

Zespół Qwen z Alibaby wydał Qwen3-Max-Preview (instrukcja) — największy jak dotąd model firmy, z ponad 1 bilion parametrów — i udostępniono ją natychmiast za pośrednictwem Qwen Chat, Alibaba Cloud Model Studio (API) oraz zewnętrznych platform sprzedażowych, takich jak CometAPI. Wersja zapoznawcza koncentruje się na wnioskowaniu, kodowaniu i przepływach pracy z długimi dokumentami, łącząc ekstremalną skalę z bardzo dużym oknem kontekstowym i buforowaniem kontekstu, aby utrzymać niskie opóźnienia podczas długich sesji.
Najważniejsze informacje techniczne
- Ogromna liczba parametrów (ponad biliony): Przejście na model z ponad bilionem parametrów ma na celu zwiększenie możliwości uczenia się złożonych wzorców (wnioskowanie wieloetapowe, synteza kodu, dogłębne zrozumienie dokumentów). Wczesne testy porównawcze opublikowane przez Qwen wskazują na lepsze wyniki w zakresie wnioskowania, kodowania i pakietów testowych w porównaniu z poprzednimi, wiodącymi modelami Qwen.
- Bardzo długi kontekst i buforowanie: 262k token Okno pozwala zespołom na tworzenie całych, obszernych raportów, wieloplikowych baz kodu lub długich historii czatów w jednym przebiegu. Obsługa buforowania kontekstowego zmniejsza liczbę powtarzających się obliczeń dla powtarzającego się kontekstu i może zmniejszyć opóźnienia oraz koszty długich sesji.
- Znajomość wielu języków + umiejętności kodowania: Rodzina Qwen3 kładzie nacisk na obsługę dwóch języków (chińskiego/angielskiego) i szerokie wsparcie wielojęzyczne, a także na mocniejsze kodowanie i ustrukturyzowaną obsługę wyników — co jest przydatne w przypadku asystentów kodowania, automatycznego generowania raportów i analiz tekstów na dużą skalę.
- Zaprojektowane z myślą o szybkości i jakości. Użytkownicy wersji zapoznawczej opisują „błyskawiczną” szybkość reakcji oraz lepsze śledzenie instrukcji i rozumowanie w porównaniu z poprzednimi wariantami Qwen3. Alibaba pozycjonuje ten model jako flagowy produkt o wysokiej przepustowości, przeznaczony do scenariuszy produkcyjnych, agentowych i deweloperskich.
Dostępność i dostęp
Opłaty za Alibaba Cloud wielopoziomowy, oparty na tokenach Ceny dla Qwen3-Max-Preview (osobne stawki wejściowe i wyjściowe). Rozliczenie odbywa się za milion tokenów i jest naliczane na podstawie faktycznego zużycia tokenów po wykorzystaniu dowolnego wolnego limitu.
Opublikowane ceny podglądowe Alibaby (w USD) są ustalane na podstawie żądania wkład wolumen tokenów (te same poziomy określają, jakie stawki jednostkowe mają zastosowanie):
- Tokeny wejściowe 0–32 tys.: 0.861 USD / 1 mln tokenów wejściowych oraz 3.441 1 USD / XNUMX mln tokenów wyjściowych.
- Tokeny wejściowe 32 tys.–128 tys.: 1.434 USD / 1 mln tokenów wejściowych oraz 5.735 1 USD / XNUMX mln tokenów wyjściowych.
- Tokeny wejściowe 128 tys.–252 tys.: 2.151 USD / 1 mln tokenów wejściowych oraz 8.602 1 USD / XNUMX mln tokenów wyjściowych.
CometAPI zapewnia oficjalną zniżkę w wysokości 20%, aby ułatwić użytkownikom korzystanie z API. Szczegóły można znaleźć tutaj Podgląd Qwen3-Max:
| Tokeny wejściowe | $0.24 |
| Tokeny wyjściowe | $2.42 |
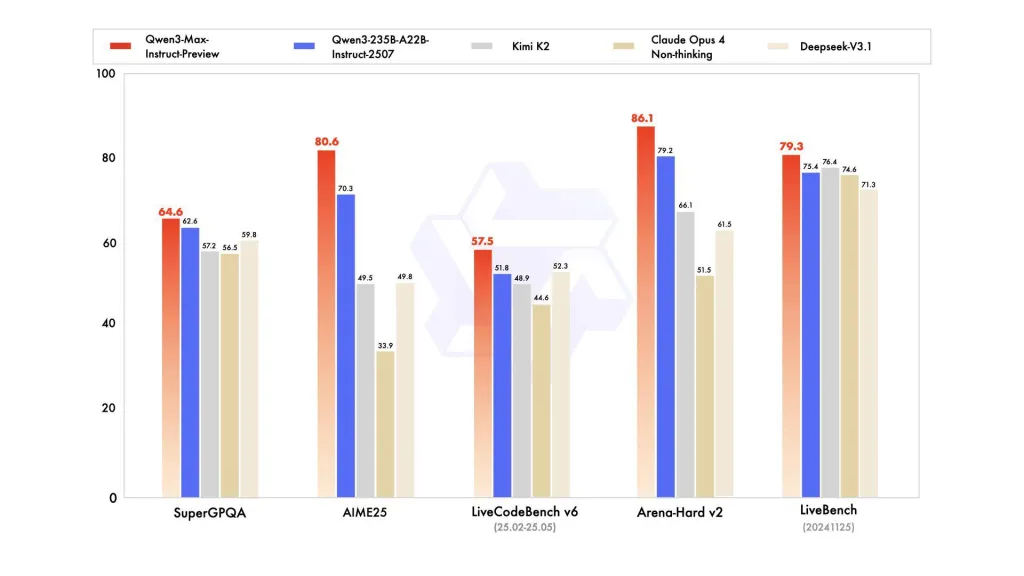
Qwen3-Max rozszerza rodzinę Qwen3 (która w poprzednich wersjach wykorzystywała rozwiązania hybrydowe, takie jak warianty Mixture-of-Experts i wiele poziomów aktywnych parametrów). Wcześniejsze wersje Qwen3 firmy Alibaba koncentrowały się zarówno na trybie „myślenia” (rozumowania krok po kroku), jak i „instruowania”; Qwen3-Max jest pozycjonowany jako nowy, topowy wariant instruowania w tej linii, co dowodzi, że przewyższa poprzedni, najlepiej działający produkt firmy, Qwen3-235B-A22B-2507, pokazując, że model 1T parametrów jest liderem w zakresie testów.
W testach SuperGPQA, AIME25, LiveCodeBench v6, Arena-Hard v2 i LiveBench (20241125) Qwen3-Max-Preview konsekwentnie wyprzedza Claude Opus 4, Kimi K2 i Deepseek-V3.1.
Jak uzyskać dostęp i korzystać z Qwen3-Max (przewodnik praktyczny)
1) Wypróbuj w przeglądarce (Qwen Chat)
Odwiedź Czat Qwen (oficjalny interfejs internetowy/czatu Qwen) i wybierz Podgląd Qwen3-Max Model (instrukcyjny), jeśli jest wyświetlany w selektorze modeli. To najszybszy sposób wizualnej oceny zadań konwersacyjnych i instruktażowych.
2) Dostęp przez Alibaba Cloud (Model Studio / Cloud API)
- Zaloguj się do Alibaba Cloud → Studio Modelowe / Obsługa Modeli. Utwórz instancję wnioskowania lub wybierz punkt końcowy hostowanego modelu qwen3-max-preview (lub oznaczona wersja podglądowa).
- Uwierzytelnij się, używając klucza dostępu do chmury Alibaba Cloud / ról RAM i wywołaj punkt końcowy wnioskowania za pomocą żądania POST zawierającego monit i wszelkie parametry generacji (temperaturę, maksymalną liczbę tokenów itp.).
3) Użyj przez zewnętrzni hostowie/agregatorzy
Według źródeł, podgląd jest dostępny za pośrednictwem CometAPI i innych agregatorów API, które umożliwiają programistom wywoływanie wielu hostowanych modeli za pomocą jednego klucza API. Może to uprościć testowanie u różnych dostawców, ale pozwala również zweryfikować opóźnienia, dostępność regionalną i zasady przetwarzania danych dla każdego hosta.
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Podsumowanie
Wersja zapoznawcza Qwen3-Max-Preview plasuje Alibabę w gronie organizacji oferujących klientom modele o skali bilionów. Połączenie ekstremalnie długiego kontekstu i interfejsu API zgodnego z OpenAI obniża barierę integracji dla przedsiębiorstw, które potrzebują wnioskowania na podstawie długich dokumentów, automatyzacji kodu lub koordynacji agentów. Koszt i stabilność wersji zapoznawczej to główne czynniki wpływające na wdrożenie: organizacje będą chciały przeprowadzić pilotaż z buforowaniem, strumieniowaniem i wywołaniami wsadowymi, aby zarządzać zarówno opóźnieniami, jak i cenami.