

GPT-5-Codex er OpenAIs nye, ingeniørfokuserte variant av GPT-5, spesielt tilpasset agentisk programvareutvikling innenfor Codex-produktfamilien. Den er designet for å håndtere store, virkelige ingeniørarbeidsflyter: å lage komplette prosjekter fra bunnen av, legge til funksjoner og tester, feilsøke, refaktorere og utføre kodegjennomganger mens man samhandler med eksterne verktøy og testpakker. Denne utgivelsen representerer en målrettet produktforbedring snarere enn en helt ny grunnleggende modell: OpenAI har integrert GPT-5-Codex i Codex CLI, Codex IDE-utvidelsen, Codex Cloud, GitHub-arbeidsflyter og ChatGPT-mobilopplevelser. API-tilgjengelighet er planlagt, men ikke umiddelbart.
Hva er GPT-5-Codex – og hvorfor finnes den?
GPT-5-Codex er GPT-5 «spesialisert for koding». I stedet for å være en generell konversasjonsassistent, er den finjustert og trent med forsterkningslæring og ingeniørspesifikke datasett for bedre å støtte iterative, verktøyassisterte kodeoppgaver (tenk: kjør tester, iterer på feil, refaktorer moduler og følg PR-konvensjoner). OpenAI rammer den inn som etterfølgeren til tidligere Codex-arbeid, men bygd på GPT-5-ryggraden for å forbedre dybden i resonnementet om store kodebaser og for å utføre flertrinns ingeniøroppgaver mer pålitelig.
Motivasjonen er praktisk: utviklernes arbeidsflyter er i økende grad avhengige av agenter som kan gjøre mer enn forslag i ett enkelt kodeutdrag. Ved å tilpasse en modell spesifikt til løkken «generer → kjør tester → fiks → gjenta» og til organisasjonens PR-normer, tar OpenAI sikte på å lage en AI som føles som en lagkamerat snarere enn en kilde til engangsfullføringer. Dette skiftet fra «generer en funksjon» til «send en funksjon» er modellens unike verdi.
Hvordan er GPT-5-Codex utformet og trent?
Høynivåarkitektur
GPT-5-Codex er en variant av GPT-5-arkitekturen (den bredere GPT-5-avstamningen) snarere enn en helt ny arkitektur. Det betyr at den arver GPT-5s kjernetransformatorbaserte design, skaleringsegenskaper og forbedringer av resonnement, men legger til Codex-spesifikk trening og RL-basert finjustering rettet mot programvareutviklingsoppgaver. OpenAIs tillegg beskriver GPT-5-Codex som trent på komplekse, virkelige ingeniøroppgaver og vektlegger forsterkningslæring i miljøer der kode kjøres og valideres.
Hvordan ble den trent og optimalisert for kode?
GPT-5-Codex sitt treningsprogram legger vekt på ingeniøroppgaver i den virkelige verdenDen bruker finjustering i forsterkningslæringsstil på datasett og miljøer konstruert fra konkrete programvareutviklingsarbeidsflyter: refaktorering av flere filer, PR-differanser, kjøring av testpakker, feilsøkingsøkter og menneskelige gjennomgangssignaler. Treningsmålet er å maksimere korrektheten på tvers av koderedigeringer, bestå tester og produsere gjennomgangskommentarer som har høy presisjon og relevans. Dette fokuset er det som skiller Codex fra generell chat-orientert finjustering: tapsfunksjonene, evalueringsselene og belønningssignalene er justert til tekniske resultater (beståtte tester, korrigerte differanser, færre falske kommentarer).
Hvordan «agentisk» trening ser ut
- Utførelsesdrevet finjusteringModellen trenes i kontekster der generert kode kjøres, testes og evalueres. Tilbakemeldingsløkker kommer fra testresultater og menneskelige preferansesignaler, noe som oppmuntrer modellen til å iterere til en testpakke består.
- **Forsterkende læring fra menneskelig tilbakemelding (RLHF)**Ligner i ånden på tidligere RLHF-arbeid, men anvendt på flertrinns kodeoppgaver (opprette PR, kjøre tester, fikse feil), slik at modellen lærer tidsmessig kredittildeling over en sekvens av handlinger.
- Kontekst på repositoriumsskalaTrening og evaluering inkluderer store arkiver og refaktorering, som hjelper modellen med å lære resonnement på tvers av filer, navnekonvensjoner og påvirkninger på kodebasenivå. ()
Hvordan håndterer GPT-5-Codex verktøybruk og miljøinteraksjoner?
En viktig arkitektonisk funksjon er modellens forbedrede evne til å kalle og koordinere verktøy. Codex kombinerte historisk sett modellutganger med et lite runtime-/agentsystem som kan kjøre tester, åpne filer eller kalle søk. GPT-5-Codex utvider dette ved å lære når verktøy skal kalles og ved å bedre integrere testtilbakemeldinger i påfølgende kodegenerering – og dermed effektivt lukke sløyfen mellom syntese og verifisering. Dette oppnås ved å trene på baner der modellen både utsteder handlinger (som «kjør test X») og betinger senere generasjoner på testutganger og differanser.
Hva kan GPT-5-Codex egentlig gjøre – hva er funksjonene?
En av de definerende produktinnovasjonene er adaptiv tenkningsvarighetGPT-5-Codex justerer hvor mye skjult resonnement den utfører: trivielle forespørsler kjører raskt og billig, mens komplekse refaktoreringer eller langvarige oppgaver lar modellen «tenke» mye lenger. Samtidig bruker modellen langt færre tokens enn en generell GPT-5-instans for små, interaktive turer. Sparer 93.7 % av tokens (inkludert slutning og output) sammenlignet med GPT-5. Denne variable resonnementstrategien er ment å produsere raske svar når det er nødvendig og dyp, grundig utførelse når det er berettiget.
Kjerneevner
- Prosjektgenerering og oppstart: Lag komplette prosjektskjeletter med CI, tester og grunnleggende dokumentasjon fra overordnede ledetekster.
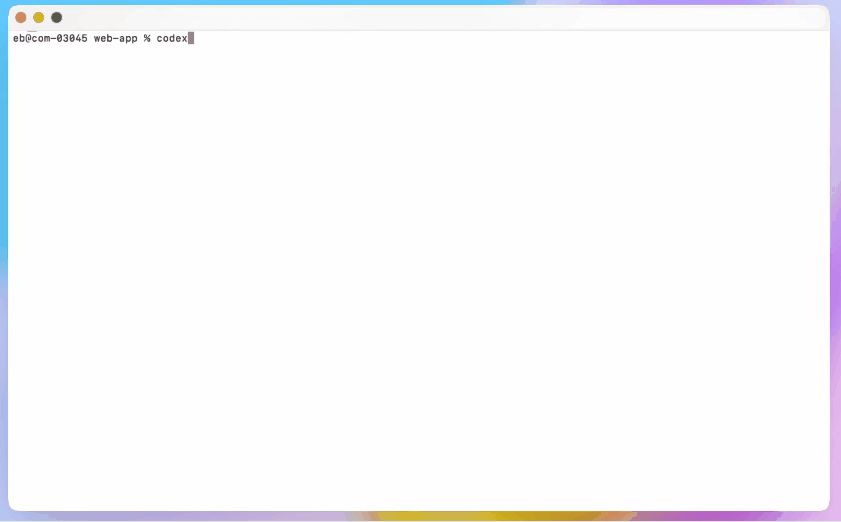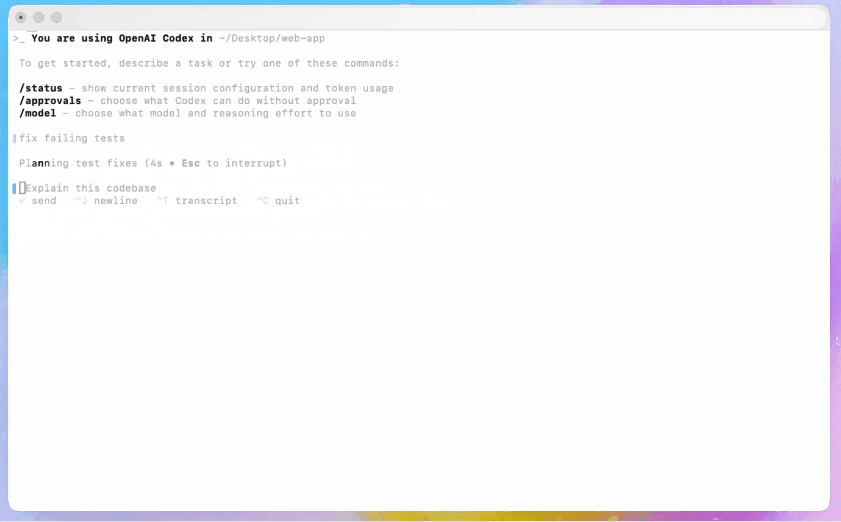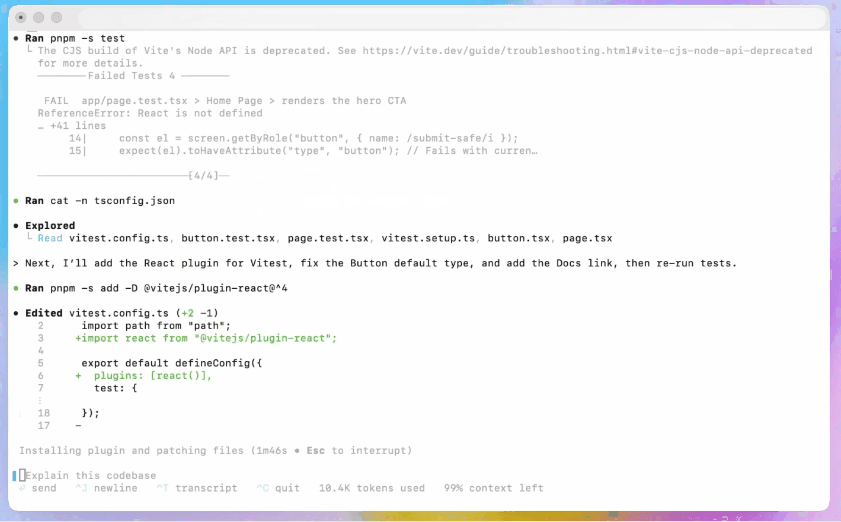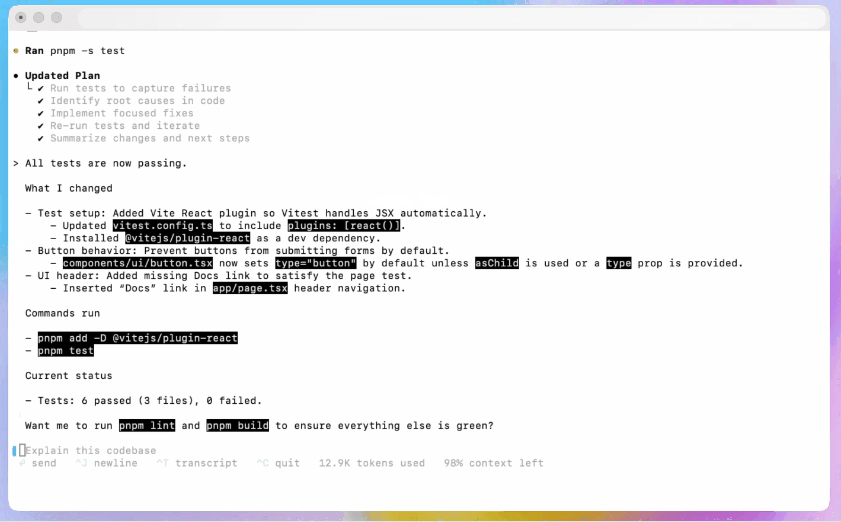
- Agenttesting og iterasjon: Generer kode, kjør tester, analyser feil, oppdater kode og kjør på nytt til testene består – og automatiser effektivt deler av en utviklers redigerings- → test- → fikseringsløkke.
- Storskala refaktorering: Utfør systematiske refaktoreringer på tvers av mange filer samtidig som du opprettholder atferd og tester. Dette er et oppgitt optimaliseringsområde for GPT-5-Codex vs. generisk GPT-5.
- Kodegjennomgang og PR-generering: Produser PR-beskrivelser, foreslåtte endringer med differensialer og gjennomgå kommentarer som samsvarer med prosjektkonvensjoner og forventninger til menneskelig gjennomgang.
- Storkontekstkoderesonnement: Bedre til å navigere og resonnere rundt kodebaser med flere filer, avhengighetsgrafer og API-grenser sammenlignet med generiske chatmodeller.
- Visuelle innganger og utganger: Når man jobber i skyen, kan GPT-5-Codex godta bilder/skjermbilder, visuelt inspisere fremdriften og legge til visuelle artefakter (skjermbilder av innebygd brukergrensesnitt) til oppgaver – en praktisk fordel for feilsøking i frontend og visuelle QA-arbeidsflyter.
Integrasjoner med redigeringsprogram og arbeidsflyt
Codex er dypt integrert i utviklernes arbeidsflyter:
- Codex CLI — terminal-først-interaksjon, støtter skjermbilder, sporing av gjøremål og agentgodkjenninger. CLI er åpen kildekode og innstilt for agentkodingsarbeidsflyter.
- Codex IDE-utvidelse — bygger inn agenten i VS Code (og forks) slik at du kan forhåndsvise lokale diffs, opprette skyoppgaver og flytte arbeid mellom sky- og lokale kontekster med bevart tilstand.
- Codex Cloud / GitHub – skyoppgaver kan konfigureres til å automatisk gjennomgå PR-er, generere midlertidige containere for testing og legge ved oppgavelogger og skjermbilder i PR-tråder.
Merkbare begrensninger og avveininger
- Smal optimaliseringNoen ikke-kodende produksjonsverdier er litt lavere for GPT-5-Codex enn for den generelle GPT-5-varianten – en påminnelse om at spesialisering kan gå på bekostning av generalitet.
- TestavhengighetAgentisk oppførsel avhenger av tilgjengelige automatiserte tester. Kodebaser med dårlig testdekning vil avdekke begrensninger i automatisk verifisering og kan kreve menneskelig tilsyn.
Hvilke typer oppgaver er GPT-5-Codex spesielt god eller dårlig på?
God på: komplekse refaktoreringer, lage stillas for store prosjekter, skrive og fikse tester, følge PR-forventninger og diagnostisere kjøretidsproblemer med flere filer.
Mindre god på: oppgaver som krever oppdatert eller proprietær intern kunnskap som ikke finnes i arbeidsområdet, eller de som krever høy sikkerhet for korrekthet uten menneskelig gjennomgang (sikkerhetskritiske systemer trenger fortsatt eksperter). Uavhengige vurderinger bemerker også et blandet bilde av råkodekvalitet sammenlignet med andre spesialiserte kodemodeller – styrker i agentiske arbeidsflyter oversettes ikke ensartet til klassens beste korrekthet på tvers av alle målestokker.
Hva avslører benchmarks om GPT-5-Codex sin ytelse?
SWE-benk / SWE-benk VerifisertOpenAI oppgir at GPT-5-Codex overgår GPT-5 på agentiske kodingstester som SWE-bench Verified, og viser gevinster på kodeomstruktureringsoppgaver hentet fra store databaser. På SWE-bench Verified-datasettet, som inneholder 500 programvareutviklingsoppgaver fra den virkelige verden, oppnådde GPT-5-Codex en suksessrate på 74.5 %. Dette overgår GPT-5s 72.8 % på samme teststandard, noe som fremhever agentens forbedrede evner. 500 programmeringsoppgaver fra virkelige åpen kildekode-prosjekter. Tidligere kunne bare 477 oppgaver testes, men nå kan alle 500 oppgaver testes → mer komplette resultater.
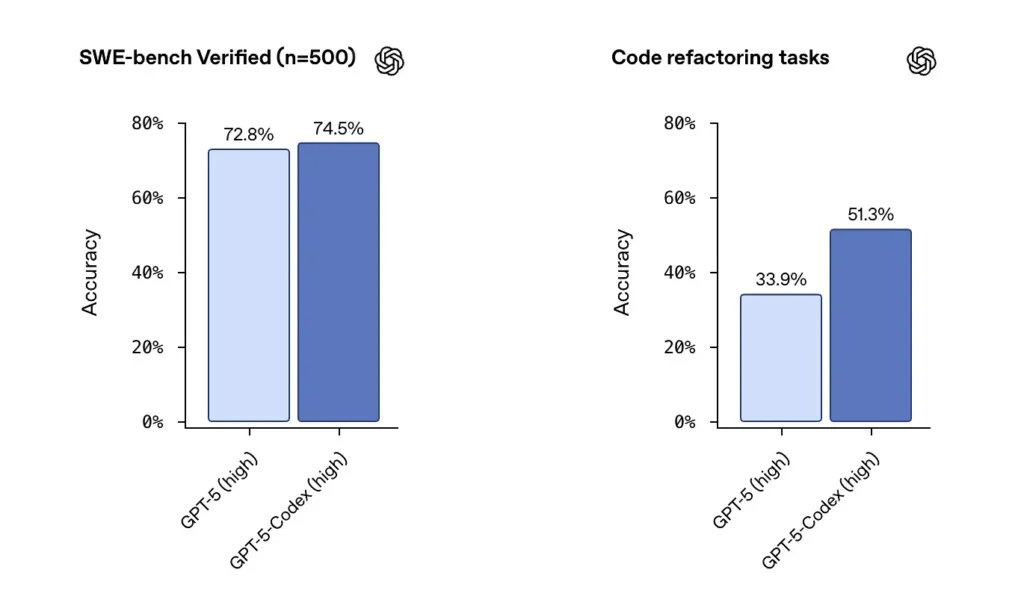
fra tidligere GPT-5-innstillinger til GPT-5-Codex, økte poengsummene for evaluering av koderefaktorering betydelig – tall som skiftet fra ~34 % til ~51 % på en spesifikk refaktoreringsmåling med høy detaljnivå ble fremhevet i tidlige analyser). Disse gevinstene er meningsfulle ved at de gjenspeiler forbedring på store, realistiske refaktorer snarere enn leketøyseksempler – men det er fortsatt forbehold om reproduserbarhet og den nøyaktige testselen.
Hvordan kan utviklere og team få tilgang til GPT-5-Codex?
OpenAI har rullet GPT-5-Codex inn i Codex-produktflatene: det er live der Codex kjører i dag (for eksempel Codex CLI og integrerte Codex-opplevelser). For utviklere som bruker Codex via CLI og ChatGPT-pålogging, vil den oppdaterte Codex-opplevelsen vise GPT-5-Codex-modellen. OpenAI har sagt at modellen vil bli gjort tilgjengelig i det bredere API-et «snart» for de som bruker API-nøkler, men fra og med den første utrullingen er den primære tilgangsveien gjennom Codex-verktøy i stedet for et offentlig API-endepunkt.
Codex CLI
Aktiver Codex til å gjennomgå utkast til PR-er i et sandkassede arkiv, slik at du kan vurdere kommentarkvaliteten uten risiko. Bruk godkjenningsmodusene konservativt.
- Redesignet rundt en agentisk kodingsarbeidsflyt.
- Støtte for å legge ved bilder (som wireframes, design og skjermbilder av UI-feil) gir kontekst for modeller.
- La til en oppgavelistefunksjon for å spore fremdriften til komplekse oppgaver.
- Tilbydde støtte for ekstern verktøy (nettsøk, MCP-tilkobling).
- Det nye terminalgrensesnittet forbedrer verktøyanrop og diff-formatering, og tillatelsesmodusen er forenklet til tre nivåer (skrivebeskyttet, automatisk og full tilgang).
IDE-utvidelse
Integrer i IDE-arbeidsflyter: Legg til Codex IDE-utvidelsen for utviklere som ønsker innebygde forhåndsvisninger og raskere iterasjon. Flytting av oppgaver mellom skyen og lokalt med bevart kontekst kan redusere friksjon på komplekse funksjoner.
- Støtter VS-kode, markør og mer.
- Kall Codex direkte fra redigeringsprogrammet for å utnytte konteksten til den åpne filen og koden for mer nøyaktige resultater.
- Bytt sømløst mellom oppgaver og skymiljøer, og oppretthold kontekstuell kontinuitet.
- Se og arbeid med resultater fra skybaserte oppgaver direkte i redigeringsprogrammet, uten å bytte plattform.
GitHub-integrasjon og skyfunksjoner
- Automatisert PR-gjennomgang: Utløser automatisk fremdrift fra utkast til klar.
- Hjelper utviklere med å be om målrettede anmeldelser direkte i @codex-delen av en PR.
- Betydelig raskere skyinfrastruktur: Reduser responstider for oppgaver med 90 % gjennom containercaching.
- Automatisert miljøkonfigurasjon: Utfører oppsettskript og installerer avhengigheter (f.eks. pip-installasjon).
- Kjører automatisk en nettleser, sjekker frontend-implementeringer og legger ved skjermbilder til oppgaver eller PR-er.

Hva er hensynene knyttet til sikkerhet, trygghet og begrensninger?
OpenAI vektlegger flere lag med avbøtende tiltak for Codex-agenter:
- Opplæring på modellnivå: målrettet sikkerhetsopplæring for å motstå umiddelbare injeksjoner og for å begrense skadelig eller høyrisikoatferd.
- Kontroller på produktnivå: sandkassebasert standardvirkemåte, konfigurerbar nettverkstilgang, godkjenningsmoduser for å kjøre kommandoer, terminallogger og sitater for sporbarhet, og muligheten til å kreve menneskelig godkjenning for sensitive handlinger. OpenAI har også publisert et «systemkorttillegg» som beskriver disse tiltakene og deres risikovurderinger, spesielt for biologiske og kjemiske domeneegenskaper.
Disse kontrollene gjenspeiler det faktum at en agent som er i stand til å kjøre kommandoer og installere avhengigheter har en reell angrepsflate og risiko – OpenAIs tilnærming er å kombinere modelltrening med produktbegrensninger for å begrense misbruk.
Hva er kjente begrensninger?
- Ikke en erstatning for menneskelige anmeldere: OpenAI anbefaler eksplisitt Codex som en ekstra anmelder, ikke en erstatning. Menneskelig tilsyn er fortsatt kritisk, spesielt for sikkerhets-, lisensierings- og arkitekturbeslutninger.
- Referansepunkter og påstander trenger nøye lesing: Anmeldere har påpekt forskjeller i evalueringsundersett, detaljnivåinnstillinger og kostnadsavveininger når man sammenligner modeller. Tidlig uavhengig testing tyder på blandede resultater: Codex viser sterk agentisk oppførsel og forbedringer i refaktorering, men den relative nøyaktigheten sammenlignet med andre leverandører varierer etter referansepunkt og konfigurasjon.
- Hallusinasjoner og ustabil oppførsel: Som alle LLM-er kan Codex hallusinere (oppfinne URL-er, feilaktig presentere avhengighetsgrafer), og agentkjøringene som varer flere timer kan fortsatt oppleve skjørhet i kanttilfeller. Forvent å validere resultatene med tester og menneskelig gjennomgang.
Hva er de bredere implikasjonene for programvareteknikk?
GPT-5-Codex demonstrerer et modningsskifte i LLM-design: i stedet for bare å forbedre funksjonene for nakent språk, optimaliserer leverandører atferd for lange, agentiske oppgaver (flertimers utførelse, testdrevet utvikling, integrerte gjennomgangsrørledninger). Dette endrer produktivitetsenheten fra et enkelt generert kodebit til oppgavefullføring – modellens evne til å ta en sak, kjøre en serie tester og iterativt produsere en validert implementering. Hvis disse agentene blir robuste og godt styrte, vil de omforme arbeidsflyter (færre manuelle refaktoreringer, raskere PR-sykluser, utviklertid fokusert på design og strategi). Men overgangen krever nøye prosessdesign, menneskelig tilsyn og sikkerhetsstyring.
Konklusjon – Hva bør du ta med deg?
GPT-5-Codex er et fokusert skritt mot ingeniørgrad LLM-er: en GPT-5-variant trent, finjustert og produktifisert for å fungere som en dyktig kodeagent i Codex-økosystemet. Den bringer med seg konkrete nye atferder – adaptiv resonneringstid, lange autonome kjøringer, integrert sandkasseutførelse og målrettede forbedringer av kodegjennomgang – samtidig som den opprettholder de kjente forbeholdene fra språkmodeller (behovet for menneskelig tilsyn, nyanser i evaluering og sporadiske hallusinasjoner). For team er den forsvarlige veien målt eksperimentering: pilotering av sikre repositorier, overvåking av resultatmålinger og trinnvis integrering av agenten i anmeldernes arbeidsflyter. Etter hvert som OpenAI utvider API-tilgang og tredjeparts benchmarks sprer seg, bør vi forvente tydeligere sammenligninger og mer konkret veiledning om kostnader, nøyaktighet og beste praksis for styring.
Komme i gang
CometAPI er en enhetlig API-plattform som samler over 500 AI-modeller fra ledende leverandører – som OpenAIs GPT-serie, Google Gemini, Anthropics Claude, Midjourney, Suno og flere – i ett enkelt, utviklervennlig grensesnitt. Ved å tilby konsistent autentisering, forespørselsformatering og svarhåndtering, forenkler CometAPI dramatisk integreringen av AI-funksjoner i applikasjonene dine. Enten du bygger chatboter, bildegeneratorer, musikkomponister eller datadrevne analysepipeliner, lar CometAPI deg iterere raskere, kontrollere kostnader og forbli leverandøruavhengig – alt samtidig som du utnytter de nyeste gjennombruddene på tvers av AI-økosystemet.
Utviklere har tilgang GPT-5-Codex API Gjennom CometAPI er cometAPIs nyeste modeller oppført per artikkelens publiseringsdato. Før du åpner, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen.