

I et landskap dominert av «skalér for enhver pris»-filosofien—der modeller som Flux.2 og Hunyuan-Image-3.0 skyver antallet parametere opp i massive 30B til 80B—har en ny utfordrer dukket opp for å ryste status quo. Z-Image, utviklet av Alibaba’s Tongyi Lab, er offisielt lansert og bryter forventninger med en slank arkitektur på 6 milliarder parametere som kan måle seg med kvaliteten til bransjegiganter, samtidig som den kjører på maskinvare for forbrukere.
Lansert sent i 2025, fanget Z-Image (og den lynraske varianten Z-Image-Turbo) umiddelbart AI-miljøet, og passerte 500 000 nedlastinger innen 24 timer etter debut. Ved å levere fotorealistiske bilder på bare 8 inferenssteg, er Z-Image ikke bare en modell; det er en demokratiserende kraft innen generativ AI, som muliggjør høy troverdighet på laptops som ville slite med konkurrentene.
Hva er Z-Image?
Z-Image er en ny, åpen kildekode-basert grunnlagsmodell for bildegenerering, utviklet av forskerteamet Tongyi-MAI / Alibaba Tongyi Lab. Det er en generativ modell med 6 milliarder parametere bygget på en ny Scalable Single-Stream Diffusion Transformer (S3-DiT)-arkitektur som sammenkjedet teksttokens, visuelle semantiske tokens og VAE-tokens i én enkelt prosesseringsstrøm. Designmålet er eksplisitt: levere toppklasse fotorealisme og instruksjonsfølge, samtidig som inferenskostnaden reduseres kraftig og praktisk bruk på forbruker-maskinvare muliggjøres. Z-Image-prosjektet publiserer kode, modellvekter og en nettdemo under en Apache-2.0-lisens.
Z-Image leveres i flere varianter. Den mest omtalte utgaven er Z-Image-Turbo — en destillert, få-stegs versjon optimalisert for produksjonsdistribusjon — pluss den ikke-destillerte Z-Image-Base (grunnsjekkpunkt, bedre egnet for finjustering) og Z-Image-Edit (instruksjonstunet for bilderedigering).
Turbo-fordelen: 8-stegs inferens
Flaggskipvarianten Z-Image-Turbo benytter en progressiv destillasjonsteknikk kjent som Decoupled-DMD (Distribution Matching Distillation). Dette lar modellen komprimere genereringsprosessen fra standard 30–50 steg ned til bare 8 steg.
Resultat: Genereringstider under ett sekund på bedrifts-GPU-er (H800) og praktisk talt sanntidsytelse på forbrukerkort (RTX 4090), uten det «plastiske» eller «utvaskede» preget som er typisk for andre turbo-/lynmodeller.
4 nøkkelfunksjoner i Z-Image
Z-Image er pakket med funksjoner som passer både tekniske utviklere og kreative fagfolk.
1. Uovertruffen fotorealisme og estetikk
Til tross for kun 6 milliarder parametere, produserer Z-Image bilder med slående klarhet. Den utmerker seg i:
- Hudtekstur: Replikerer porer, ujevnheter og naturlig lyssetting på menneskelige motiver.
- Materialfysikk: Gjengir glass, metall og tekstiler med høy presisjon.
- Lyssetting: Overlegen håndtering av filmatisk og volumetrisk lys sammenlignet med SDXL.
2. Innebygd tospråklig tekstgjengivelse
En av de største utfordringene i AI-bildegenerering har vært tekstgjengivelse. Z-Image løser dette med innebygd støtte for både engelsk og kinesisk.
- Den kan generere komplekse plakater, logoer og skilt med korrekt staving og kalligrafi på begge språk—en funksjon som ofte mangler i vestlig-sentriske modeller.
3. Z-Image-Edit: instruksjonsbasert redigering
Sammen med basismodellen lanserte teamet Z-Image-Edit. Denne varianten er finjustert for image-to-image-oppgaver, og lar brukere endre eksisterende bilder ved hjelp av naturlige språkbeskrivelser (f.eks. «Få personen til å smile», «Endre bakgrunnen til et snødekt fjell»). Den opprettholder høy konsistens i identitet og lyssetting under disse transformasjonene.
4. Tilgjengelighet på forbruker-maskinvare
- VRAM-effektivitet: Kjører komfortabelt på 6GB VRAM (med kvantisering) til 16GB VRAM (full presisjon).
- Lokal kjøring: Full støtte for lokal distribusjon via ComfyUI og
diffusers, som frigjør brukere fra skyavhengigheter.
Hvordan fungerer Z-Image?
Enkeltstrøms diffusjonstransformer (S3-DiT)
Z-Image avviker fra klassiske to-strømsdesign (separate tekst- og bildeenkodere/strømmer) og sammenkjedet i stedet teksttokens, bilde-VAE-tokens og visuelle semantiske tokens i én enkelt transformer-inngang. Denne enkeltstrøms tilnærmingen forbedrer parameterutnyttelsen og forenkler kryssmodal tilpasning i transformer-ryggraden, som ifølge forfatterne gir en gunstig effektivitet-/kvalitetshandel for en 6B-modell.
Decoupled-DMD og DMDR (destillasjon + RL)
For å muliggjøre få-stegs (8-stegs) generering uten den vanlige kvalitetsstraffen, utviklet teamet en Decoupled-DMD-destillasjonstilnærming. Teknikken separerer CFG (classifier-free guidance)-augmentering fra distribusjonsmatching, slik at hver kan optimaliseres uavhengig. De anvender deretter et ettertreningssteg med forsterkningslæring (DMDR) for å finpusse semantisk tilpasning og estetikk. Sammen produserer disse Z-Image-Turbo med langt færre NFE-er enn typiske diffusjonsmodeller, samtidig som høy realisme opprettholdes.
Treningsgjennomstrømming og kostnadsoptimalisering
Z-Image ble trent med en livssyklusoptimaliseringstilnærming: kuraterte datapipelines, et strømlinjeformet læreplanopplegg og effektivitetsbevisste implementeringsvalg. Forfatterne rapporterer at hele treningsløpet ble fullført på omtrent 314K H800 GPU-timer (≈ USD $630K) — en eksplisitt, reproduserbar ingeniørmåling som posisjonerer modellen som kostnadseffektiv relativt til svært store (>20B) alternativer.
Benchmark-resultater for Z-Image-modellen
Z-Image-Turbo rangerte høyt på flere moderne ledertavler, inkludert en topp åpen kildekode-posisjon på Artificial Analysis Text-to-Image leaderboard og sterk ytelse på Alibaba AI Arena menneskelig-preferanse-evalueringer.
Men kvalitet i virkeligheten avhenger også av promptformulering, oppløsning, oppskalingspipeline og ekstra etterbehandling.
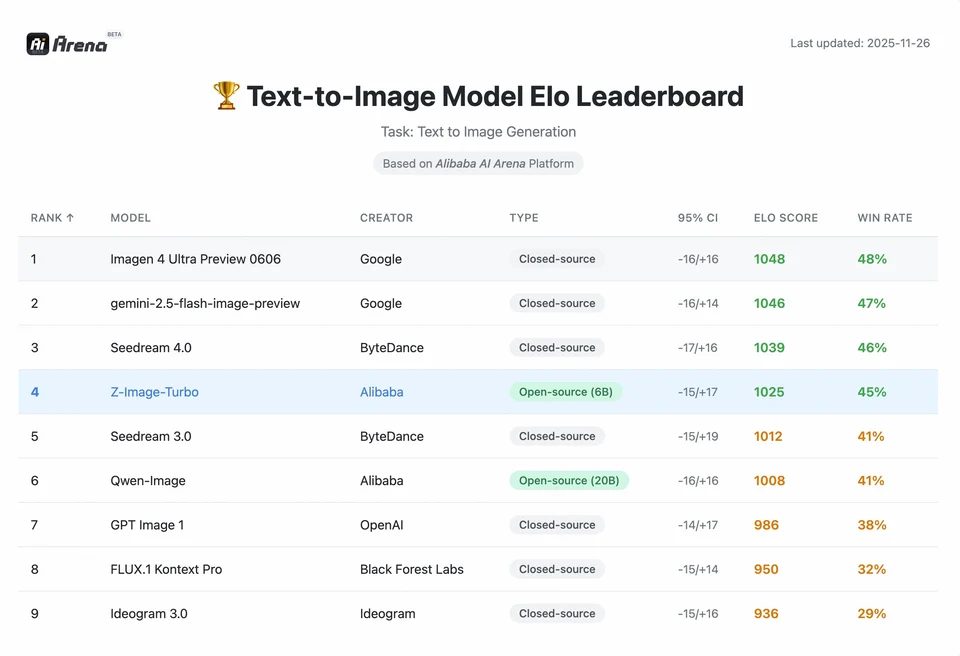
For å forstå omfanget av Z-Images prestasjon, må vi se på dataene. Nedenfor er en sammenlignende analyse av Z-Image mot ledende åpne og proprietære modeller.
Sammenlignende benchmark-sammendrag
| Funksjon / Metrikk | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Arkitektur | S3-DiT (enkeltstrøm) | MM-DiT (dobbelstrøm) | U-Net | Diffusjonstransformer |
| Parametere | 6 milliarder | 12B / 32B | 2.6B / 6.6B | ~30B+ |
| Inferenssteg | 8 steg | 25–50 steg | 1–4 steg | 30–50 steg |
| Nødvendig VRAM | ~6GB – 12GB | 24GB+ | ~8GB | 24GB+ |
| Tekstgjengivelse | Høy (EN + CN) | Høy (EN) | Moderat (EN) | Høy (CN + EN) |
| Genereringshastighet (4090) | ~1,5–3,0 sekunder | ~15–30 sekunder | ~0,5 sekunder | ~20 sekunder |
| Fotorealisme-score | 9,2/10 | 9,5/10 | 7,5/10 | 9,0/10 |
| Lisens | Apache 2.0 | Ikke-kommersiell (Dev) | OpenRAIL | Tilpasset |
Dataanalyse og ytelsesinnsikter
- Hastighet vs. kvalitet: Selv om SDXL Turbo er raskere (1 steg), degraderes kvaliteten betydelig ved komplekse prompts. Z-Image-Turbo treffer «sweet spot» ved 8 steg, matcher kvaliteten til Flux.2 og er 5–10x raskere.
- Demokratisering av maskinvare: Flux.2, selv om den er kraftig, er i praksis avgrenset til 24GB VRAM-kort (RTX 3090/4090) for rimelig ytelse. Z-Image lar brukere med mellomklassekort (RTX 3060/4060) generere profesjonelle 1024x1024-bilder lokalt.
Hvordan kan utviklere få tilgang til og bruke Z-Image?
Det finnes tre vanlige tilnærminger:
- Hosted / SaaS (web-UI eller API): Bruk tjenester som z-image.ai eller andre leverandører som distribuerer modellen og tilbyr et webgrensesnitt eller betalt API for bildegenerering. Dette er den raskeste veien for eksperimentering uten lokal oppsett.
- Hugging Face + diffusers-pipelines: Hugging Face
diffusers-biblioteket inkludererZImagePipelineogZImageImg2ImgPipelineog gir typiskefrom_pretrained(...).to("cuda")-arbeidsflyter. Dette er den anbefalte veien for Python-utviklere som ønsker enkel integrasjon og reproduserbare eksempler. - Lokal, native inferens fra GitHub-repoet: Tongyi-MAI-repoet inkluderer native inferensskript, optimaliseringsalternativer (FlashAttention, kompilering, CPU-offload) og instruksjoner for å installere
diffusersfra kilde for den nyeste integrasjonen. Denne veien er nyttig for forskere og team som ønsker full kontroll eller å kjøre egen trening/finjustering.
Hvordan ser et minimalt Python-eksempel ut?
Nedenfor er et konsist Python-snutt som bruker Hugging Face diffusers og demonstrerer tekst-til-bilde-generering med Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("Et filmatisk portrett av en robotmaler, studiolys, ultradetaljert")
Merknader: Standardverdier og anbefalte innstillinger for guidance_scale er annerledes for Turbo-modeller; dokumentasjonen antyder at veiledningen kan settes lavt eller null for Turbo avhengig av ønsket oppførsel.
Hvordan kjører du bilde-til-bilde (redigering) med Z-Image?
ZImageImg2ImgPipeline støtter bilderedigering. Eksempel:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Gjør denne skissen til en fantasirik elvedal med livlige farger"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Dette speiler de offisielle bruksmønstrene og passer for kreativ redigering og inpainting-oppgaver.
Hvordan bør du utforme prompts og veiledning?
- Vær eksplisitt med struktur: For komplekse scener bør prompts struktureres til å inkludere scenekomposisjon, fokusobjekt, kamera/linse, lyssetting, stemning og eventuelle tekstelementer. Z-Image drar nytte av detaljerte prompts og håndterer posisjonelle/fortellende hint godt.
- Juster
guidance_scalenøye: Turbo-modeller kan anbefale lavere veiledningsverdier; eksperimentering er nødvendig. For mange Turbo-arbeidsflyter girguidance_scale=0.0–1.0med seed og faste steg konsistente resultater. - Bruk bilde-til-bilde for kontrollerte endringer: Når du må bevare komposisjonen, men endre stil/farger/objekter, start fra et init-bilde og bruk
strengthfor å styre omfanget av endringen.
Beste bruksområder og beste praksis
1. Rask prototyping og storyboarding
Bruksområde: Filmregissører og spilldesignere trenger å visualisere scener umiddelbart.
Hvorfor Z-Image? Med generering under 3 sekunder kan skapere iterere gjennom hundrevis av konsepter i én økt, finjustere lyssetting og komposisjon i sanntid uten å vente minutter på en rendering.
2. E-handel og reklame
Bruksområde: Generere produktbakgrunner eller livsstilsbilder for varer.
Beste praksis: Bruk Z-Image-Edit.
Last opp et rått produktfoto og bruk en instruksjonsprompt som «Plasser denne parfymeflasken på et trebord i en solfylt hage.» Modellen bevarer produktets integritet samtidig som den hallusinerer en fotorealistisk bakgrunn.
3. Tospråklig innholdsproduksjon
Bruksområde: Globale markedsføringskampanjer som krever ressurser for både vestlige og asiatiske markeder.
Beste praksis: Utnytt tekstgjenvgivelsesfunksjonen.
- Prompt: «Et neonskilt med teksten ‘OPEN’ og ‘营业中’ som gløder i en mørk bakgate.»
- Z-Image vil gjengi både engelske og kinesiske tegn riktig—noe de fleste andre modeller ikke klarer.
4. Lavressurs-miljøer
Bruksområde: Kjøre AI-generering på kantenheter eller standard kontor-laptops.
Optimaliseringstips: Bruk den INT8-kvantiserte versjonen av Z-Image. Dette reduserer VRAM-bruken til under 6GB med neglisjerbar kvalitetsreduksjon, og gjør det mulig i lokale apper på ikke-spill-laptops.
Konklusjon: hvem bør bruke Z-Image?
Z-Image er designet for organisasjoner og utviklere som ønsker høy kvalitet på fotorealisme med praktisk ventetid og kostnader, og som foretrekker åpen lisensiering og lokal eller egendefinert hosting. Den er spesielt attraktiv for team som trenger rask iterasjon (kreative verktøy, produktmockups, sanntidstjenester) og for forskere/samfunnsmedlemmer som er interessert i finjustering av en kompakt, men kraftig bildemodell.
CometAPI tilbyr tilsvarende mindre begrensede Grok Image-modeller, samt modeller som Nano Banana Pro, GPT- image 1.5, Sora 2 (Can Sora 2 generate NSFW content? How can we try it?) osv.—forutsatt at du har de riktige NSFW-tipsene og triksene for å omgå begrensningene og begynne å skape fritt. Før tilgang, sørg for at du har logget inn på CometAPI og fått API-nøkkelen. CometAPI tilbyr en pris langt under den offisielle prisen for å hjelpe deg med å integrere.
Klar til å komme i gang?→ Free trial for Creating !