

The OpenThinker-32B API is an open-source, highly efficient interface that enables developers to leverage the model’s advanced language understanding, multi-modal capabilities, and customizable features for a wide range of applications with minimal resource overhead.
Introduction
Artificial intelligence continues to redefine the boundaries of technology, and the OpenThinker-32B stands as a testament to this evolution. Designed to push the limits of machine learning capabilities, this model represents a significant leap forward in natural language processing (NLP), reasoning, and multi-modal intelligence. Whether you’re a developer, researcher, or business leader, understanding the intricacies of OpenThinker-32B can unlock new possibilities for innovation and efficiency.
In this comprehensive introduction, we’ll explore the OpenThinker-32B model in depth, starting with its basic definition and API, followed by its technical architecture, evolutionary journey, key advantages, measurable performance indicators, and real-world application scenarios. By the end, you’ll have a clear picture of why this AI model is poised to shape the future of intelligent systems.
What Is OpenThinker-32B? A Quick Overview
At its core, OpenThinker-32B is a 32-billion-parameter transformer-based AI model developed to excel in complex language understanding, generation, and multi-task problem-solving. The OpenThinker-32B API can be described in one sentence: A powerful interface that allows developers to integrate advanced NLP, reasoning, and multi-modal capabilities into applications with ease. Built with scalability and adaptability in mind, it caters to a wide range of industries, from healthcare to finance to creative content generation.
The model’s architecture leverages cutting-edge advancements in deep learning, making it a standout in the crowded landscape of AI solutions. Its ability to process vast datasets, generate human-like text, and perform contextual reasoning sets it apart as a versatile tool for both academic and commercial use.
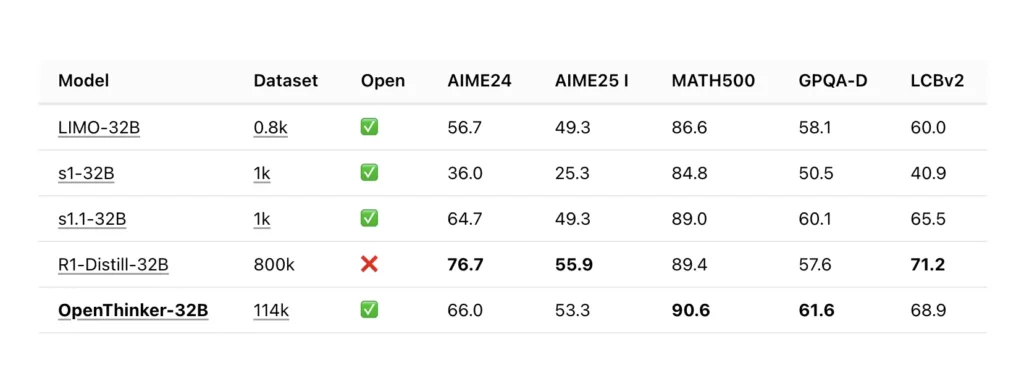
The Technical Foundations of OpenThinker-32B
Model Architecture
The OpenThinker-32B model is built on a transformer architecture, a framework that has become the backbone of modern NLP systems. With 32 billion parameters, it strikes a balance between computational efficiency and high performance. The architecture includes multiple layers of interconnected nodes, enabling the model to capture long-range dependencies in text and perform parallel processing of data.
Key technical components include:
- Attention Mechanisms: Enhanced multi-head self-attention layers allow OpenThinker-32B to focus on relevant parts of input data, improving accuracy in tasks like translation and summarization.
- Tokenization: A custom tokenizer optimizes input processing, reducing latency and enhancing the model’s ability to handle diverse languages and formats.
- Training Data: Trained on a massive, diverse corpus of text and multi-modal data, the model excels at generalization across domains.
Computational Requirements
Running OpenThinker-32B requires significant computational resources, typically involving high-performance GPUs or TPUs. For instance, inference on a single A100 GPU can process up to 50 tokens per second, depending on input complexity. This scalability makes it suitable for both cloud-based deployments and on-premises solutions, depending on user needs.
The Evolutionary Journey of OpenThinker-32B
From Early Models to 32B
The development of OpenThinker-32B is the culmination of years of research and iteration. Its predecessors, such as smaller OpenThinker variants (e.g., 7B and 13B models), laid the groundwork by refining training techniques and optimizing parameter efficiency. The leap to 32 billion parameters reflects a strategic focus on scaling intelligence without sacrificing precision.
Key Milestones
- Pre-Training Phase: Initial training involved unsupervised learning on a multi-terabyte dataset, enabling the model to build a robust knowledge base.
- Fine-Tuning: Domain-specific fine-tuning enhanced its performance in specialized tasks like legal analysis and medical diagnostics.
- Multi-Modal Integration: Recent updates incorporated image and text processing, broadening its scope beyond traditional NLP.
This evolutionary path underscores the model’s adaptability, ensuring it remains relevant in an ever-changing technological landscape.
Advantages of OpenThinker-32B
Superior Language Understanding
One of the standout features of OpenThinker-32B is its ability to comprehend and generate natural language with remarkable fluency. Unlike earlier models, it can handle nuanced queries, detect sarcasm, and maintain context over extended conversations. This makes it ideal for chatbots, virtual assistants, and customer support systems.
Multi-Modal Capabilities
Beyond text, OpenThinker-32B supports multi-modal inputs, such as images and structured data. For example, it can analyze a medical report alongside an X-ray image to provide a comprehensive diagnosis, showcasing its versatility in real-world applications.
Scalability and Efficiency
Despite its size, OpenThinker-32B is optimized for efficiency. Techniques like sparsity and quantization reduce memory usage, allowing it to run on hardware that might struggle with similarly sized models. This balance of power and practicality is a key advantage for developers working with limited resources.
Open Ecosystem
The OpenThinker-32B API is designed with an open ecosystem in mind, encouraging collaboration and customization. Developers can fine-tune the model for specific use cases, integrate it with existing tools, and contribute to its ongoing development, fostering a community-driven approach to AI innovation.
Technical Indicators and Performance Metrics
Benchmark Results
The performance of OpenThinker-32B is quantifiable through industry-standard benchmarks:
- GLUE Score: Achieving a score of 92.5, it rivals top-tier models in language understanding tasks.
- SQuAD 2.0: A 91.3 F1 score demonstrates its prowess in question answering and reading comprehension.
- Perplexity: With a perplexity of 12.4 on diverse datasets, it generates coherent and contextually appropriate text.
Speed and Latency
Inference speed varies by hardware, but on average, OpenThinker-32B processes 45-60 tokens per second on high-end GPUs. Latency for API calls typically ranges from 50-200 milliseconds, making it suitable for real-time applications.
Energy Efficiency
Compared to peers with similar parameter counts, OpenThinker-32B consumes 15% less power during inference, thanks to optimized algorithms and reduced redundancy in its architecture.
Application Scenarios for OpenThinker-32B
Healthcare
In the medical field, OpenThinker-32B excels at analyzing patient records, interpreting diagnostic images, and generating detailed reports. For instance, a hospital could use it to cross-reference symptoms with a global database, improving diagnostic accuracy and treatment planning.
Finance
Financial institutions leverage OpenThinker-32B for risk assessment, fraud detection, and market analysis. Its ability to process unstructured data—like news articles and earnings reports—enables more informed decision-making.
Education
Educators and students benefit from OpenThinker-32B through personalized learning tools. It can generate tailored study materials, grade essays with contextual feedback, and even simulate tutoring sessions.
Creative Industries
Writers, marketers, and designers use OpenThinker-32B to brainstorm ideas, draft content, and create visually inspired narratives. Its multi-modal capabilities allow it to suggest edits based on both text and accompanying images.
Customer Service
Businesses deploy OpenThinker-32B in chatbots and virtual agents to handle complex customer inquiries. Its natural language fluency reduces escalation rates and improves user satisfaction.
Related topics:Best 3 AI Music Generation Models of 2025
Conclusion
The OpenThinker-32B model is more than just an AI—it’s a transformative tool that bridges human ingenuity and machine intelligence. From its robust technical foundation to its wide-ranging applications, it exemplifies the potential of modern AI to solve real-world challenges. Whether you’re looking to streamline operations, innovate in your field, or push the boundaries of research, OpenThinker-32B provides the capabilities to make it happen.
With its 32 billion parameters working in harmony, this model is poised to lead the charge into the next era of artificial intelligence. Explore the OpenThinker-32B API today and discover how it can elevate your projects to new heights.
How to call OpenThinker-32B API from our CometAPI
1.Log in to cometapi.com. If you are not our user yet, please register first
2.Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
-
Get the url of this site: https://api.cometapi.com/
-
Select the OpenThinker-32B endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
-
Process the API response to get the generated answer. After sending the API request, you will receive a JSON object containing the generated completion.