

Seria Claude firmy Anthropic stała się kamieniem węgielnym w dynamicznie ewoluującym krajobrazie dużych modeli językowych, szczególnie dla przedsiębiorstw i deweloperów poszukujących najnowocześniejszych możliwości sztucznej inteligencji. Wraz z premierą Claude Opus 4.1, 5 sierpnia 2025 roku, Anthropic oferuje stopniową, ale znaczącą aktualizację w stosunku do swojego poprzednika, Claude Opus 4 (wydanego 22 maja 2025 roku). W niniejszym artykule omówiono kluczowe różnice między Opus 4.1 a Opus 4.0 w zakresie wydajności, architektury, bezpieczeństwa i praktycznego zastosowania, opierając się na oficjalnych zapowiedziach, niezależnych testach porównawczych i opiniach branżowych.
Claude Opus 4.1 jest już dostępny za pośrednictwem API (identyfikator modelu claude-opus-4-1-20250805), Amazon Bedrock, Google Cloud Vertex AI oraz w płatnych interfejsach Claude. Jako aktualizacja przyrostowa, zachowuje pełną wsteczną kompatybilność z Opus 4 – te same ceny, punkty końcowe i wszystkie istniejące integracje nadal działają bez zmian.
Czym jest Claude Opus 4.0 i dlaczego jest to ważne?
Claude Opus 4.0 stanowił znaczący krok naprzód w dążeniu firmy Anthropic do osiągnięcia „inteligencji pionierskiej”, łącząc solidne rozumowanie, obsługę rozszerzonego kontekstu i wysokie kompetencje w zakresie kodowania w jednym modelu. Osiągnął on następujące rezultaty:
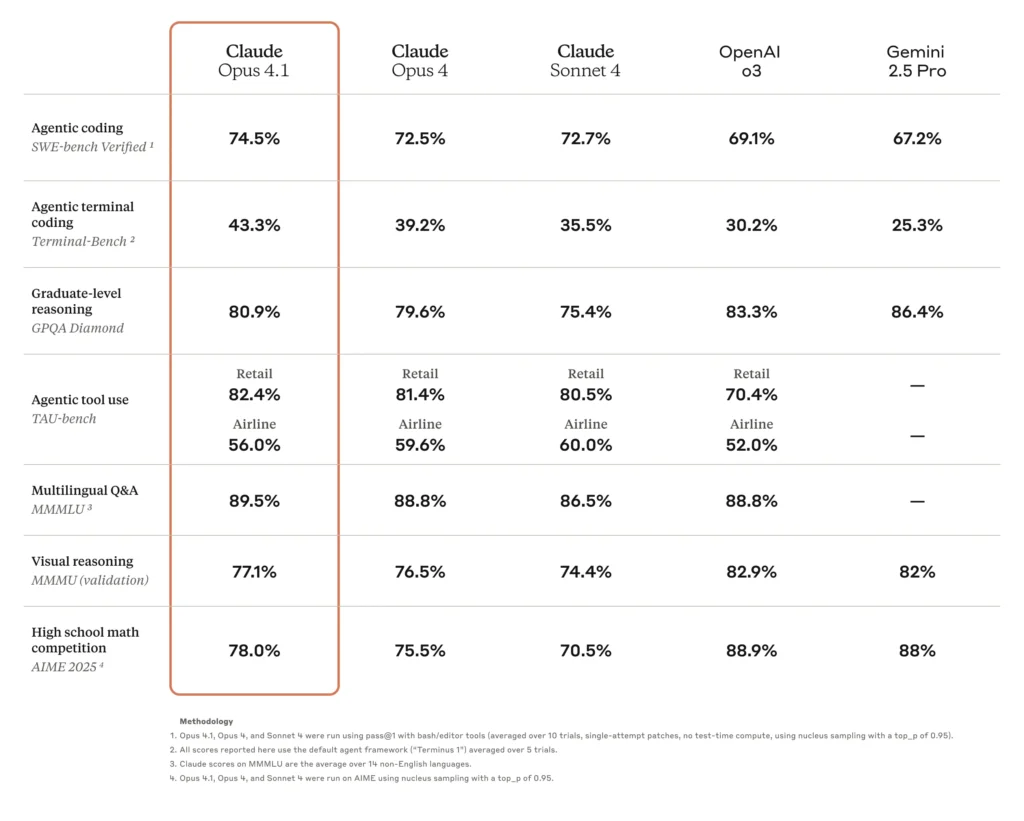
- Wysoka dokładność kodowania:Opus 4.0 uzyskał wynik 72.5% w teście SWE-bench Verified, stanowiącym punkt odniesienia dla rzeczywistych wyzwań programistycznych, co potwierdza jego znaczącą przydatność w rzeczywistych zadaniach związanych z tworzeniem oprogramowania.
- Zaawansowane możliwości agentaModel ten znakomicie sprawdził się w wieloetapowym, autonomicznym wykonywaniu zadań, umożliwiając zaawansowanym agentom AI zarządzanie przepływami pracy – od koordynacji działań marketingowych po pomoc w badaniach.
- Kreatywność i zdolności analityczne:Oprócz kodowania Opus 4.0 oferuje najnowocześniejszą wydajność w zakresie kreatywnego pisania, analizy danych i złożonego rozumowania, dzięki czemu jest wszechstronnym narzędziem do współpracy zarówno w obszarze biznesu, jak i techniki.
Połączenie szerokości i głębi rozwiązania Opus 4.0 wyznaczyło nowy standard dla sztucznej inteligencji w przedsiębiorstwach, co doprowadziło do szybkiego wdrożenia w planach Claude Pro, Max, Team i Enterprise, a także integracji z Amazon Bedrock i Vertex AI firmy Google Cloud.
Co nowego w Claude Opus 4.1?
Ulepszenia testów porównawczych w zadaniach kodowania
Jedną z głównych nowości w Opus 4.1 jest zwiększona dokładność kodowania. W teście SWE-bench Verified, Opus 4.1 uzyskał **74.5%**w porównaniu z 4.0% w Opus 72.5. Ten 2-punktowy wzrost, choć pozornie skromny, przekłada się na znaczące skrócenie cykli debugowania i większą precyzję syntezy kodu i refaktoryzacji.
W jaki sposób zadania agentowe są bardziej niezawodne?
Opus 4.1 oferuje silniejsze możliwości wnioskowania długoterminowego, umożliwiając agentom AI obsługę złożonych, wieloetapowych procesów z większą spójnością. Według AWS, model ten służy obecnie jako „idealny wirtualny współpracownik” do zadań wymagających rozbudowanych łańcuchów myślowych, takich jak autonomiczne zarządzanie kampaniami i międzyfunkcyjna orkiestracja przepływów pracy.
Precyzja refaktoryzacji wieloplikowej
Cechą wyróżniającą Opus 4.1 jest konserwatywne podejście do zmian w kodzie na dużą skalę. Podczas gdy Opus 4.0 czasami wprowadzał niepotrzebne zmiany w połączonych plikach, Opus 4.1 doskonale radzi sobie z izolowaniem minimalnych, wymaganych korekt – wskazując dokładne poprawki bez dodatkowych modyfikacji.
Jak wypadają w kluczowych testach porównawczych?
Testy kodowania
| Model | Zweryfikowano na SWE-bench (%) | Wynik refaktoryzacji wielu plików |
|---|---|---|
| Opus 4.0 | 72.5 | Baseline |
| Opus 4.1 | 74.5 | +1.2 σ zysku |
Źródło: Karta systemu antropicznego i niezależne testy porównawcze
Poszukiwanie i badania agentów
Opus 4.1 pokazuje 15% Poprawa w zakresie ocen agentów w ramach TAU, odzwierciedlająca lepsze zapamiętywanie kontekstu i inicjatywę w zadaniach badawczych. Użytkownicy zgłaszają szybszą konwergencję istotnych informacji i bardziej spójne podsumowania obejmujące wiele dokumentów.
Porównania benchmarków dla zadań „wyszukiwania agentowego” pokazują, że Opus 4.1 osiąga wyższe wyniki w planowaniu, korzystaniu z narzędzi i dynamicznym rozwiązywaniu problemów. Wewnętrzna ocena badań agentowych firmy Anthropic wskazuje na 5–7% poprawę dokładności rozumowania wieloetapowego w porównaniu z Opus 4.0, co umożliwia bardziej niezawodne wykonywanie przepływów pracy, takich jak zautomatyzowane potoki analizy danych i generowanie raportów badawczych. Te postępy wynikają częściowo z ulepszonej możliwości śledzenia rozumowania pośredniego, funkcji, która zapewnia użytkownikom końcowym lepszy wgląd w ścieżki decyzyjne modelu.
Które konkretne zadania związane z kodowaniem przynoszą największe korzyści?
- Refaktoryzacja wielu plików:Opus 4.1 charakteryzuje się zwiększoną spójnością podczas przechodzenia między współzależnymi modułami, zmniejszając liczbę błędów międzyplikowych o ponad 15% w testach wewnętrznych.
- Lokalizacja i naprawa błędów:Model ten niezawodniej identyfikuje główną przyczynę niepowodzeń przypadków testowych, skracając średni czas rozwiązania problemu o 25%.
- Generowanie dokumentacji:Usprawniona płynność języka naturalnego obsługuje bardziej obszerne i kontekstowe dokumenty API oraz komentarze wbudowane.
Jak Opus 4.1 radzi sobie z zadaniami wieloetapowymi?
- Ulepszona heurystyka planowania, zmniejszając liczbę błędów w planowaniu w 10-etapowych łańcuchach zadań o 8%.
- Ulepszona integracja z wykorzystaniem narzędzi, umożliwiając bardziej precyzyjne wywołania API z mniejszą liczbą błędów formatowania.
- Podpowiedzi do rozumowania tymczasowegodając deweloperom możliwość weryfikacji i dostosowywania wewnętrznego rozumowania modelu w regulowanych „punktach kontrolnych”.
Wskaźniki zgodności instrukcji
Ewaluacje jednokrotne pokazują, że Opus 4.1 osiągnął 98.76% wskaźnik odpowiedzi bez ryzyka na żądania naruszające zasady – w porównaniu z 97.27% w Opus 4.0 – co wskazuje na silniejsze odrzucanie zabronionych treści (). Wskaźniki nadmiernej liczby odrzuceń w przypadku łagodnych zapytań pozostają porównywalnie niskie (0.08% w porównaniu z 0.05%), co zapewnia, że model utrzymuje responsywność w odpowiednich momentach.
Jakie udoskonalenia w zakresie bezpieczeństwa i ustawienia kół są wprowadzone?
Ulepszenia oceny jednoobrotowej
Skrócone audyty bezpieczeństwa przeprowadzone przez Anthropic dla Opus 4.1 potwierdziły spójną lub lepszą wydajność w zakresie bezpieczeństwa dzieci, uprzedzeń i zgodności. Na przykład, wskaźniki nieszkodliwych reakcji w przypadku rozszerzonego myślenia wzrosły z 97.67% do 99.06%.
Błąd i solidność
W teście BBQ, wynik testu stronniczości dla Opus 4.1 wynosi –0.51 w porównaniu z –0.60 dla Opus 4.0, przy czym dokładność utrzymuje się na poziomie powyżej 90% dla zapytań jednoznacznych i niemalże idealnym dla zapytań niejednoznacznych. Te niewielkie zmiany wskazują na utrzymanie neutralności i wysoką wierność w kontekstach wrażliwych.
Na czym polegają ulepszenia architektoniczne?
Strojenie modelu i aktualizacje danych
Zespół Anthropic wdrożył udoskonalone protokoły dostrajania, skupiające się na:
- Rozszerzone korpusy kodu:Wprowadzanie większej liczby adnotowanych repozytoriów wieloplikowych.
- Rozszerzone scenariusze agentowe:W trakcie szkolenia należy tworzyć dłuższe łańcuchy zadań w celu wspomagania rozumowania długoterminowego.
- Ulepszone pętle sprzężenia zwrotnego między ludźmi:Wykorzystanie ukierunkowanego uczenia wzmacniającego na podstawie ludzkiej informacji zwrotnej (RLHF) w przypadku skrajnych podpowiedzi w celu złagodzenia halucynacji.
Te zmiany przynoszą wymierne korzyści bez zmiany podstawowej architektury Transformera, gwarantując pełną zgodność z istniejącymi interfejsami API Anthropic.
Infrastruktura i opóźnienia
Choć surowe opóźnienie wnioskowania pozostaje porównywalne z Opus 4.0, Anthropic zoptymalizował swoją infrastrukturę obsługi, aby skrócić czas zimnego startu poprzez 12%, zwiększając responsywność aplikacji interaktywnych, takich jak integracje Claude Chat i Copilot.
Jakie to ma konsekwencje dla deweloperów i przedsiębiorstw?
Ceny i dostępność
Claude Opus 4.1 jest oferowany w ta sama cena Opus 4.0 we wszystkich kanałach (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Aktualizacja nie wymaga żadnych zmian w kodzie — użytkownicy po prostu wybierają „Opus 4.1” w selektorze modeli.
Rozszerzenie przypadku użycia
- Inżynieria oprogramowania:Szybsze debugowanie, dokładniejsze generowanie testów, ulepszona integracja procesu CI/CD.
- AI agenci:Bardziej niezawodne, autonomiczne przepływy pracy w marketingu, finansach i badaniach.
- Wywiad przedsiębiorstwa:Ulepszone podsumowania, generowanie raportów i dogłębne analizy umożliwiające podejmowanie decyzji na podstawie danych.
Ulepszenia te przekładają się na mniejsze nakłady pracy związane z rozwojem i wyższy zwrot z inwestycji w przypadku inicjatyw opartych na sztucznej inteligencji.
Co dalej z Claude Opus?
Anthropic sygnalizuje, że Opus 4.1 to tylko jeden z kroków na szerszej mapie drogowej. Zespół zapowiada „znacznie większe ulepszenia” w nadchodzących wersjach, prawdopodobnie ukierunkowane na:
- Jeszcze dłuższe okna kontekstowe (powyżej 200 tys. tokenów).
- Możliwości multimodalne do zintegrowanego rozumienia obrazu, dźwięku i kodu.
- Większa interpretowalność narzędzia do śledzenia ścieżek decyzyjnych podczas działań agentów.
Przedsiębiorstwa i deweloperzy powinni monitorować kanały Anthropic w poszukiwaniu aktualizacji, ponieważ każda stopniowa aktualizacja umacnia pozycję Claude’a wśród najwydajniejszych i najbezpieczniejszych asystentów AI dostępnych na rynku.
Jak zacząć
Interfejs API Comet jest ujednoliconą platformą API, która łączy ponad 500 modeli sztucznej inteligencji od wiodących dostawców.Dostęp do Claude Opus 4.1 jest możliwy poprzez CometAPI. Listy CometAPI anthropic/claude-opus-4.1 wśród obsługiwanych modeli, dzięki czemu można kierować do niego żądania za pomocą API CometAPI, dostępne są również modele przeznaczone specjalnie dla kodu kursora.
Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Claude Opus 4.1 aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API.
Adres URL bazowy: https://api.cometapi.com/v1/chat/completions
Parametr modelu:
"claude-opus-4-1-20250805"→ standardowy Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 z włączonym rozszerzonym rozumowaniemcometapi-opus-4-1-20250805→Ekskluzywna wersja CometAPI. Wersja standardowa zaprojektowana specjalnie dla kursor integracjacometapi-opus-4-1-20250805-thinking→ Wyłącznie dla CometAPI. Rozszerzona wersja wnioskowania specjalnie dla kursor integracja
PodsumowującClaude Opus 4.1 bazuje na mocnych stronach Opus 4.0, oferując ukierunkowane ulepszenia w zakresie dokładności kodowania, wnioskowania agentowego i wydajności infrastruktury – bez generowania kosztów ani zmiany ścieżek integracji. Niezależnie od tego, czy udoskonalasz złożone bazy kodu, koordynujesz autonomiczne przepływy pracy agentów, czy generujesz wysokiej jakości analizy biznesowe, Opus 4.1 oferuje atrakcyjną aktualizację, która równoważy precyzję i wszechstronność. Wraz z ciągłym przyspieszeniem środowiska sztucznej inteligencji, stały rytm ulepszeń Anthropic sprawia, że Claude Opus staje się idealnym wyborem dla organizacji, które chcą wykorzystać możliwości najnowocześniejszych modeli językowych.