantisk likhet uten mellomliggende transkripsjon eller manuell mapping. Det forenkler RAG (retrieval-augmented generation), semantisk søk og multimodale gjenfinningspipeliner.
Nøkkelfunksjoner og kapabiliteter (hva er nytt)
1. Ekte nativ multimodalitet (ett embedding-rom)
Én enkelt modell som aksepterer tekst, bilder, lyd, video og dokumenter og plasserer dem i ett semantisk vektorrom. Gemini Embedding 2 kartlegger tekst, bilder, lyd, video og dokumenter inn i det samme embedding-rommet, slik at kryssmodal gjenfinning (tekst→bilde, lyd→tekst) fungerer direkte uten kryssmodell-justering. Dette reduserer kompleksitet i pipeline og forenkler RAG-stakker (Retrieval-Augmented Generation).
2. 3,072-dimensjonale standardvektorer med justerbar utgang
Gemini Embedding 2 genererer 3072-dimensjonale vektorer som standard, men bruker Matryoshka Representation Learning (MRL) til å konsentrere den viktigste semantiske informasjonen i de første dimensjonene, slik at du kan trunkere til 1536, 768 (eller lavere) med bare moderate fall i gjenfinningskvalitet. Dette reduserer avveininger mellom lagring og beregningskostnad.
3. Matryoshka Representation Learning (MRL)
MRL produserer «nestede» embeddinger — som russiske nestingdukker — slik at lavere-dimensjonale utsnitt bevarer overordnet semantikk. Dette lar systemer velge et driftspunkt (avveining mellom lagring/nøyaktighet) uten å måtte opprettholde flere separate embedding-modeller. Tidlige blogg-analyser og dokumentasjon beskriver denne teknikken som en kjerneinnovasjon for fleksibilitet.
4. Oppgavehint / tilpassede embedding-mål
API-et aksepterer task-hint (f.eks. task:search, task:code retrieval, task:semantic-similarity) slik at modellen kan optimalisere embedding-geometrien for spesifikke nedstrømsrelasjoner — likt oppgavekondisjonering brukt i tidligere embedding-systemer, men utvidet til multimodale input.
5. Bredde i språk og modalitet
Gemini Embedding 2 er dokumentert å fange semantisk hensikt på tvers av 100+ språk og å akseptere vanlige filformater (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), med konkrete grenser per forespørsel (f.eks. opptil noen få bilder eller titalls sekunder med lyd/video per forespørsel — se «Slik bruker du» nedenfor).
Ytelsesbenchmark
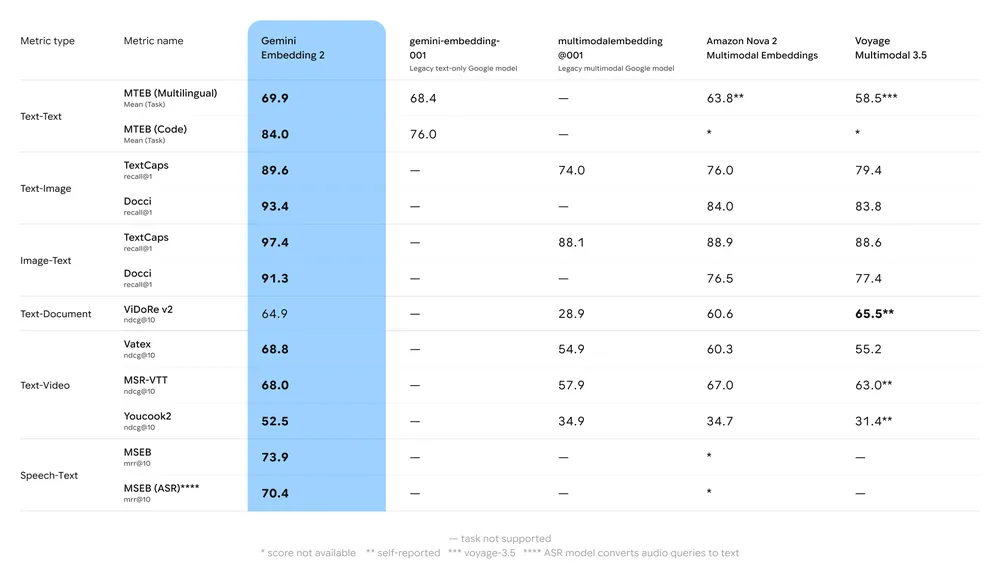
Nøkkelsammendrag av benchmark:
- MTEB (Massive Text Embedding Benchmark): Rapportert sterk plassering på flerspråklige MTEB-topplister for engelsk og flerspråklige oppgaver; analyser viser merkbar forbedring kontra Geminis tidligere embedding-modeller og mange proprietære alternativer.
- Multimodal gjenfinning: Overgår eller matcher ledende enkeltmodale embeddinger ved bruk til kryssmodal likhet (f.eks. tekst→bilde-gjenfinning), takket være nativ multimodal trening.
- Latens og gjennomstrømning: Skyhostet embedding-generering, men latenssensitiv bruk kan foretrekke trunkerte vektorer eller alternative lette embedding-modeller for behov ved kanten.
Gemini Embedding 2 kontra gemini-embedding-001 og text-embedding-3-large
| Egenskap | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Lansering / tilgjengelighet | 10. mars 2026 — offentlig forhåndsvisning (Gemini API / Vertex AI). | Tidligere Gemini-embedding (varianter kun tekst) — GA tidligere. | Annonsert jan. 2024 (kun tekst GA). |
| Støttede modaliteter | Tekst, bilder, lyd, video, dokumenter (PDF) — samlet vektorrom. | Tekst (primært). | Kun tekst (flerspråklig med høy kvalitet). |
| Standard embedding-dim. | 3072 (MRL / anbefalt trunkering: 1536, 768). | 3072 (for stor) — kun tekst. | 3072 (text-embedding-3-large). |
| Rapportert MTEB (eksempel) | Høy 60-tall på MTEB; viser 68.17 ved 1536 i leverandørtabell (se dokumentasjon). | gemini-embedding-001 rapporterte ~68.32 i snitt på noen topplister. | ~64.6 (MTEB-gjennomsnitt rapportert av OpenAI for text-embedding-3-large). |
| Nativ støtte for lyd/video | Ja (direkte lyd/video-embedding). | Nei (kun tekst). | Nei (kun tekst). |
| Typiske brukstilfeller | Multimodal gjenfinning, RAG, semantisk søk på tvers av filtyper, talegjenfinning, videosøk. | Tekstgjenfinning, flerspråklig RAG. | Tekstgjenfinning, semantisk søk, RAG — sterk flerspråklig tekstytelse. |
Tekniske spesifikasjoner og begrensninger
Standard og justerbar embedding-størrelse
- Standard: 3,072 dimensjoner.
- Justerbar:
output_dimensionality-parameteren lar deg be om lavere dimensjonsutganger for å spare lagring / CPU. Brukstilfeller med svært store vektorlager reduserer ofte dimensjoner til 512–1,024 av kostnadshensyn, men aksepterer noe nøyaktighetstap.
Støttede modaliteter og grenser per forespørsel
- Bilder: PNG, JPEG — opptil 6 bilder per forespørsel (leverandør-rapporterte grenser).
- Video: MP4, MOV — leverandøren rapporterer opptil ~128 sekunder per video for embedding i én forespørsel.
- Lyd: MP3, WAV — leverandøren rapporterer opptil ~80 sekunder per lydinput.
- Dokumenter: PDF-er — opptil 6 sider per forespørsel (leverandørrapportering).
- Token-grense for tekstinnhold: modellen støtter store token-input; praktiske token-tak per forespørsel finnes (sjekk API-dokumentasjon og Vertex AI-kvoter).
Tilgjengelighet og tilgang
- Offentlig forhåndsvisning: Gemini Embedding 2 ble lansert som en offentlig forhåndsvisning og er tilgjengelig gjennom Gemini API og Google Clouds Vertex AI for umiddelbar eksperimentell bruk
Ofte stilte spørsmål (FAQ)
Q1: Hvilke modaliteter støtter Gemini Embedding 2?
A: Tekst, bilder (PNG/JPEG), video (MP4/MOV), lyd (MP3/WAV) og PDF-dokumenter — alle kartlagt til det samme semantiske vektorrommet.
Q2: Hva er standard vektorstørrelse for Gemini Embedding 2?
A: Standard er 3,072 dimensjoner. Du kan be om mindre utgangsdimensjonalitet via API-et.
Q3: Er Gemini Embedding 2 tilgjengelig nå?
A: Ja — den ble annonsert som en offentlig forhåndsvisning og er tilgjengelig gjennom Gemini API og Vertex AI (sjekk modell-ID gemini-embedding-2-preview og gjeldende endringslogg).
Q4: Hvordan sammenlignes den med embeddinger fra andre leverandører?
A: Uavhengige leverandørtester rapporterer at Gemini Embedding 2 er blant de beste proprietære modellene for flerspråklig tekst og viser banebrytende ytelse for flere multimodale oppgaver. Eksakte rangeringer varierer per oppgave og datasett; test på dine egne data.
Q5: Må jeg transkribere lyd for å bruke Gemini Embedding 2?
A: Nei — Gemini Embedding 2 kan akseptere lyd direkte og produsere embeddinger uten først å transkribere til tekst, noe som muliggjør ende-til-ende semantisk gjenfinning for lyd.
Q6: Hvordan kan jeg redusere lagringskostnader for 3,072-dimensjonale vektorer?
A: Alternativer inkluderer å be om lavere output_dimensionality, bruke float16/kvantisering/PQ, og lagre komprimerte representasjoner i vektor-DB-en din. Leverandørinnlegg gir arbeidsflyter og beste praksis.
Hva skjer videre — bør jeg ta det i bruk nå?
Gemini Embedding 2 er et stort steg i å forene multimodal gjenfinning og forenkler arkitekturer som tidligere krevde separate retrievere for tekst, visjon og tale. De viktigste beslutningspunktene for å ta det i bruk:
- Ta i bruk snart hvis produktet ditt trenger robust kryssmodal gjenfinning (tekst↔bilde/video/lyd), eller hvis det er kostbart og komplekst å opprettholde flere enkeltmodalitets-retrievere.
- Pilotér nå hvis du vil evaluere MRL-trunkering og måle kostnad vs. kvalitet (behold en hybrid utrulling: 1536 som primær, 3072 for re-rangering).
- Vent hvis arbeidslasten din er ekstremt kostnadssensitiv og kun tekstgjenfinning er nødvendig — topp kun-tekst-modeller (f.eks. OpenAI text-embedding-3-large) er fortsatt konkurransedyktige og noen ganger billigere avhengig av pipeline og avtale.
Utviklere kan få tilgang til Gemini Embedding 2 og OpenAI text-embedding-3 API via CometAPI nå. For å begynne, utforsk modellens kapabiliteter i Playground og se API-veiledning for detaljerte instruksjoner. Før du får tilgang, sørg for at du har logget inn på CometAPI og hentet API-nøkkelen. CometAPI tilbyr en pris langt under den offisielle prisen for å hjelpe deg med integrering.
Klar til å starte?→ Sign up for cometapi today !
Hvis du vil ha flere tips, veiledninger og nyheter om AI, følg oss på VK, X og Discord!