
.webp&w=3840&q=75)
GLM-5.1 representerer et avgjørende skifte i AI-landskapet. Etter hvert som kinesiske AI-selskaper akselererer kommersialisering samtidig som de åpenkildegjør frontkapabiliteter, reduserer denne modellen gapet til proprietære ledere som OpenAI GPT-5.4, Anthropic Claude Opus 4.6 og Google Gemini 3.1 Pro—særlig i reelt programvareingeniørarbeid. Trent på den samme MoE-arkitekturen med 744 milliarder parametere som GLM-5, men kraftig optimalisert for agentiske arbeidsflyter, utmerker den seg der de fleste LLM-er snubler: lange, tvetydige, iterative oppgaver som krever planlegging, eksperimentering, feilsøking og selvkorreksjon over tusenvis av verktøykall.
Nå integrerer CometAPI GLM-5.1 og GLM-5, og utviklere kan også se andre ledende vestlige modeller og få tilgang til dem til en svært lav API-pris (som også er en fordel for CometAPI sammenlignet med andre konkurrenter).
Hva er GLM-5.1?
GLM-5.1 er Z.ai sin nyeste flaggskipspråkmodell og selskapets siste satsing på langsiktige, agent-stil programvareoppgaver. Med Z.ai sine egne ord er den designet for oppgaver som trenger kontinuerlig gjennomføring fremfor engangssvar, og den er posisjonert som en modell som kan planlegge, gjennomføre, forbedre og levere i én forlenget, sammenhengende kjøring. Ifølge Z.ai sine utgivelsesnotater er GLM-5.1 bygget med fleromgangers overvåket finjustering, forsterkningslæring og et rammeverk for evaluering av prosesskvalitet, og den forbedrer stabilitet, konsistens og verktøybruk i langvarige oppgaver.
Denne posisjoneringen er viktig fordi GLM-5.1 ikke selges som bare «enda en chat-modell». Den er rettet mot ingeniørarbeidsflyter der modeller må holde et mål i minnet, håndtere mellomsteg og hente seg inn fra feil uten å miste tråden; den presenteres som en modell for autonom planlegging, vedvarende gjennomføring, feilretting og strategiiterasjon—en helt annen produktfortelling enn en uformell assistent eller en kortkontekst kodekopilot.
En nyttig praktisk detalj: GLM-5.1 er kun tekstbasert, den støttes i GLM Coding Plan og kan brukes i populære kodeagenter som Claude Code og OpenClaw, noe som gjør den spesielt relevant for team som vil at en modell skal inngå i en eksisterende utviklerarbeidsflyt i stedet for å erstatte den.
Kjerne tekniske spesifikasjoner (arvet og finpusset fra GLM-5):
- Arkitektur: Mixture-of-Experts (MoE) med 744 milliarder totale parametere og omtrent 40 milliarder aktive parametere per inferens.
- Kontekstvindu: 203K–204.8K tokens (med støtte for opptil 131K utgangstokens).
- Viktige forbedringer: DeepSeek Sparse Attention (DSA) for effektiv håndtering av lang kontekst og reduserte driftskostnader; avansert asynkron forsterkningslæringsinfrastruktur (via Z.ai sitt «slime»-rammeverk) for mer effektiv ettertrening.
- Tilgjengelighet: Åpne vekter (MIT-lisens på Hugging Face via zai-org/GLM-5.1), API-tilgang gjennom Z.ai sin plattform og aggregatorer som CometAPI, og integrert i GLM Coding Plan-verktøy (kompatibel med Claude Code / OpenClaw).
I motsetning til tidligere GLM-modeller som fokuserte på generell intelligens eller kort «vibe coding», retter GLM-5.1 seg mot produksjonsklare autonome agenter. Den kan selvstendig planlegge, gjennomføre, benchmarke, feilsøke og iterere på komplekse ingeniørprosjekter i timevis uten menneskelig inngripen—kapabiliteter som posisjonerer den som en direkte konkurrent til spesialiserte kodeagenter fra Anthropic og OpenAI.
Lanseringen falt sammen med en ~10 % økning i API-prisen (inndatatokens ~$0.54/M, utdata ~$4.40/M), men den er fortsatt dramatisk billigere enn tilsvarende som Anthropic Opus 4.6 (250–470 % dyrere).
GLM-5.1 benchmark-ytelse
Z.ai posisjonerer GLM-5.1 som verdens sterkeste åpen kildekode-modell og en global topp-3-utøver innen agentisk koding. Ytelsesdata kommer fra offisielle evalueringer på SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 og egendefinerte langhorisont-scenarier.
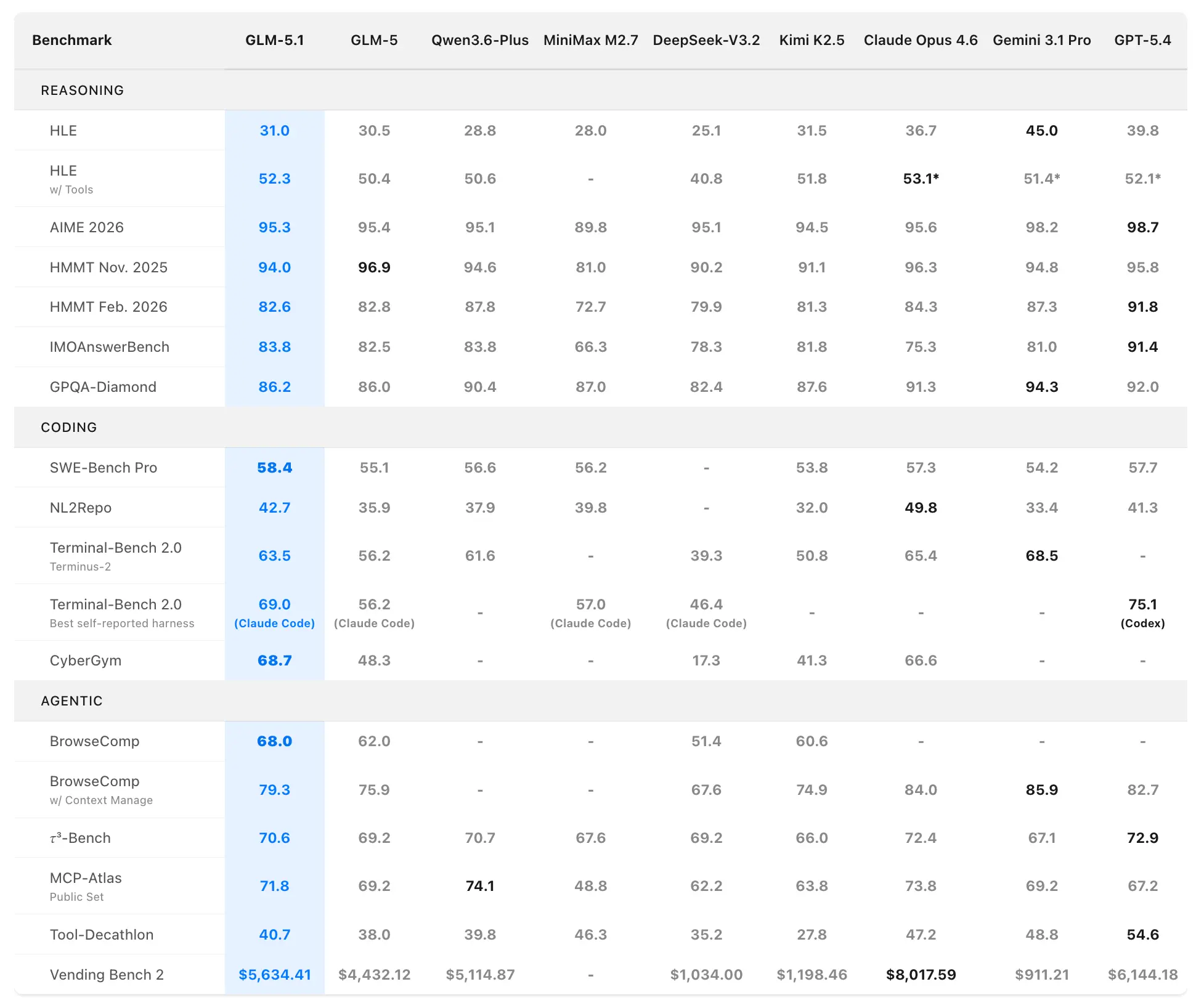
Kode- og agentiske benchmarks
SWE-Bench Pro (realistiske programvareingeniøroppgaver som krever navigasjon i repositories, kodeendringer og funksjonell verifisering):
- GLM-5.1: 58.4 (ny state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 er den første innenlandske (kinesiske) og åpen kildekode-modellen som tar topplasseringen på denne strenge benchmarken, som tett speiler profesjonelle utviklerarbeidsflyter.
NL2Repo (naturlig språk til fullstendig repository-generering):
- GLM-5.1: 42.7 (klar ledelse over GLM-5 sin 35.9)
- Konkurrerende modeller ligger på 32.0–49.8 (spesifikke ledere varierer etter harness).
Terminal-Bench 2.0 (reelle terminal- og systemoppgaver):
- Terminus-2-harness: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Beste egenrapporterte (Claude Code): Opptil 69.0.
I en separat vurdering med coding harness (Claude Code-stil) scoret GLM-5.1 45.3—nådd 94.6 % av Claude Opus 4.6 sin 47.9 og en 28 % forbedring over GLM-5 sin 35.4.
Sammensatt rangering: #1 åpen kildekode, #1 kinesisk modell, #3 globalt på tvers av SWE-Bench Pro + NL2Repo + Terminal-Bench.
Ytelse på langhorisont-oppgaver: Den virkelige differensiatoren
Standardbenchmarker måler én-gangs- eller kortøktytelse. GLM-5.1 briljerer i utvidede, autonome kjøringer:
- VectorDBBench-optimalisering (600+ iterasjoner, 6,000+ verktøykall): Med utgangspunkt i et Rust-skjelett redesignet GLM-5.1 iterativt indeksering, komprimering, ruting og pruning, og oppnådde 21.5k QPS (6× tidligere 50-omgangs beste på 3,547 QPS av Claude Opus 4.6) samtidig som den opprettholdt ≥95% recall på SIFT-1M. Den viste «trappevis» fremgang med strukturelle gjennombrudd hver 100–200 iterasjoner.
- KernelBench Level 3 (full ML-modelloptimalisering, 1,000+ omganger): Geometrisk gjennomsnittlig hastighetsøkning på 3.6× over 50 komplekse problemer (bedre enn torch.compile max-autotune sin 1.49×). GLM-5.1 fortsatte å forbedre seg lenge etter at GLM-5 flatet ut; bare Claude Opus 4.6 var så vidt foran med 4.2×.
- Linux Desktop Web App Build (8+ timer, åpen slutt): Gitt bare en naturlig språkprompt og ingen startkode bygde GLM-5.1 autonomt et funksjonelt Linux-lignende skrivebordsmiljø—komplett med oppgavelinje, vinduer, interaksjoner og finpuss—der tidligere modeller kun produserte enkle skjeletter.
Disse resultatene demonstrerer GLM-5.1 sin evne til å opprettholde sammenheng, selvevaluere, revidere strategier og komme seg ut av lokale optima over svært lange horisonter—kapabiliteter Z.ai eksplisitt har konstruert for virkelige agentsystemer.
Hvordan skiller GLM-5.1 seg fra GLM-5?
GLM-5 og GLM-5.1 er nært beslektet, men de er ikke posisjonert likt. GLM-5 er Z.AI sin tidligere grunnlagsmodell for Agentic Engineering. Den er designet for kompleks systemengineering og langtrekkende agentoppgaver, med SOTA-koding med åpne vekter og agentkapabilitet, og kodeytelse som nærmer seg Claude Opus 4.5 i reelle programmeringsscenarier. Den scorer 77.8 på SWE-bench Verified og 56.2 på Terminal Bench 2.0.
GLM-5.1, derimot, fremstilles som neste steg mot langhorisont-oppgaver og mer pålitelig vedvarende gjennomføring; den forbedrer stabilitet, konsistens og verktøybruk over utstrakte oppgaver, og er mer på linje med Claude Opus 4.6 totalt sett. Med andre ord: GLM-5 er den tidligere ingeniørsentrerte grunnlagsmodellen, mens GLM-5.1 er det mer utholdenhetsorienterte flaggskipet.
Det finnes også arkitektur- og treningsforskjeller i GLM-5-generasjonen som forklarer hoppet. GLM-5 utvidet fra 355B parametere (32B aktivert) til 744B parametere (40B aktivert), økte pretreningsdata fra 23T til 28.5T, la til et asynkront forsterkningslæringsrammeverk og integrerte DeepSeek Sparse Attention for å bevare kvaliteten på lang tekst samtidig som effektiviteten forbedres. Disse detaljene er knyttet til GLM-5, men de utgjør basen som GLM-5.1 ser ut til å bygge videre på.
GLM-5.1 vs andre grenselandsmodeller
GLM-5.1 skiller seg ut som den sterkeste åpen kildekode-kandidaten samtidig som den tilbyr overbevisende pris/ytelse.
Sammenligningstabell: Viktige kode- og agentiske benchmarks (april 2026)
| Modell | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding harness-score | Vedvarende over lang horisont? | Åpen kildekode? | Ca. API-pris (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% av Opus) | Ja (600+ iterasjoner, 8 timer) | Ja | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Begrenset | Ja | Lavere (før prisøkning) |
| GPT-5.4 | 57.7 | — | — | — | Sterk | Nei | Høyere |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Sterkest | Nei | ~250–470% dyrere |
| Gemini 3.1 Pro | 54.2 | — | — | — | God | Nei | Høyere |
Konklusjon: GLM-5.1 vinner på åpen-kilde-tilgjengelighet, kostnad og spesifikke langhorisont-kodemålinger. Den bytter slag med lukkede ledere i agentiske scenarier samtidig som den demokratiserer fronter-kapabiliteter.
Bruksområder for GLM-5.1
1) Autonom programvareutvikling
GLM-5.1 er mest overbevisende når oppgaven ligner en virkelig utviklingssprint: lese kodebasen, planlegge endringen, implementere den, teste, rette regresjoner og fortsette å iterere til resultatet er stabilt. Z.ai sine utgivelsesnotater fremhever eksplisitt autonom planlegging, vedvarende gjennomføring, feilretting og strategiiterasjon, noe som får denne modellen til å føles skreddersydd for kodeagenter og leveranselinjer for programvare.
2) Langvarige agent-arbeidsflyter
Hvis bruksområdet ditt innebærer mange verktøykall, lange flertrinns arbeidsflyter eller gjentatt selvkorreksjon, er GLM-5.1 sitt design en sterk match. Dokumentasjonen fremhever verktøykall, strukturert utdata, MCP-integrasjon og verktøy-strømming, som alle er nyttige når en modell ikke bare svarer, men opererer inni et større system.
3) Kunnskapsarbeid og rapportering i virksomheter
GLM-5.1 er også posisjonert for kontorproduktivitet som PowerPoint-, Word-, PDF- og Excel-arbeidsflyter. Z.ai sier den forbedrer kompleks innholdsorganisering, layoutdesign, strukturert utdata og visuell finish, noe som gjør den plausibel for rapportgenerering, undervisningsmateriell, forskningsoppsummeringer og annet dokumenttungt arbeid.
4) Frontend-prototyper og artefakter
Z.ai sier GLM-5.1 egner seg godt til nettsidegenerering, interaktive sider og frontend-prototyping, med mindre malpreget struktur og bedre oppgavefullføring. Det antyder en god match for produktteam som trenger en rask bro fra brief til prototype—spesielt når prototypen må være brukbar, ikke bare pen.
5) Kompleks samtale og instruksjonsfølging
Selv om overskriften er koding, beskrives GLM-5.1 også som sterkere i åpne spørsmål og svar, komplekse instruksjoner og fleromgangsinteraksjon. Det gjør den nyttig for assistentlignende arbeidsflyter der modellen må holde styr på begrensninger, revidere utdata og bevare kontekst på tvers av lengre samtaler.
Konklusjon: Hvorfor GLM-5.1 betyr noe i 2026
GLM-5.1 er ikke bare en inkrementell utgivelse—den signaliserer ankomsten av virkelig kapabel, åpen kildekode agentisk AI. Ved å briljere på de vanskeligste ingeniørbenchmarkene i den virkelige verden, samtidig som den forblir rimelig og åpen, har Z.ai hevet lista for hele bransjen. Enten du er solo-utvikler, virksomhetsteam eller forsker, tilbyr GLM-5.1 enestående autonomi for langhorisont-kodeoppgaver til en brøkdel av kostnaden til proprietære alternativer.
Klar til å prøve? Sjekk CometAPI GLM-5.1-modellen, Hugging Face-repoet eller GLM Coding Plan for umiddelbar tilgang.