

Kimi K2 Thinking er Moonshot AIs nye «tenkende» variant av Kimi K2-familien: en blanding av eksperter (MoE) med billioner av parametere som er eksplisitt konstruert for å tenke mens man handler — dvs. å flette dyp tankekjede-resonnement med pålitelige verktøykall, langsiktig planlegging og automatiserte selvkontroller. Den kombinerer en stor, sparsom ryggrad (≈1T totale parametere, ~32B aktivert per token), en innebygd INT4-kvantiseringspipeline og et design som skalerer inferansetid resonnering (flere «tenketokens» og flere verktøykallsrunder) i stedet for bare å øke antall statiske parametere.
Enkelt sagt: K2 Thinking behandler modellen som en problemløsningsmetode agenten i stedet for en engangsspråkgenerator. Det skiftet – fra «språkmodell» til «tenkemodell» – er det som gjør denne utgivelsen bemerkelsesverdig, og hvorfor mange utøvere anser den som en milepæl innen åpen kildekode-agentisk AI.
Hva er egentlig «Kimi K2-tenkning»?
Arkitektur og viktige spesifikasjoner
K2 Thinking er bygget som en sparsom MoE-modell (384 eksperter, 8 eksperter valgt per token) med omtrent 1 billion totale parametere og ~32 milliarder aktiverte parametere per inferens. Den bruker hybride arkitektoniske valg (MLA-oppmerksomhet, SwiGLU-aktivering) og ble trent med Moonshots Muon/MuonClip-optimaliserer på store tokenbudsjetter beskrevet i deres tekniske rapport. Tenkevarianten utvider basismodellen med kvantisering etter trening (native INT4-støtte), et kontekstvindu på 256k og konstruksjon for å eksponere og stabilisere modellens interne resonneringsspor under reell bruk.
Hva «tenkning» betyr i praksis
«Tenkning» her er et ingeniørmål: å gjøre det mulig for modellen å (1) generere lange, strukturerte kjeder av intern resonnering (tankekjedetokener), (2) kalle eksterne verktøy (søk, python-sandkasser, nettlesere, databaser) som en del av den resonneringen, (3) evaluere og selvverifisere mellomliggende påstander, og (4) iterere på tvers av mange slike sykluser uten å kollapse koherensen. Moonshots dokumentasjon og modellkort viser at K2 Thinking er eksplisitt trent og innstilt til å flette sammen resonnering og funksjonskall, og for å opprettholde stabil agentisk oppførsel på tvers av hundrevis av trinn.
Hva er hovedmålet
Begrensningene ved tradisjonelle storskalamodeller er:
- Genereringsprosessen er kortsiktig og mangler tverrgående logikk;
- Verktøybruken er begrenset (vanligvis kan bare eksterne verktøy kalles én eller to ganger);
- De kan ikke korrigere seg selv i komplekse problemer.
K2 Thinkings kjernemål med design er å løse disse tre problemene. I praksis kan K2 Thinking, uten menneskelig inngripen: utføre 200–300 påfølgende verktøykall; opprettholde hundrevis av trinn med logisk sammenhengende resonnement; løse komplekse problemer gjennom kontekstuell selvsjekk.
Reposisjonering: språkmodell → tenkemodell
K2 Thinking-prosjektet illustrerer et bredere strategisk skifte i feltet: å gå utover generering av betinget tekst mot agentiske problemløsereKjernemålet er ikke primært å forbedre forvirring eller neste-token-prediksjon, men å lage modeller som kan:
- Plan sine egne flertrinnsstrategier;
- Koordinere eksterne verktøy og effektorer (søk, kodeutførelse, kunnskapsbaser);
- Bekreft mellomresultater og korrigering av feil;
- Sustain sammenheng på tvers av lange kontekster og lange verktøykjeder.
Denne omformuleringen endrer både evaluering (referansepunkter vektlegger prosesser og resultater, ikke bare tekstkvalitet) og ingeniørkunst (strukturer for verktøyruting, trinntelling, selvkritikk osv.).
Arbeidsmetoder: hvordan tenkemodeller fungerer
I praksis demonstrerer K2 Thinking flere arbeidsmetoder som kjennetegner «tenkemodell»-tilnærmingen:
- Vedvarende interne spor: Modellen produserer strukturerte mellomtrinn (resonneringsspor) som holdes i kontekst og kan brukes på nytt eller revideres senere.
- Dynamisk verktøyruting: Basert på hvert interne trinn bestemmer K2 hvilket verktøy som skal kalles (søk, kodetolk, nettleser) og når det skal kalles.
- Skalering på testtid: Under slutning kan systemet utvide sin «tenkedybde» (flere interne resonnementstokener) og øke antallet verktøykall for å bedre utforske løsninger.
- Selvverifisering og gjenoppretting: Modellen sjekker eksplisitt resultater, kjører tilregnelighetstester og planlegger på nytt når sjekker mislykkes.
Disse metodene kombinerer modellarkitektur (MoE + lang kontekst) med systemteknikk (verktøyorkestrering, sikkerhetskontroller).
Hvilke teknologiske innovasjoner muliggjør Kimi K2 Thinking?
Kimi K2 Thinkings resonneringsmekanisme støtter sammenflettet tenkning og verktøybruk. K2 Thinkings resonneringsløkke:
- Forstå problemet (analyse og abstrakt)
- Generere en flertrinns resonnementsplan (plankjede)
- Bruk av eksterne verktøy (kode, nettleser, matematikkmotor)
- Verifisering og revisjon av resultatene (verifisering og revisjon)
- Konkluder resonnement (konkluder resonnement)
Nedenfor vil jeg introdusere tre viktige teknikker som gjør resonneringsløkkene i xx mulige.
1) Skalering på testtidspunktet
Hva det er: Tradisjonelle «skaleringslover» fokuserer på å øke antallet parametere eller data under trening. K2 Thinkings innovasjon ligger i: Dynamisk utvidelse av antallet tokens (dvs. tankedybde) i løpet av «resonneringsfasen»; Samtidig utvidelse av antallet verktøykall (dvs. handlingsbredde). Denne metoden kalles testtidsskalering, og dens kjerneantagelse er: «En lengre resonneringskjede + flere interaktive verktøy = et kvalitativt sprang i faktisk intelligens.»
Hvorfor det betyr noe: K2 Thinking optimaliserer eksplisitt for dette: Moonshot viser at utvidelse av «tenketokens» og antall/dybde av verktøykall gir målbare forbedringer i agentiske benchmarks, slik at modellen kan overgå andre modeller av lignende eller større størrelse i FLOP-matchede scenarier.
2) Verktøybasert resonnering
Hva det er: K2 Thinking ble utviklet for å analysere verktøyskjemaer, bestemme autonomt når et verktøy skal kalles, og innlemme verktøyresultater tilbake i den pågående resonneringsstrømmen. Moonshot trente og justerte modellen til å flette tankekjeden sammen med funksjonskall, og stabiliserte deretter denne oppførselen på tvers av hundrevis av sekvensielle verktøytrinn.
Hvorfor det betyr noe: Den kombinasjonen – pålitelig parsing + stabil intern tilstand + API-verktøy – er det som gjør det mulig for modellen å surfe på nett, kjøre kode og orkestrere flertrinns arbeidsflyter som en del av én enkelt økt.
Innenfor sin interne arkitektur danner modellen en utførelsesbane for en «visualisert tankeprosess»: ledetekst → resonnementstokener → verktøykall → observasjon → neste resonnement → endelig svar
3) Langsiktig koherens og selvverifisering
Hva det er: Langhorisontkoherens er modellens evne til å opprettholde en sammenhengende plan og intern tilstand på tvers av mange trinn og over svært lange kontekster. Selvverifisering betyr at modellen proaktivt sjekker sine mellomliggende utganger og kjører eller reviderer trinn når en verifisering mislykkes. Lange oppgaver fører ofte til at modeller driver eller hallusinerer. K2 Thinking takler dette med flere teknikker: svært lange kontekstvinduer (256k), treningsstrategier som bevarer tilstand på tvers av lange CoT-sekvenser, og eksplisitte setningsnivåtrofasthets-/bedømningsmodeller for å oppdage ustøttede påstander.
Hvorfor det betyr noe: Mekanismen for «tilbakevendende resonneringsminne» opprettholder resonneringstilstandens vedvarende karakter, noe som gir den menneskelignende «tenkestabilitet» og «kontekstuell selvkontroll». Ettersom oppgaver strekker seg over mange trinn (f.eks. forskningsprosjekter, kodeoppgaver med flere filer, lange redaksjonelle prosesser), blir det viktig å opprettholde en enkelt sammenhengende tråd. Selvverifisering reduserer stille feil; i stedet for å returnere et plausibelt, men feil svar, kan modellen oppdage inkonsekvenser og konsultere verktøy på nytt eller planlegge på nytt.
muligheter:
- Kontekstuell konsistens: Opprettholder semantisk kontinuitet på tvers av 10 000+ tokens;
- Feildeteksjon og tilbakestilling: Identifiserer og korrigerer logiske avvik i tidlige tankeprosesser;
- Selvverifiseringsløkke: Verifiserer automatisk rimeligheten av svaret etter at resonnementet er fullført;
- Sammenslåing av flerveisresonnement: Velger den optimale banen fra flere logiske kjeder.
Hva er de fire kjernefunksjonene til K2 Thinking?
Dyp og strukturert resonnement
K2 Thinking er innstilt for å generere eksplisitte, flertrinns resonneringsspor og bruke dem til å komme frem til robuste konklusjoner. Modellen viser sterke poengsummer på matte og rigorøse resonneringsbenchmarks (GSM8K, AIME, IMO-stil benchmarks) og demonstrerer en evne til å holde resonnementet intakt over lange sekvenser – et grunnleggende krav for problemløsning på forskningsnivå. Den utmerkede ytelsen på Humanity's Last Exam (44.9 %) demonstrerer analytiske evner på ekspertnivå. Den kan trekke ut logiske rammeverk fra fuzzy semantiske beskrivelser og generere resonneringsgrafer.
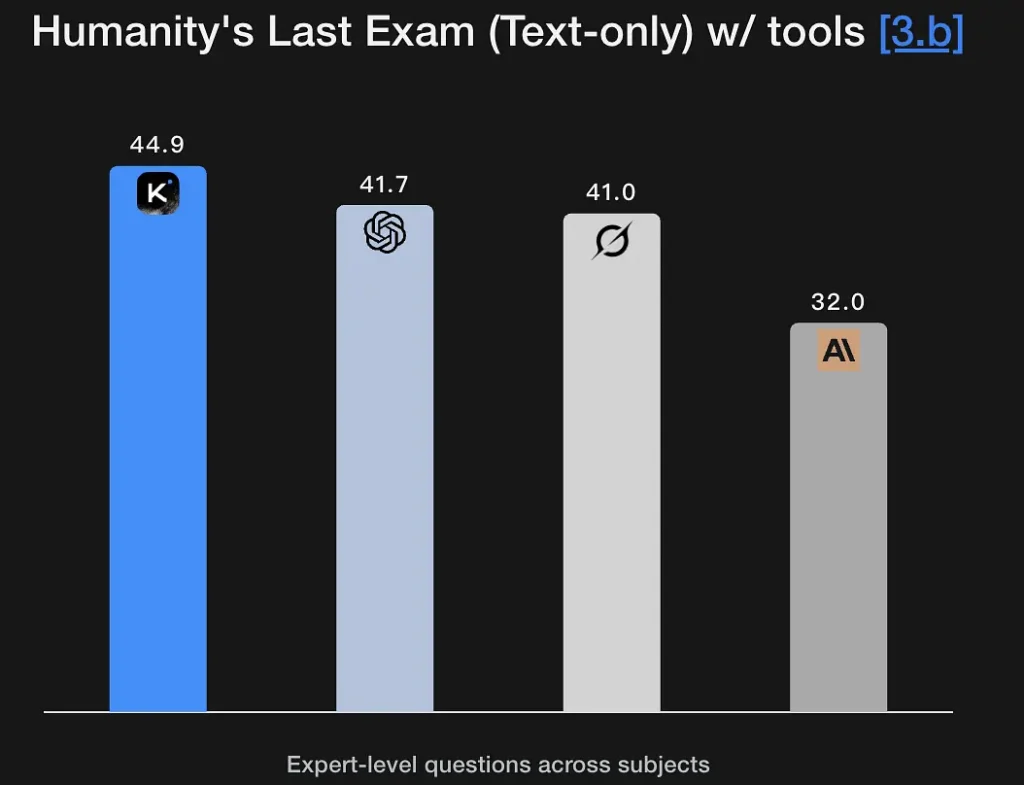
Viktige funksjoner:
- Støtter symbolsk resonnering: Forstår og opererer med matematiske, logiske og programmeringsstrukturer.
- Har evner til hypotesetesting: Kan spontant foreslå og verifisere hypoteser.
- Kan utføre problemdekomposisjon i flere trinn: Bryter ned komplekse mål i flere deloppgaver.
Agentsøk
I stedet for et enkelt hentetrinn, lar agentisk søk modellen planlegge en søkestrategi (hva man skal se etter), utføre den via gjentatte nett-/verktøykall, syntetisere de innkommende resultatene og forbedre spørringen. K2 Thinkings BrowseComp- og Seal-0-verktøyaktiverte poengsummer indikerer sterk ytelse på denne funksjonen; modellen er eksplisitt designet for å opprettholde nettsøk i flere runder med tilstandsfull planlegging.
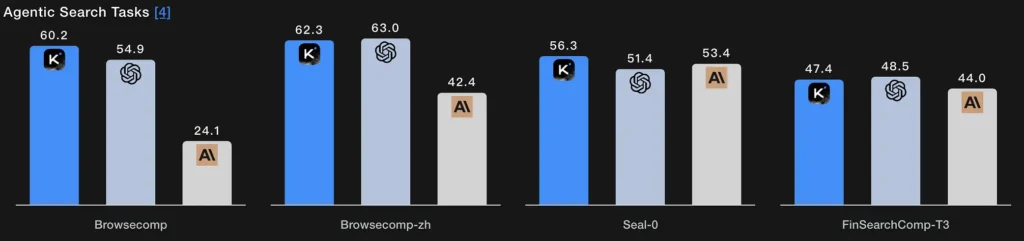
Teknisk essens:
- Søkemodulen og språkmodellen danner en lukket sløyfe: spørringsgenerering → henting av nettsider → semantisk filtrering → fusjon av resonnement.
- Modellen kan adaptivt justere søkestrategien sin, for eksempel ved å søke etter definisjoner først, deretter data, og til slutt verifisere hypoteser.
- I hovedsak er det en sammensatt intelligens av «informasjonsinnhenting + forståelse + argumentasjon».
Agentisk koding
Dette er evnen til å skrive, utføre, teste og iterere på kode som en del av en resonneringsløkke. K2 Thinking legger frem konkurransedyktige resultater på benchmarks for live-koding og kodeverifisering, støtter Python-verktøykjeder i verktøykall og kan kjøre flertrinns feilsøkingsløkker ved å kalle en sandkasse, lese feil og reparere kode over gjentatte passeringer. EvalPlus/LiveCodeBench-poengsummene gjenspeiler disse styrkene. En poengsum på 71.3 % i SWE-Bench Verified-testen betyr at den kan fullføre over 70 % av programvarereparasjonsoppgaver i den virkelige verden.
Den demonstrerer også stabil ytelse i LiveCodeBench V6-konkurransemiljøet, og viser frem algoritmeimplementerings- og optimaliseringsfunksjonene.

Teknisk essens:
- Den benytter en prosess med «semantisk parsing + AST-nivå refaktorering + automatisk verifisering»;
- Kodeutførelse og testing oppnås gjennom verktøykall på utførelseslaget;
- Den realiserer en lukket automatisert utvikling fra å forstå kode → diagnostisere feil → generere oppdateringer → verifisere suksess.
Agentskriving
Utover kreativ prosa er agentisk skriving strukturert, målrettet dokumentproduksjon som kan kreve ekstern research, sitering, tabellgenerering og iterativ forbedring (f.eks. produsere et utkast → faktasjekk → revidere). K2 Thinkings lange kontekst og verktøyorkestrering gjør den godt egnet for flertrinns skrivearbeidsflyter (forskningsbriefer, regelverkssammendrag, innhold med flere kapitler). Modellens åpne seiersrater på Arena-stiltester og langformatskrivingsmålinger støtter denne påstanden.
Teknisk essens:
- Genererer automatisk tekstsegmenter ved hjelp av agentisk tankeplanlegging;
- Kontrollerer internt tekstlogikk gjennom resonnementstokener;
- Kan samtidig aktivere verktøy som søk, beregning og diagramgenerering for å oppnå «multimodal skriving».
Hvordan kan du bruke K2 Thinking i dag?
Tilgangsmåter
K2 Thinking er tilgjengelig som en åpen kildekode-utgivelse (modellvekter og kontrollpunkter) og gjennom plattformens endepunkter og fellesskapshubber (Hugging Face, Moonshot-plattformen). Du kan være selvhost hvis du har tilstrekkelig med datakraft, eller bruke CometAPIs API/vertsbaserte brukergrensesnitt for raskere onboarding. Den dokumenterer også en reasoning_content felt som viser de interne tanketokenene til den som ringer når det er aktivert.
Praktiske tips for bruk
- Start med agentbyggesteinene: eksponer først et lite sett med deterministiske verktøy (søk, Python-sandkasse og en pålitelig fakta-database). Sørg for tydelige verktøyskjemaer slik at modellen kan analysere/validere kall.
- Juster beregningen under testtidFor vanskelig problemløsning, tillat lengre budsjetter og flere verktøybestillingsrunder; mål hvordan kvaliteten forbedres kontra latens/kostnad. Moonshot forkjemper for skalering på testtid som en primær mekanisme.
- Bruk INT4-moduser for kostnadseffektivitetK2 Thinking støtter INT4-kvantisering, som gir betydelige hastighetsøkninger, men validerer også edge-case-atferd på oppgavene dine.
- Overflate resonnementsinnhold nøye: å eksponere interne kjeder kan hjelpe med feilsøking, men øker også eksponeringen for feil i råmodellen. Behandle intern resonnering som diagnostisk ikke autoritativ; kombiner den med automatisert verifisering.
Konklusjon
Kimi K2 Thinking er et bevisst konstruert svar på den neste æraen av AI: ikke bare større modeller, men agenter som tenker, handler og verifisererDen kombinerer MoE-skalering, testtidsberegningsstrategier, innebygd lavpresisjonsinferens og eksplisitt verktøyorkestrering for å muliggjøre vedvarende problemløsning i flere trinn. For team som trenger problemløsning i flere trinn og har ingeniørdisiplinen til å integrere, sandkassere og overvåke agentiske systemer, er K2 Thinking et stort, brukbart skritt fremover – og en viktig stresstest for hvordan industri og samfunn vil styre stadig mer kapabel, handlingsorientert AI.
Utviklere har tilgang Kimi K2 Thinking API gjennom Comet API, den nyeste modellversjonen er alltid oppdatert med den offisielle nettsiden. For å begynne, utforsk modellens muligheter i lekeplass og konsulter API-veiledning for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilby en pris som er langt lavere enn den offisielle prisen for å hjelpe deg med å integrere.
Klar til å dra? → Registrer deg for CometAPI i dag !
Hvis du vil vite flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!