

GPT-5.2 er OpenAIs punktutgivelse for desember 2025 i GPT-5-familien: en flaggskip-flermodal modellfamilie (tekst + visjon + verktøy) finjustert for profesjonelt kunnskapsarbeid, langkontekstresonnering, agentisk verktøybruk og programvareutvikling. OpenAI posisjonerer GPT-5.2 som den mest kapable modellen i GPT-5-serien til dags dato og sier at den er utviklet med vekt på pålitelig flertrinnsresonnering, håndtering av svært store dokumenter, og forbedret sikkerhet/policy-etterlevelse; utgivelsen inkluderer tre varianter for sluttbrukere — Instant, Thinking og Pro — og rulles først ut til betalende ChatGPT-abonnenter og API-kunder.
Hva er GPT-5.2, og hvorfor er det viktig?
GPT-5.2 er det nyeste medlemmet i OpenAIs GPT-5-familie — en ny “frontier”-modellserie designet spesifikt for å lukke gapet mellom enkelttur-samtaleassistenter og systemer som må resonnere på tvers av lange dokumenter, kalle verktøy, tolke bilder og utføre flertrinns arbeidsflyter pålitelig. OpenAI posisjonerer 5.2 som deres mest kapable utgivelse hittil for profesjonelt kunnskapsarbeid: den setter nye state-of-the-art-resultater på interne benchmarker (særlig en ny GDPval-benchmark for kunnskapsarbeid), demonstrerer sterkere kodeytelse på programvareingeniør-benchmarker, og tilbyr betydelig forbedret langkontekst- og visjonskapabilitet.
I praktiske termer er GPT-5.2 mer enn bare “en større chatmodell.” Det er en familie av tre finjusterte varianter (Instant, Thinking, Pro) som avveier latens, dybden i resonnement og kostnad — og som, sammen med OpenAIs API og ChatGPT-ruting, kan brukes til å kjøre lange forskningsjobber, bygge agenter som kaller eksterne verktøy, tolke komplekse bilder og diagrammer, og generere kode av produksjonskvalitet med høyere presisjon enn tidligere utgivelser. Modellen støtter svært store kontekstvinduer (OpenAI-dokumenter oppgir et kontekstvindu på 400,000 token og en 128,000 maks-utgangsgrense for flaggskipmodellene), nye API-funksjoner for eksplisitte nivåer av resonnementsinnsats, og “agentisk” verktøykallingsatferd.
5 kjernekapabiliteter oppgradert i GPT-5.2
1) Er GPT-5.2 bedre på flertrinnslogikk og matematikk?
GPT-5.2 gir skarpere flertrinnsresonnering og merkbart sterkere ytelse på matematikk og strukturert problemløsning. OpenAI sier de har lagt til mer granulær kontroll over resonnementsinnsats (nye nivåer som xhigh), utviklet støtte for “reasoning token”, og finjustert modellen til å opprettholde chain-of-thought over lengre interne resonnementspor. Benchmarker som FrontierMath og ARC-AGI-stiltester viser betydelige gevinster sammenlignet med GPT-5.1; større marginer på domenespesifikke benchmarker brukt i vitenskapelige og finansielle arbeidsflyter. Kort sagt: GPT-5.2 “tenker lenger” når den blir bedt om det, og kan gjøre mer komplisert symbolsk/matematisk arbeid med bedre konsistens.

| RC-AGI-1 (Verified) Abstrakt resonnering | 86.2% | 72.8% |
|---|---|---|
| ARC-AGI-2 (Verified) Abstrakt resonnering | 52.9% | 17.6% |
GPT-5.2 Thinking setter rekorder i flere avanserte vitenskaps- og matematikkresonneringstester:
- GPQA Diamond Science Quiz: 92.4% (Pro-versjonen 93.2%)
- ARC-AGI-1 Abstract Reasoning: 86.2% (første modell som bryter 90%-terskelen)
- ARC-AGI-2 Higher Order Reasoning: 52.9%, og setter ny rekord for Thinking Chain-modellen
- FrontierMath Advanced Mathematics Test: 40.3%, langt over forgjengeren;
- HMMT Math Competition Problems: 99.4%
- AIME Math Test: 100% Fullstendig løsning
Videre er GPT-5.2 Pro (High) state-of-the-art på ARC-AGI-2, med en score på 54.2% til en kostnad på $15.72 per oppgave! Overgår alle andre modeller.
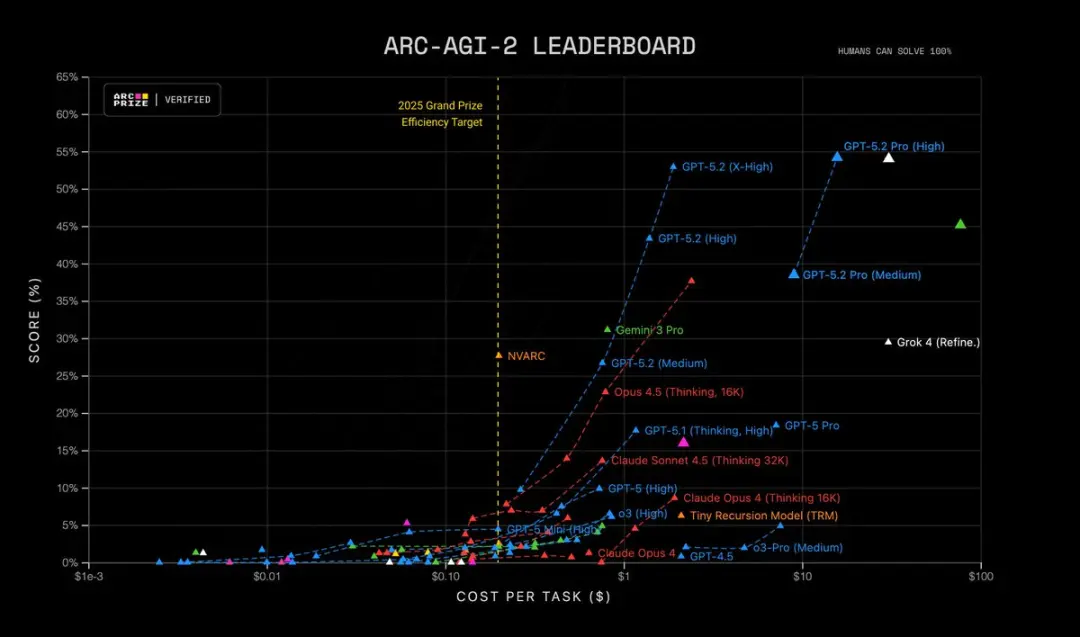
Hvorfor dette betyr noe: mange reelle oppgaver — finansiell modellering, forsøksdesign, programsyntese som krever formell resonnement — er flaskehalsstyrt av en modells evne til å kjede mange riktige steg. GPT-5.2 reduserer “hallusinerte steg” og produserer mer stabile mellomliggende resonnementspor når du ber den vise arbeidet sitt.
2) Hvordan er langtekstforståelse og kryssdokument-resonnering forbedret?
Langkontekstforståelse er en av de mest fremtredende forbedringene. GPT-5.2s underliggende modell støtter et kontekstvindu på 400k token og — viktig — opprettholder høyere nøyaktighet når relevant innhold flyttes dypt inn i den konteksten. GDPval, en oppgavepakke for “godt spesifisert kunnskapsarbeid” på tvers av 44 yrker, der GPT-5.2 Thinking oppnår paritet eller bedre enn menneskelige ekspert-dommere på en stor andel av oppgavene. Uavhengig rapportering bekrefter at modellen holder og syntetiserer informasjon på tvers av mange dokumenter langt bedre enn tidligere modeller. Dette er et genuint praktisk skritt fremover for oppgaver som due diligence, juridisk oppsummering, litteraturgjennomgang og forståelse av kodebaser.
GPT-5.2 kan håndtere kontekster opp til 256,000 token (omtrent 200+ sider med dokumenter). Videre oppnådde GPT-5.2 Thinking en nøyaktighetsrate nær 100% i “OpenAI MRCRv2”-testen for langtekstforståelse.
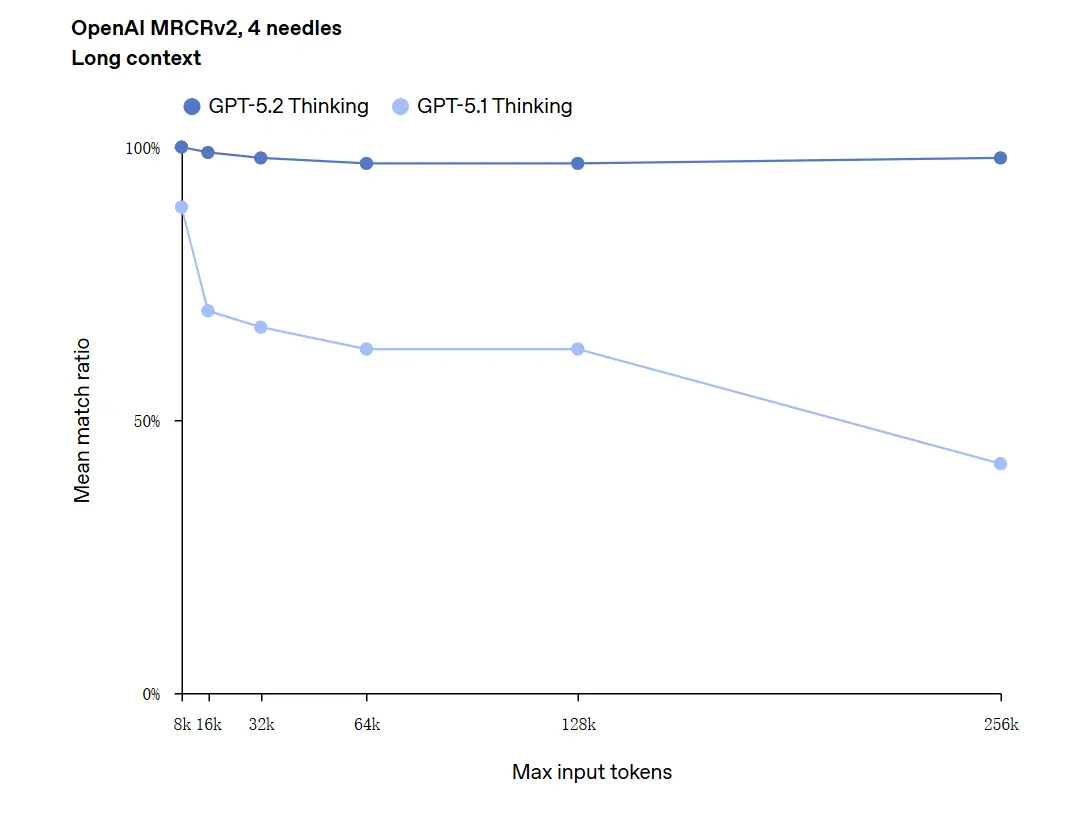
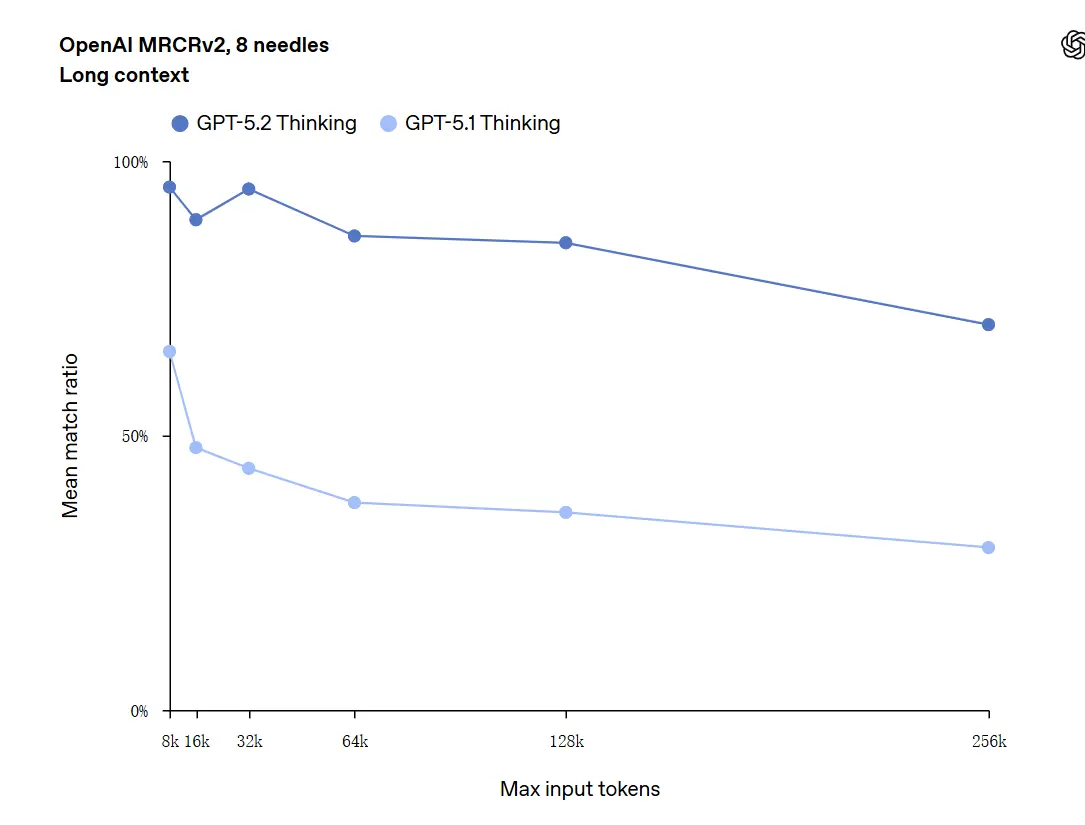
Forbehold om “100% nøyaktighet”: Det beskrev forbedringene som “nærmer seg 100%” for smale mikrooppgaver; OpenAIs data beskrives bedre som “state-of-the-art og i mange tilfeller på eller over menneskelige ekspertnivåer på evaluerte oppgaver,” ikke bokstavelig talt feilfri på tvers av alle bruksområder. Benchmarker viser store gevinster men ikke universell perfeksjon.
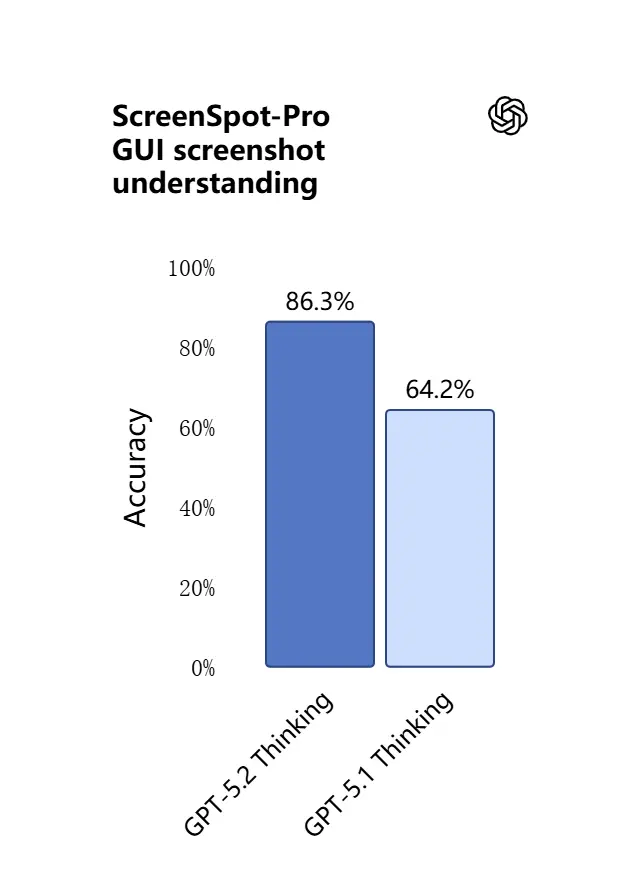
3) Hva er nytt i visuell forståelse og multimodal resonnering?
Visjonskapabiliteter i GPT-5.2 er skarpere og mer praktiske. Modellen er bedre på å tolke skjermbilder, lese diagrammer og tabeller, gjenkjenne UI-elementer, og kombinere visuelle input med lang tekstlig kontekst. Dette er ikke bare bildeteksting: GPT-5.2 kan hente ut strukturert data fra bilder (f.eks. tabeller i en PDF), forklare grafer, og resonnere om diagrammer på måter som støtter nedstrøms verktøyhandlinger (f.eks. generere et regneark fra en fotografert rapport).
.webp)
Praktisk effekt: team kan gi hele lysbildepakker, skannede forskningsrapporter eller bilde-tunge dokumenter direkte til modellen og be om kryssdokument-synteser — noe som kraftig reduserer manuelt ekstraheringsarbeid.
4) Hvordan har verktøykalling og oppgaveutførelse endret seg?
GPT-5.2 går lenger inn i agentisk atferd: den er bedre til å planlegge flertrinnsoppgaver, avgjøre når den skal kalle eksterne verktøy, og utføre sekvenser av API-/verktøykall for å fullføre en jobb ende-til-ende. Forbedringer i “agentisk verktøykalling” — modellen vil foreslå en plan, kalle verktøy (databaser, compute, filsystemer, nettleser, koderunnere), og syntetisere resultater til en endelig leveranse mer pålitelig enn tidligere modeller. API-et introduserer routing og sikkerhetskontroller (lister over tillatte verktøy, verktøyscaffolding) og ChatGPT-grensesnittet kan autorutere forespørsler til riktig 5.2-variant (Instant vs Thinking).
GPT-5.2 scoret 98.7% i Tau2-Bench Telecom-benchmarket, og demonstrerer modne verktøykallingsevner i komplekse flertur-oppgaver.
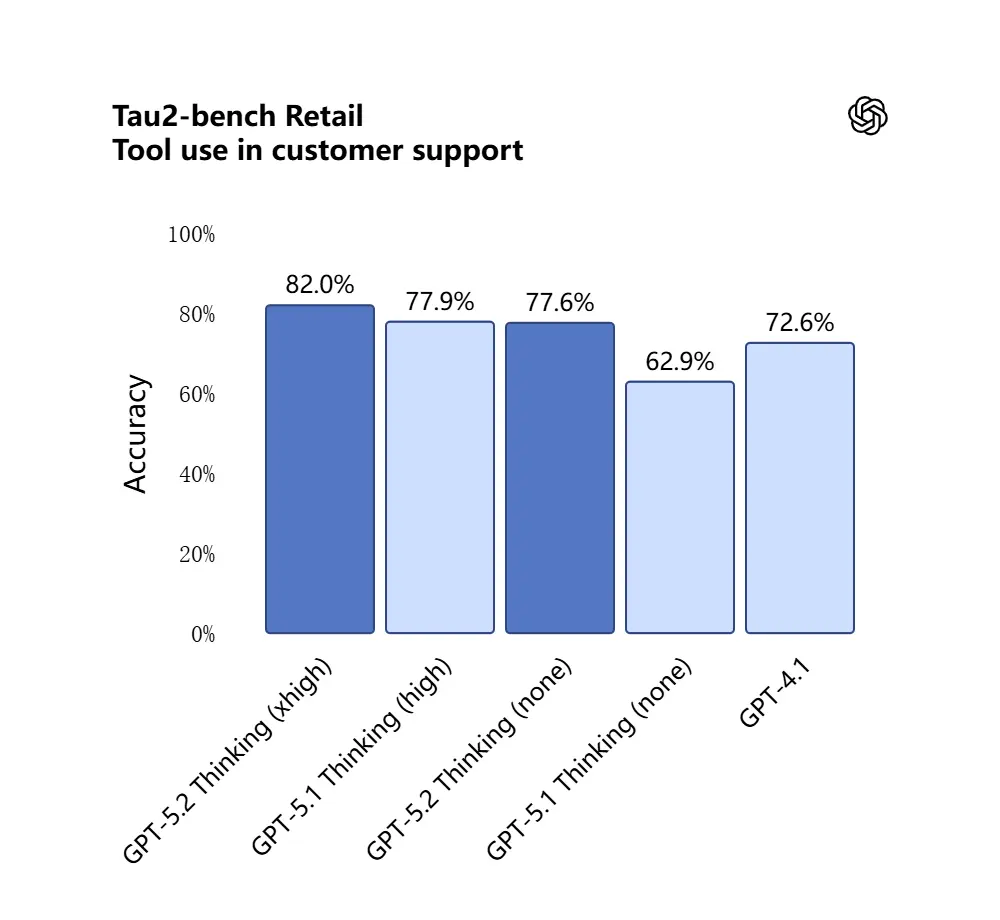
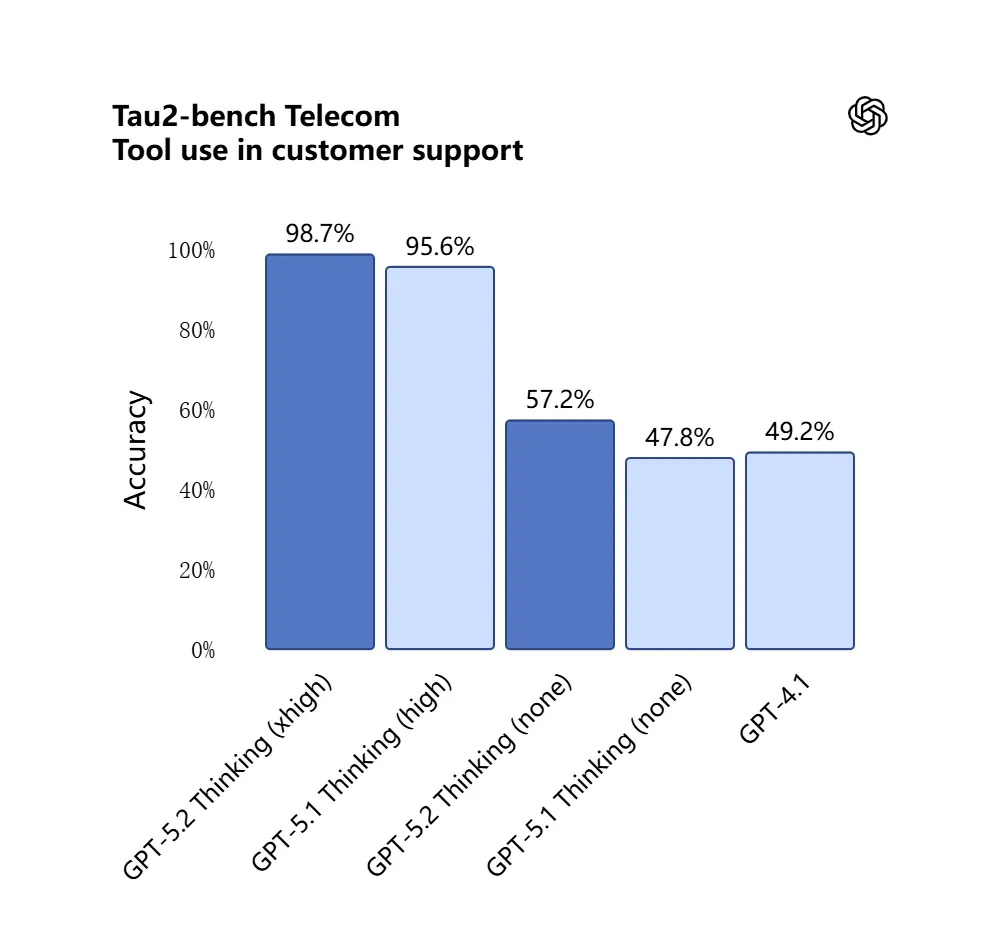
Hvorfor det er viktig: dette gjør GPT-5.2 mer nyttig som en autonom assistent for arbeidsflyter som “inngest disse kontraktene, ekstraher klausuler, oppdater et regneark, og skriv en sammendrags-e-post” — oppgaver som tidligere trengte nøye orkestrering.
5) Programmeringskapabilitet utviklet seg
GPT-5.2 er markant bedre på programvareingeniøroppgaver: den skriver mer komplette moduler, genererer og kjører tester mer pålitelig, forstår komplekse prosjekt-avhengighetsgrafer, og er mindre utsatt for “lat koding” (hopper over boilerplate eller feiler med å koble moduler sammen). På bransjegraderte kodebenchmarker (SWE-bench Pro, etc.) setter GPT-5.2 nye rekorder. For team som bruker LLM-er som par-programmerere kan denne forbedringen redusere manuell verifisering og etterarbeid etter generering.
I SWE-Bench Pro-testen (reelle industrielle programvareingeniøroppgaver) forbedret GPT-5.2 Thinking sin score til 55.6%, samtidig som den oppnådde en ny topp på 80% i SWE-Bench Verified-testen.
_Software%20engineering.webp)
I praktiske anvendelser betyr dette:
- Automatisk debugging av kode i produksjonsmiljø gir større stabilitet;
- Støtte for flerspråklig programmering (ikke begrenset til Python);
- Evne til selvstendig å fullføre end-til-end reparasjonsoppgaver.
Hva er forskjellene mellom GPT-5.2 og GPT-5.1?
Kort svar: GPT-5.2 er en iterativ men materiell forbedring. Den beholder GPT-5-familiens arkitektur og flermodale fundamenter, men forbedrer fire praktiske dimensjoner:
- Dybde og konsistens i resonnement. 5.2 introduserer høyere nivåer for resonnementsinnsats og bedre kjeding for flertrinnsproblemer; 5.1 forbedret resonnement tidligere, men 5.2 løfter taket for kompleks matematikk og flerstegslogikk.
- Langkontekst-pålitelighet. Begge versjoner utvidet konteksten, men 5.2 er finjustert for å opprettholde nøyaktighet dypt inn i svært lange input (OpenAI hevder forbedret retensjon opp til hundretusener av token).
- Visjon + multimodal fidelitet. 5.2 forbedrer kryssreferering mellom bilder og tekst — f.eks. lese en graf og integrere dataene i et regneark — og viser høyere oppgavenivå-nøyaktighet.
- Agentisk verktøyatferd og API-funksjoner. 5.2 eksponerer nye parametere for resonnementsinnsats (
xhigh) og kontekstkomprimeringsfunksjoner i API-et, og OpenAI har raffinert routing-logikken i ChatGPT slik at UI-en kan velge beste variant automatisk. - Færre feil, større stabilitet: GPT-5.2 reduserer sin "illusjonsrate" (feilresponsrate) med 38%. Den besvarer forsknings-, skrive- og analytiske spørsmål mer pålitelig, og reduserer tilfeller av "oppdiktede fakta." I komplekse oppgaver er dens strukturerte output tydeligere og logikken mer stabil. Samtidig er modellens responssikkerhet betydelig forbedret i oppgaver relatert til mental helse. Den presterer mer robust i sensitive scenarier som mental helse, selvskading, selvmord og emosjonell avhengighet.
I systemevalueringer scoret GPT-5.2 Instant 0.995 (av 1.0) på oppgaven "Mental Health Support", betydelig høyere enn GPT-5.1 (0.883).
Kvantitativt viser OpenAIs publiserte benchmarker målbare gevinster på GDPval, matematikk-benchmarker (FrontierMath), og programvareingeniør-evalueringer. GPT-5.2 overgår GPT-5.1 i oppgaver for junior investeringsbank-regneark med flere prosentpoeng.
Er GPT-5.2 gratis — hvor mye koster det?
Kan jeg bruke GPT-5.2 gratis?
OpenAI rullet ut GPT-5.2 med start i betalte ChatGPT-planer og API-tilgang. Historisk har OpenAI holdt de raskeste / dypeste modellene bak betalte nivåer mens de gjør lettere varianter tilgjengelige bredere senere; med 5.2 sa selskapet at utrullingen ville starte på betalte planer (Plus, Pro, Business, Enterprise) og at API-et er tilgjengelig for utviklere. Det betyr at umiddelbar gratis tilgang er begrenset: gratisnivået kan få degradert eller rutet tilgang (for eksempel til lettere under-varianter) senere etter hvert som OpenAI skalerer utrullingen.
Den gode nyheten er at CometAPI nå integrerer med GPT-5.2, og det er for tiden på julesalg. Du kan nå bruke GPT-5.2 gjennom CometAPI; playground-en lar deg fritt interagere med GPT-5.2, og utviklere kan bruke GPT-5.2-API-et (CometAPI er priset til 20% av OpenAIs) for å bygge arbeidsflyter.
Hva koster det via API-et (utvikler / produksjonsbruk)?
API-bruk faktureres per token. OpenAIs publiserte plattformpriser ved lansering viser (CometAPI er priset til 20% av OpenAIs):
- GPT-5.2 (standard chat) — $1.75 per 1M inn-tokener og $14 per 1M ut-tokener (rabatter for cachet input gjelder).
- GPT-5.2 Pro (flaggskip) — $21 per 1M inn-tokener og $168 per 1M ut-tokener (betydelig dyrere fordi den er ment for høy-nøyaktighet, beregningstunge arbeidslaster).
- Til sammenligning var GPT-5.1 billigere (f.eks. $1.25 inn / $10 ut per 1M token).
Tolkning: API-kostnader steg relativt til tidligere generasjoner; prissignalet indikerer at 5.2s premium-resonnering og langkontekst-ytelse prises som et eget produktsjikt. For produksjonssystemer avhenger plan-kostnader sterkt av hvor mange token du mater inn/ut og hvor ofte du gjenbruker cachet input (cachet input får store rabatter).
Hva det betyr i praksis
- For uformell bruk gjennom ChatGPTs UI er månedlige abonnementsplaner (Plus, Pro, Business, Enterprise) hovedveien. Prisingen for ChatGPT-abonnementsnivåer endret seg ikke med 5.2-utgivelsen (OpenAI holder planprisene stabile selv om modelltilbudene endres).
- For produksjon og utviklere: budsjetter for token-kostnader. Hvis appen din strømmer mange lange svar eller prosesserer lange dokumenter, vil kostnader for ut-tokener ($14 / 1M token for Thinking) dominere kostnadene med mindre du nøye cacher input og gjenbruker output.
GPT-5.2 Instant vs GPT-5.2 Thinking vs GPT-5.2 Pro
OpenAI lanserte GPT-5.2 med tre formålstilpassede varianter for å matche brukstilfeller: Instant, Thinking og Pro:
- GPT-5.2 Instant: Rask, kostnadseffektiv, finjustert for hverdagsarbeid — FAQ, hvordan-gjør-man, oversettelser, rask utkastskriving. Lavere latens; gode førsteutkast og enkle arbeidsflyter.
- GPT-5.2 Thinking: Dypere, høyere kvalitet på svar for vedvarende arbeid — langdokument-oppsummering, flertrinnsplanlegging, detaljerte kodegjennomganger. Balansert latens og kvalitet; standard “arbeidshest” for profesjonelle oppgaver.
- GPT-5.2 Pro: Høyeste kvalitet og pålitelighet. Tregere og dyrere; best for vanskelige, høyrisikooppgaver (kompleks ingeniørarbeid, juridisk syntese, beslutninger med høy verdi) og der en ‘xhigh’ resonnementsinnsats kreves.
Sammenligningstabell
| Funksjon / metrikk | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|
| Tilsiktet bruk | Hverdagsoppgaver, raske utkast | Dyp analyse, lange dokumenter | Høyeste kvalitet, komplekse problemer |
| Latens | Lavest | Moderat | Høyest |
| Resonnementsinnsats | Standard | Høy | xHigh tilgjengelig |
| Best for | FAQ, veiledninger, oversettelser, korte prompt | Oppsummeringer, planlegging, regneark, kodeoppgaver | Kompleks ingeniørarbeid, juridisk syntese, forskning |
| API-navneeksempler | gpt-5.2-chat-latest | gpt-5.2 | gpt-5.2-pro |
| Pris inn-tokener (API) | $1.75 / 1M | $1.75 / 1M | $21 / 1M |
| Pris ut-tokener (API) | $14 / 1M | $14 / 1M | $168 / 1M |
| Tilgjengelighet (ChatGPT) | Rulles ut; betalte planer deretter bredere | Rulles ut til betalte planer | Pro-brukere / Enterprise (betalt) |
| Typisk brukseksempel | Utkast til e-post, mindre kodebiter | Bygge finansmodeller med flere ark, Q&A for lange rapporter | Revidere kodebase, generere systemdesign av produksjonskvalitet |
Hvem passer GPT-5.2 for?
GPT-5.2 er designet med et bredt sett av målbrukere i tankene. Nedenfor er rollebaserte anbefalinger:
Bedrifter og produktteam
Hvis du bygger produkter for kunnskapsarbeid (forskningsassistenter, kontraktsgjennomgang, analysepipelines eller utviklerverktøy), kan GPT-5.2s langkontekst- og agentiske kapabiliteter betydelig redusere integrasjonskompleksitet. Bedrifter som trenger robust dokumentforståelse, automatisert rapportering eller intelligente copiloter vil finne Thinking/Pro nyttige. Microsoft og andre plattformpartnere integrerer allerede 5.2 i produktivitetsstakker (f.eks. Microsoft 365 Copilot).
Utviklere og ingeniørteam
Team som vil bruke LLM-er som par-programmerere eller automatisere kodegenerering/testing vil dra nytte av forbedret programmeringspresisjon i 5.2. API-tilgang (med thinking- eller pro-modus) muliggjør dypere synteser av store kodebaser takket være kontekstvinduet på 400k token. Forvent å betale mer på API-et når du bruker Pro, men reduksjonen i manuell debugging og gjennomgang kan rettferdiggjøre kostnaden for komplekse systemer.
Forskere og data-tunge analytikere
Hvis du regelmessig syntetiserer litteratur, tolker lange tekniske rapporter, eller ønsker modellassistert forsøksdesign, vil GPT-5.2s langkontekst- og matematikkforbedringer akselerere arbeidsflyter. For reproduserbar forskning, kombiner modellen med nøye promptengineering og verifikasjonssteg.
Småbedrifter og power-brukere
ChatGPT Plus (og Pro for power-brukere) vil få rutet tilgang til 5.2-varianter; dette gjør avansert automatisering og høykvalitetsutdata tilgjengelig for mindre team uten å bygge en API-integrasjon. For ikke-tekniske brukere som trenger bedre dokumentoppsummering eller lysbildebygging leverer GPT-5.2 merkbar praktisk verdi.
Praktiske notater for utviklere og operatører
API-funksjoner å følge med på
reasoning.effort-nivåer (f.eks.medium,high,xhigh) lar deg fortelle modellen hvor mye compute den skal bruke på interne resonnement; bruk dette til å avveie latens mot nøyaktighet per forespørsel.- Kontekstkomprimering: API-et inkluderer verktøy for å komprimere og kompakte historikk slik at genuint relevant innhold bevares over lange kjeder. Dette er kritisk når du må holde effektiv tokenbruk håndterlig.
- Verktøyscaffolding og allowed-tools-kontroller: produksjonssystemer bør eksplisitt hviteliste hva modellen kan kalle og logge verktøykall for revisjon.
Tips for kostnadskontroll
- Cache ofte brukte dokumentembeddinger og bruk cachet input (som får kraftige rabatter) for gjentatte spørsmål mot samme korpus. OpenAIs plattformprising inkluderer betydelige rabatter for cachet input.
- Ruter eksplorative/lav-verdi-forspørsler til Instant og behold Thinking/Pro for batchjobber eller siste pass.
- Estimer tokenbruk (input + output) nøye når du prosjekterer API-kostnader, fordi lange utdata multipliserer kostnaden.
Konklusjon — bør du oppgradere til GPT-5.2?
Hvis arbeidet ditt avhenger av langdokument-resonnering, kryssdokument-syntese, multimodal tolkning (bilder + tekst), eller bygging av agenter som kaller verktøy, er GPT-5.2 en klar oppgradering: den øker praktisk nøyaktighet og reduserer manuelt integrasjonsarbeid. Hvis du primært driver høyt volum, lavlatens chatboter eller strengt budsjettbegrensede applikasjoner, kan Instant (eller tidligere modeller) fortsatt være et rimelig valg.
GPT-5.2 representerer et bevisst skifte fra “bedre chat” til “bedre profesjonell assistent”: mer compute, mer kapabilitet, og høyere kostnadssjikt — men også reelle produktivitetsgevinster for team som kan utnytte pålitelig langkontekst, forbedret matematikk/resonnering, bildeforståelse og agentisk verktøyutførelse.
For å begynne, utforsk GPT-5.2-modeller (GPT-5.2;GPT-5.2 pro, GPT-5.2 chat) sine kapabiliteter i Playground og konsulter API-veiledningen for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og hentet API-nøkkelen. CometAPI tilbyr en pris langt under den offisielle prisen for å hjelpe deg å integrere.
Klar til å starte?→ Gratis prøve av gpt-5.2-modeller !