

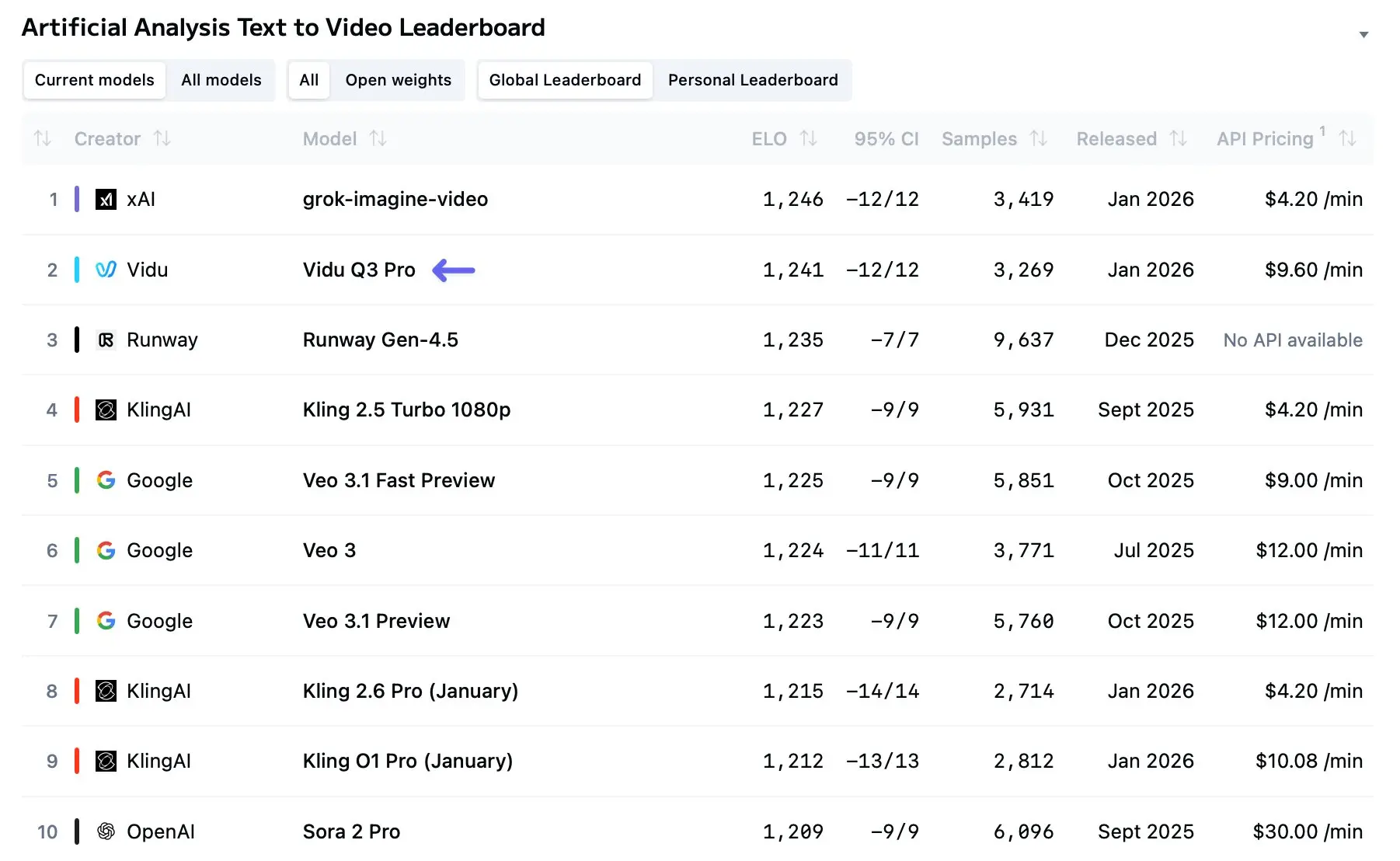
Vidu Q3 kom inn i samtalen tidlig i 2026 som et av de tydeligste signalene på at AI-drevet videogenerering er i ferd med å bevege seg fra korte, novelty-klipp mot genuint narrative, flershots fortellinger. I månedene siden bred lansering har Vidu Q3 blitt en bærebjelke i skapernes arbeidsflyter, forskningspiloter og kommersielle piloter — og med god grunn: den presser varighet, audiovisuell integrasjon og flershots-koherens lenger enn de fleste tidligere modeller, samtidig som den tilbyr et utviklerrettet API for programmatisk bruk.
Hva er Vidu Q3?
Vidu Q3 er den siste flaggskipsiterasjonen av ShengShu Technologys Large Video Model (LVM)-arkitektur. I motsetning til forgjengerne (Vidu 1.0 og 1.5) som krevde separate arbeidsflyter for visuell generering og lyd i etterarbeid, er Vidu Q3 en «alt-i-ett» generativ motor.
Det grunnleggende gjennombruddet i Vidu Q3 er evnen til å generere høydefinisjonsvisuelle og høyfidelitetslyd samtidig.[ Ved å forstå fysikken i lyd og lys sammen eliminerer modellen «uncanny valley» av desynkronisert lyd som ofte ses i konkurrentmodeller. Den støtter opptil 16 sekunder kontinuerlig generering i native 1080p-oppløsning, og posisjonerer seg som et produksjonsklart verktøy for kortfilmer, reklamer og narrativ historiefortelling.
Hvordan fungerer Vidu Q3 under panseret?
Selv om kjernearkitekturen er proprietær, bygger Vidu på U-ViT-fusjon av diffusjonsmodeller og transformere — et design kjent for å balansere koherens, temporal kontinuitet og uttrykksevne i videogenerering.
Denne hybride arkitekturen gjør det mulig for modellen å resonnere om bevegelse, lyd og narrativ kontekst over utvidede sekvenser.
6 fremtredende funksjoner i Vidu Q3
1. Generering med utvidet varighet — hvor lenge kan den gå?
En av Vidu Q3s overskriftsfunksjoner er lengre varighet for enkeltgenerering. Mange tidligere generasjonsmodeller fokuserte på mikroklipp; Q3 utvider bevisst klipplengden for å tillate enkle historieark og flershots-sekvenser uten at skapere må klippe sammen mange små klipp. Plattformdokumentasjon og partnerportaler oppgir opptil ~16 sekunder native generering i én passering (format- og kvalitetsalternativer kan variere etter leverandør og API-plan). Dette er viktig fordi det å gå fra 4–8 sekunder til 16 sekunder endrer hvordan skapere planlegger scener, skriver «beats» og tempojusterer lydsignaler.
2. Visuell kvalitet og temporal koherens
Uavhengige evalueringer og tidlige benchmarks viser at Vidu Q3 produserer klarere bilder og færre forvrengninger på rammenivå enn tidligere forbrukermodeller. Forbedringer i arkitektur og dataaugmentering ser ut til å redusere flimmer og forbedre bevegelseskontinuitet for klipp under 10–16 sekunder. Modellen kan likevel slite med tette scener med flere subjekter (folkemengder, kompliserte fysiske interaksjoner) der okklusjon og finbevegelse krever solid fysisk resonnering. Sammenlignende rangeringer og modell-leaderboards har allerede plassert Vidu Q3 høyt på T2V (tekst-til-video)-lister, selv om rangeringene varierer etter benchmark og datasett.
3. Native lyd + video-generering
I motsetning til systemer som produserer stille visuelle og overlater lyd til etterarbeid, integrerer Vidu Q3 lydgenerering i modellen. Resultatet er leppesynkronisert dialog, tidsbestemt SFX og valgfri bakgrunnsmusikk produsert sammen med bildene. Å integrere lyd på modellnivå reduserer synkroniseringsfeil (drift i leppesynkronisering, ute-av-takt signaler) og korter ned produksjonssyklusen for demoer, forhåndsvisninger og mange ferdigformaterte korte klipp.
4. Smart kamerakontroll og flershots-narrativer
Q3s «smarte kamera»-funksjoner tolker prompt for kamerabevegelser (panorering, dolly, tracking) og flershots-sekvenser. I stedet for å produsere ett enkelt statisk perspektiv kan modellen generere planlagte klipp og overganger slik at det resulterende klippet fremstår som en regi-styrt scene. For skapere endrer dette output fra «et enkelt komponert bilde som beveger seg» til «en kort scene med flere shots». Det forbedrer seeropplevelsen og muliggjør rikere visuell historiefortelling i én generering.
5. Multi-referanse-konsistens og karaktertrofasthet
Vidu (som plattform) har investert i «reference to video»- og multireferanse-konsistenssystemer som lar skapere laste opp flere referansebilder for å låse karakteridentitet på tvers av rammer. Q3 bygger videre på disse ideene for å holde karakteruttrykk og rekvisitter konsistente på tvers av flere kameravinkler og klipp — et grunnleggende, men avgjørende krav for koherent narrativ output. Dette er spesielt nyttig for anime eller stiliserte prosjekter der det er kritisk å opprettholde konsistent karakterkunst.
6. Klar for utviklere: API-er og arbeidsflyt
Vidus modellsuite — inkludert Q3 — er tilgjengelig via web-grensesnitt og et programmatiskt REST-API. Utviklere kan sende tekst-til-video- eller bilde-pluss-tekst-oppgaver til et inferens-endepunkt, motta en oppgave-ID og poll’e for resultater (typisk asynkront jobb-mønster). API-et tilbyr parametere som oppløsning, sideforhold, varighet, bevegelsesamplitude og en bryter for lydgenerering. Det gjør Q3 tilgjengelig for automatisering, batch-arbeidsflyter og integrering med redaksjonelle pipelines.
Hvordan står Vidu Q3 seg mot Sora 2 og Veo 3.1?
Kort svar: Vidu Q3 konkurrerer sterkt på lengre narrative utganger og integrert audio/video for 10–20s scener, Sora 2 utmerker seg i fysisk plausible enkeltskudd-realime og sosial integrasjon, og Veo 3.1 leder på pikselnivå-polish, verktøy for fler-ramme-kontinuitet og enterprise API-integrasjon. Nedenfor pakker vi ut forskjellene langs praktiske akser.
Hvilken modell er sterkest på realisme og fysikk: Sora 2 eller Vidu Q3?
Sora 2 (OpenAI) ble eksplisitt trent for fysisk plausibilitet og verdenssimulering — dens offentlige notater fremhever avansert fysikkatferd, nøyaktige objektinteraksjoner og svært realistiske bevegelsesbaner. Sora 2 tilbyr også synkronisert lyd og sosiale app-integrasjoner (inkludert cameos og en mobilapp), noe som gjør den eksepsjonelt sterk for livaktige, fysisk koherente scener. Hvis briefen din krever nøyaktige kollisjoner, realistisk dynamikk eller fotorealistisk menneskelig bevegelse i korte, selvstendige shots, er Sora 2 ofte overlegen.
Vidu Q3, derimot, er posisjonert mer som en fortellingsmotor: lengre klipp, flershots-sekvenser og kamerakontroll i regissør-stil. Det betyr ikke at Vidu ofrer realisme, men dens primære gevinster er narrativ kontinuitet og kombinert audiovisuell output heller enn rå fysikk-simulering. For filmatisk kort historiefortelling (f.eks. en 16s produktdemo med klipp og VO) er Q3s arbeidsflyt ofte raskere og enklere.
Hvilken modell er bedre for filmatisk polish og høy fidelitet: Veo 3.1 vs Vidu Q3?
Veo 3.1 (Google / DeepMind / Gemini) er markedsført som et høyfidelitets, enterprise-alternativ med sterke kontinuitetskontroller, native lydgenerering og støtte i Googles cloud/Vertex/Gemini-stakk. Veo 3.1 introduserte avanserte «ingredients to video»-funksjoner, vertikal (9:16) native støtte og oppskalering til høye oppløsninger (inkludert 4K i noen løp). For prosjekter som krever høyeste pikselkvalitet, presis fargeharmoni og stramme enterprise API-er er Veo 3.1 ofte førstevalget.
Vidu Q3 hevder seg ved å fokusere på utvidet varighet + flershots-kohærent fortelling og en skaper-sentrert produktisering (raske web-lekeplasser, multireferanse-orkestrering). Hvis prioriteten din er å produsere en menneskestyrt kort scene med flere kamerabevegelser og integrerte lydsignaler (og du verdsetter lengde over rå pikselpolish), er Vidu Q3 overbevisende. For rå fotorealistisk kvalitet har Veo 3.1 normalt et forsprang.
Per tidlig 2026 består AI-videotriumviratet av OpenAIs Sora 2, Googles Veo 3.1 og Vidu Q3. Slik står de mot hverandre i en direkte sammenligning:
| Funksjon | Vidu Q3 | Sora 2 | Veo 3.1 |
|---|---|---|---|
| Maks varighet for enkeltklipp | ~16 s | Opptil ~25 s (Pro) | 8 s (med funksjoner for narrativ sammensying) |
| Native lydgenerering | Ja (integrert) | Ja (eksperimentell) | Ja (avansert) |
| Kinematografisk kamerakontroll | Ja (shot-bevisst) | Begrensede forhåndsinnstillinger | Ja (konsistens for flere shots) |
| Multi-shot-narrativ | Ja | Ja | Ja |
| Tekstgjengivelse i rammer | Ja | Varierer | Varierer |
| Oppløsning | 1080p | 1080p | 1080p / 4K i spesielle tilfeller |
| Primær brukstilfelle | Narrativ historiefortelling, animasjon | Høykost konsept/film | YouTube Shorts / TikTok |
Analyse:
- Vs. Sora 2: Sora 2 er fortsatt tungvekteren for ren visuell fidelitet og surrealistisk fantasi («Hollywood-kvalitet»). Vidu Q3 går imidlertid forbi på arbeidsflyteffektivitet takket være 16-sekunders grensen og overlegen lydintegrasjon. For skapere som trenger et «ferdig-i-én»-klipp, er Q3 raskere.
- Vs. Veo 3.1: Googles Veo 3.1 utmerker seg i hastighet for kortere, sosiale klipp (4–8s) og integreres dypt med YouTube. Vidu Q3 sikter høyere opp i verdikjeden, rettet mot profesjonelle animatører og filmskapere som trenger lengre, kontinuerlige tagninger som Veo sliter med å opprettholde konsekvent.
Hvilke praktiske anvendelser muliggjør Vidu Q3?
Annonsering og kortformatmarkedsføring
Merker kan prototype annonsekonsepter ende-til-ende mye raskere: skriv et manus, generer et 16-sekunders visuelt klipp med synkronisert VO og SFX, iterer på ordlyd og shot-komposisjon, og produsér flerspråklige dubs ved å bruke språkvarianter i prompting. For A/B-testing av kreative for sosiale medier er den reduserte gjennomløpstiden en klar forretningsgevinst. Kasuistikker publisert av plattformer viser markedsførere som bruker Vidu Q3 til mikroannonser og produktteasere.
Storyboard og previsualisering for film og TV
Regissører og klippere bruker korte AI-klipp som previsualisering (previz) for å blokkere scener, teste kamerabevegelser og pitche treatments. Vidu Q3s flershots-sekvenser og smarte kamerakontroller er spesielt nyttige her: kreative team kan iterere på blokking og dialog uten kostnaden ved location-opptak. Selv om AI-previz ikke erstatter regi på sett, korter den ned beslutningssyklusene i tidlig fase.
E-læring og forklaringsvideoer
Utdanning og bedriftslæring kan generere konsise, animerte forklaringssegmenter med synkronisert fortellerstemme og annotert SFX. For standardisert innhold (produktopplæring, onboarding) reduserer dette avhengigheten av kostbare produksjonshus og akselererer lokaliserte versjoner. Tid-til-publisering og native lydfunksjoner gjør Vidu Q3 attraktiv for disse bruksområdene.
Spill, konseptkunst og indieproduksjon
Indieutviklere og spillteam bruker korte AI-filmatiske klipp til trailere, NPC-dialogmockups eller stilutforsking. Vidu Q3s støtte for referansebilder og karakterkonsistens bidrar til å holde et spill-IPs visuelle identitet koherent i prototype-trailere. Modellen brukes også til pitchmateriale for å sikre finansiering eller interesse fra utgivere.
Tilgjengelighet og rask lokalisering
Fordi lyd genereres native, forenkler Vidu Q3 flerspråklige versjoner: generér samme shot med ulike språkprompter, eller be om varierte stemmeklangfarger. Dette muliggjør rask lokalisering av markedsinnhold eller opplæringsressurser, samtidig som leppesynkroniseringsapproksimasjoner er gode nok for mange kortformatkontekster (selv om leppematch på toppnivå for kringkasting fortsatt kan kreve menneskelig justering).
Er Vidu Q3 den beste AI-videomodellen i 2026?
Å erklære én «beste» modell overser nyanser: vinneren avhenger av brukstilfelle.
- For fotorealistisk, fysisk forankret output og konservativ sikkerhetshåndtering er OpenAIs Sora 2 ofte sett på som toppvalget. Den vektlegger realisme og robust moderering, noe som gjør den attraktiv for high-end produksjon og risikoaverse virksomheter.
- For plattformintegrert, formatoptimalisert kortformatinnhold gjør Veo 3.1s native vertikale utganger og Googles app-integrasjoner (YouTube Shorts, Google Photos) den unikt praktisk.
- For rask audio-video-prototyping, flershots-narrativ kontroll og en sterk balanse av fortellingsfunksjoner er Vidu Q3 et utropstegn — spesielt når iterasjonshastighet og integrert lyd betyr mer enn absolutt fotorealisme. Tidlige benchmarks og leverandørrapportering plasserer Vidu Q3 høyt i T2V-rangeringer, og funksjonene gjør den til et praktisk valg for markedsførere, uavhengige skapere og studioer som prototyper nye ideer.
Begrensninger og hensyn?
Selv om Vidu Q3 markerer et gjennombrudd, finnes det avveininger:
- Klipplengde er fortsatt begrenset (~16 s), så lengre narrativer trenger sammensying eller flere prompt.
- Ressurskostnad kan skaleres med HD-generering og kompleks lyd.
- AI-verktøy krever fortsatt redaksjonell vurdering for å finpusse og redigere output til ferdige produkter.
Så: Vidu Q3 er en utfordrer i toppsjiktet i 2026, særlig for skapere som prioriterer native lydarbeidsflyter og flershots-historiefortelling. Om den er den beste avhenger av den konkrete produksjonsbriefen, regulatoriske rammer og brukerens distribusjonsløp.
Konklusjon
Vidu Q3 skiller seg ut i 2026 som en ledende AI-videomodell som kan produsere narrativ-klare, integrerte audio-video-klipp som bygger bro mellom kreativitet og produksjonskrav. Sammenlignet med Sora 2s sterke narrative koherens og Veo 3.1s filmatiske realisme tilbyr Vidu Q3 et balansert verktøysett ideelt for historiefortellere, innholdsskapere og kommersielle arbeidsflyter.
Etter hvert som benchmarks viser høy ytelse og integrerte funksjoner, representerer Vidu Q3 et vendepunkt i generativ video-AI — som gjør kompleks audiovisuell produksjon mer tilgjengelig og effektiv.
Utviklere kan få tilgang til Vidu Q3, Veo 3.1 og Sora 2 via CometAPI, de nyeste modellene er listet per artikkelens publiseringsdato. For å komme i gang, utforsk modellens kapabiliteter i Playground og se API guide for detaljerte instrukser. Før tilgang, sørg for at du er innlogget på CometAPI og har fått API-nøkkelen. CometAPI tilbyr en pris langt lavere enn den offisielle for å hjelpe deg å integrere.
Ready to Go?→ Registrer deg for videogenerering i dag !
Hvis du vil ha flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!