

W ciągu ostatnich kilku miesięcy nastąpił gwałtowny rozwój kodowania agentowego: specjalistycznych modeli, które nie tylko odpowiadają na jednorazowe pytania, ale planują, edytują, testują i iterują w całych repozytoriach. Dwoma z najbardziej znanych debiutantów są Komponować, specjalnie zaprojektowany model kodowania o niskim opóźnieniu wprowadzony przez Cursor wraz z wydaniem Cursor 2.0, oraz Kodeks GPT-5Zoptymalizowana pod kątem agentów wersja GPT-5 firmy OpenAI, dostosowana do stabilnych przepływów pracy w zakresie kodowania. Razem ilustrują one nowe linie podziału w narzędziach programistycznych: szybkość kontra głębokość, świadomość lokalnego obszaru roboczego kontra rozumowanie ogólne oraz wygoda kodowania „vibe” kontra rygor inżynierski.
W skrócie: różnice bezpośrednie
- Zamysł projektowy: GPT-5-Codex — dogłębne, agentowe rozumowanie i solidność w przypadku długich, złożonych sesji; Composer — dynamiczna iteracja uwzględniająca środowisko robocze, zoptymalizowana pod kątem szybkości.
- Podstawowa powierzchnia integracji: GPT-5-Codex — produkt Codex/API odpowiedzi, środowiska IDE, integracje korporacyjne; Composer — edytor kursora i wieloagentowy interfejs użytkownika Cursora.
- Opóźnienie/iteracja: Composer kładzie nacisk na zwroty w czasie poniżej 30 sekund i twierdzi, że ma przewagę pod względem szybkości; GPT-5-Codex stawia na dokładność i wielogodzinne autonomiczne przejazdy, gdy jest to wymagane.
Testowałem API GPT-5-Codex model dostarczony przez Interfejs API Comet (zewnętrzny dostawca agregacji API, którego ceny za API są zazwyczaj niższe niż oficjalne), podsumował moje doświadczenia z wykorzystaniem modelu Composer Cursor 2.0 i porównał oba rozwiązania w różnych wymiarach oceny generowania kodu.
Czym jest Composer i GPT-5-Codex
Czym jest Kodeks GPT-5 i jakie problemy ma on na celu rozwiązać?
GPT-5-Codex firmy OpenAI to specjalistyczna migawka GPT-5, która według OpenAI jest zoptymalizowana pod kątem scenariuszy kodowania agentowego: uruchamiania testów, edycji kodu na skalę repozytorium oraz autonomicznej iteracji aż do pomyślnego zakończenia kontroli. Nacisk kładziony jest na szerokie możliwości w wielu zadaniach inżynierskich – dogłębne wnioskowanie w przypadku złożonych refaktoryzacji, „agentowe” działanie w dłuższym horyzoncie czasowym (gdzie model może poświęcić minuty lub godziny na wnioskowanie i testowanie) oraz lepszą wydajność w standardowych testach porównawczych, zaprojektowanych tak, aby odzwierciedlały rzeczywiste problemy inżynieryjne.
Czym jest Composer i jakie problemy ma on na celu rozwiązać?
Composer to pierwszy natywny model kodowania firmy Cursor, wprowadzony wraz z Cursor 2.0. Cursor opisuje Composera jako pionierski, zorientowany na agentów model, stworzony z myślą o niskich opóźnieniach i szybkiej iteracji w ramach przepływów pracy programistów: planowaniu różnic między plikami, stosowaniu semantycznego wyszukiwania w całym repozytorium i wykonywaniu większości operacji w czasie krótszym niż 30 sekund. Composer został wytrenowany z wykorzystaniem pętli dostępu do narzędzi (wyszukiwanie, edycja, testy), aby efektywnie wykonywać praktyczne zadania inżynierskie i minimalizować tarcie wynikające z powtarzających się cykli monit-odpowiedź w codziennym kodowaniu. Cursor pozycjonuje Composera jako model zoptymalizowany pod kątem szybkości pracy programistów i pętli sprzężenia zwrotnego w czasie rzeczywistym.
Zakres modelu i zachowanie w czasie wykonywania
- Kompozytor: Zoptymalizowany pod kątem szybkich interakcji z edytorem i spójności wielu plików. Integracja Cursora na poziomie platformy umożliwia Composerowi wgląd w większą część repozytorium i udział w koordynacji wielu agentów (np. dwóch agentów Composer vs. innych), co zdaniem Cursora zmniejsza liczbę pominiętych zależności między plikami.
- Kodeks GPT-5: Zoptymalizowany pod kątem głębszego, zmiennej długości wnioskowania. OpenAI reklamuje zdolność modelu do zamiany obliczeń/czasu na głębsze wnioskowanie, gdy jest to konieczne – według doniesień, od sekund dla lekkich zadań do godzin dla rozbudowanych, autonomicznych uruchomień – umożliwiając bardziej dogłębne refaktoryzacje i debugowanie sterowane testami.
Wersja skrócona: Composer = model kodowania Cursor w środowisku IDE, uwzględniający przestrzeń roboczą; GPT-5-Codex = specjalistyczna odmiana GPT-5 firmy OpenAI przeznaczona do inżynierii oprogramowania, dostępna w Responses/Codex.
Jak wypadają w porównaniu szybkości Composera i GPT-5-Codex?
Co twierdzili sprzedawcy?
Cursor pozycjonuje Composera jako „szybkiego” programistę kodującego: opublikowane dane wskazują na przepustowość generowania mierzoną w tokenach na sekundę i deklarują 2–4 razy szybszy czas ukończenia kodu w trybie interaktywnym w porównaniu z modelami „pionierskimi” w wewnętrznym systemie Cursora. Niezależne źródła (prasa i wcześni testerzy) donoszą, że Composer generuje kod z prędkością ~200–250 tokenów na sekundę w środowisku Cursora i w wielu przypadkach wykonuje typowe tury kodowania interaktywnego w czasie poniżej 30 sekund.
GPT-5-Codex firmy OpenAI nie jest eksperymentem w zakresie opóźnień; priorytetowo traktuje solidność i głębsze rozumowanie, a przy porównywalnych obciążeniach wymagających intensywnego rozumowania może działać wolniej, gdy jest używany przy większych rozmiarach kontekstu, zgodnie z raportami społeczności i wątkami problemów.
Jak przeprowadziliśmy test porównawczy prędkości (metodologia)
Aby przeprowadzić rzetelne porównanie prędkości, należy kontrolować typ zadania (krótkie zakończenia kontra długie rozumowanie), środowisko (opóźnienie sieciowe, integracja lokalna kontra integracja w chmurze) i mierzyć oba te czynniki czas do pierwszego użytecznego wyniku oraz zegar ścienny typu end-to-end (w tym wszelkie wykonywanie testów i kroki kompilacji). Kluczowe punkty:
- Wybrane zadania — generowanie małych fragmentów kodu (implementacja punktu końcowego API), średnie zadanie (refaktoryzacja jednego pliku i aktualizacja importów), duże zadanie (implementacja funkcji w trzech plikach, aktualizacja testów).
- Metryka — czas do pierwszego tokena, czas do pierwszej użytecznej różnicy (czas do wyemitowania łatki kandydującej) i całkowity czas obejmujący wykonanie testu i weryfikację.
- Powtórzenia — każde zadanie uruchamiane 10 razy, mediana używana do redukcji szumów sieciowych.
- Środowisko — pomiary wykonano na komputerze dewelopera w Tokio (aby odzwierciedlić rzeczywiste opóźnienia) przy stabilnym łączu 100/10 Mb/s; wyniki mogą się różnić w zależności od regionu.
Poniżej znajduje się reprodukcja uprząż prędkości dla GPT-5-Codex (API odpowiedzi) i opis sposobu pomiaru Composera (wewnątrz kursora).
Uprząż prędkości (Node.js) — GPT-5-Codex (API odpowiedzi):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
Pomiar całkowitego opóźnienia żądania dla GPT-5-Codex odbywa się przy użyciu publicznego interfejsu API odpowiedzi (dokumentacja OpenAI opisuje użycie interfejsu API odpowiedzi i modelu gpt-5-codex).
Jak zmierzyć prędkość kompozytora (kursora):
Composer działa w ramach Cursora 2.0 (fork na komputery stacjonarne/VS Code). Cursor (w chwili pisania tego tekstu) nie zapewnia ogólnego zewnętrznego interfejsu API HTTP dla Composera, który byłby zgodny z interfejsem API odpowiedzi OpenAI; siłą Composera jest integracja w środowisku IDE ze stanowym obszarem roboczymDlatego mierz Composera tak, jak zrobiłby to człowiek-programista:
- Otwórz ten sam projekt w Cursor 2.0.
- Użyj Composera do uruchomienia tego samego monitu, co zadanie agenta (utworzenie trasy, refaktoryzacja, zmiana wielu plików).
- Uruchom stoper w momencie przesłania planu Composera; zatrzymaj go, gdy Composer wyemituje różnicę atomową i uruchomi zestaw testów (interfejs Cursora może uruchamiać testy i wyświetlać skonsolidowaną różnicę).
- Powtórz 10 razy i użyj mediany.
Opublikowane materiały i recenzje Cursora pokazują, że w praktyce Composer wykonuje wiele typowych zadań w czasie krótszym niż ~30 sekund; jest to interaktywny cel opóźnienia, a nie czas wnioskowania o surowym modelu.
Na wynos: Celem projektu Composera jest szybka, interaktywna edycja w edytorze; jeśli priorytetem są pętle kodowania konwersacyjnego o niskim opóźnieniu, Composer jest stworzony właśnie do tego celu. GPT-5-Codex jest zoptymalizowany pod kątem poprawności i wnioskowania agentowego w dłuższych sesjach; może on zastąpić nieco większe opóźnienie w celu głębszego planowania. Liczba dostawców potwierdza to pozycjonowanie.
Jak wypadają w porównaniu dokładności Composera i GPT-5-Codex?
Co oznacza dokładność w kodowaniu sztucznej inteligencji
Dokładność jest tutaj wieloaspektowa: poprawność funkcjonalna (czy kod się kompiluje i przechodzi testy), poprawność semantyczna (czy zachowanie spełnia specyfikację) i krzepkość (zajmuje się przypadkami brzegowymi, kwestiami bezpieczeństwa).
Numery dostawców i prasy
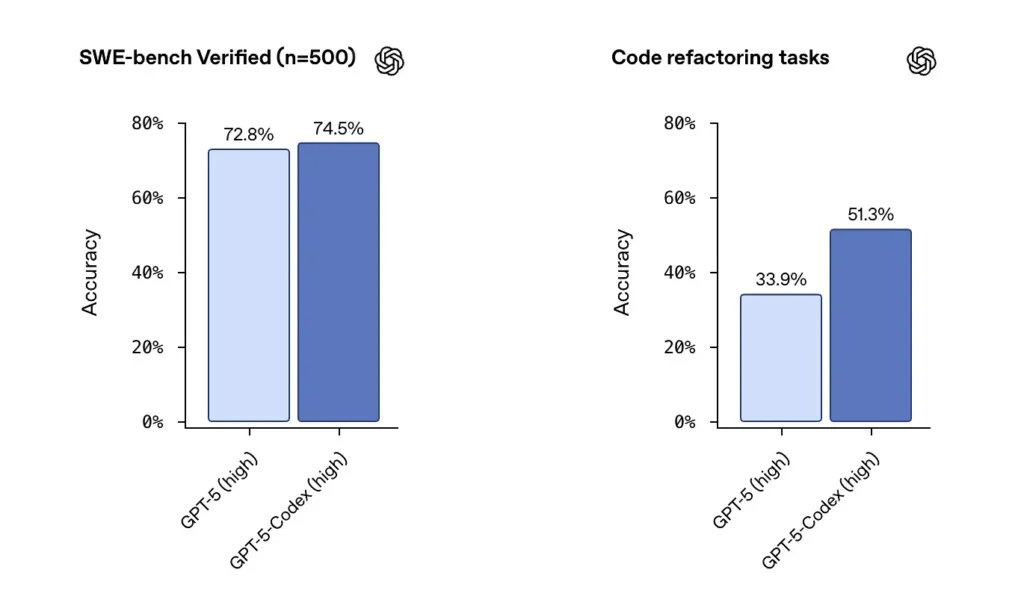
OpenAI informuje o wysokiej wydajności GPT-5-Codex w zestawach danych zweryfikowanych przez SWE i podkreśla 74.5% wskaźnik sukcesu w rzeczywistym teście kodowania (o którym informowały media) i zauważalny wzrost powodzenia refaktoryzacji (51.3% w porównaniu z 33.9% dla podstawowego GPT-5 w wewnętrznym teście refaktoryzacji).
Wydanie Cursora wskazuje, że Composer często sprawdza się w edycjach wieloplikowych, zależnych od kontekstu, gdzie integracja edytora i widoczność repozytoriów mają znaczenie. Po moich testach Composer generował mniej błędów pominiętych zależności podczas refaktoryzacji wieloplikowych i uzyskał lepsze wyniki w testach ślepej recenzji dla niektórych obciążeń wieloplikowych. Funkcje Composera związane z opóźnieniami i obsługą agentów równoległych również pomagają mi przyspieszyć iteracje.
Niezależne testowanie dokładności (zalecana metoda)
Sprawiedliwy test opiera się na połączeniu:
- Testy jednostkowe: przekaż to samo repozytorium i zestaw testów do obu modeli, wygeneruj kod, uruchom testy.
- Refaktoryzacja testów:dostarcz celowo chaotyczną funkcję i poproś model o refaktoryzację i dodanie testów.
- Kontrole bezpieczeństwa:uruchom analizę statyczną i narzędzia SAST na wygenerowanym kodzie (np. Bandit, ESLint, semgrep).
- Przegląd ludzki:oceny przeglądu kodu przez doświadczonych inżynierów pod kątem łatwości konserwacji i najlepszych praktyk.
Przykład: zautomatyzowane testy (Python) — uruchamianie wygenerowanego kodu i testów jednostkowych
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
Użyj tego wzorca, aby automatycznie sprawdzić, czy dane wyjściowe modelu są poprawne funkcjonalnie (przechodzą testy). W przypadku zadań refaktoryzacji uruchom narzędzie Harvest na oryginalnym repozytorium oraz na różnicach modelu i porównaj wskaźniki zdawalności testów oraz zmiany pokrycia.
Na wynos: W surowych testach porównawczych, GPT-5-Codex wykazuje doskonałe wyniki i wysoką sprawność refaktoryzacji. W rzeczywistych procesach naprawy i edycji wielu plików, świadomość przestrzeni roboczej Composera może zapewnić wyższą akceptację praktyczną i mniej błędów „mechanicznych” (brakujące importy, błędne nazwy plików). GPT-5-Codex jest mocnym kandydatem do uzyskania maksymalnej poprawności funkcjonalnej w zadaniach algorytmicznych na pojedynczych plikach; w przypadku wieloplikowych, wrażliwych na konwencje zmian w środowisku IDE, Composer często błyszczy.
Composer kontra GPT-5: Jak wypadają pod względem jakości kodu?
Co uznajemy za jakość?
Jakość obejmuje czytelność, nazewnictwo, dokumentację, pokrycie testami, stosowanie wzorców idiomatycznych i higienę bezpieczeństwa. Jest mierzona zarówno automatycznie (lintery, wskaźniki złożoności), jak i jakościowo (weryfikacja przez człowieka).
Zaobserwowane różnice
- Kodeks GPT-5: doskonale radzi sobie z tworzeniem idiomatycznych wzorców na wyraźne żądanie; wyróżnia się jasnością algorytmów i potrafi tworzyć kompleksowe zestawy testów na żądanie. Narzędzia Codex firmy OpenAI obejmują zintegrowane dzienniki testów/raportowania i wykonywania.
- Komponować: zoptymalizowany pod kątem automatycznego obserwowania stylu i konwencji repozytorium; Composer może śledzić istniejące wzorce projektu i koordynować aktualizacje wielu plików (zmiana nazwy/refaktoryzacja, propagacja, importowanie aktualizacji). Oferuje doskonałą łatwość utrzymania na żądanie w przypadku dużych projektów.
Przykładowe kontrole jakości kodu, które możesz uruchomić
- Linters — ESLint / pylint
- Złożoność — radon / flake8-complexity
- Ochrona — semgrep / Bandyta
- Pokrycie testowe — uruchom coverage.py lub vitest/nyc dla JS
Zautomatyzuj te kontrole po zastosowaniu poprawki modelu, aby określić ilościowo poprawę lub regresję. Przykładowa sekwencja poleceń (repozytorium JS):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
Recenzja ludzka i najlepsze praktyki
W praktyce modele wymagają instrukcji, aby przestrzegać najlepszych praktyk: żądać docstringów, adnotacji typów, przypinania zależności lub określonych wzorców (np. async/await). GPT-5-Codex sprawdza się doskonale, gdy ma jawne dyrektywy; Composer korzysta z niejawnego kontekstu repozytorium. Zastosuj podejście łączone: jawnie wydaj instrukcje modelowi i pozwól Composerowi wymusić styl projektu, jeśli znajdujesz się w Cursor.
Zalecenie: Do pracy inżynieryjnej na wielu plikach w środowisku IDE najlepiej nadaje się Composer; w przypadku zewnętrznych potoków, zadań badawczych lub automatyzacji łańcucha narzędzi, gdzie można wywołać interfejs API i dostarczyć duży kontekst, dobrym wyborem będzie GPT-5-Codex.
Integracje i opcje wdrażania
Composer jest dostarczany jako część Cursor 2.0, osadzony w edytorze i interfejsie użytkownika Cursor. Podejście Cursor kładzie nacisk na pojedynczą płaszczyznę sterowania dostawcy, która uruchamia Composer równolegle z innymi modelami — umożliwiając użytkownikom uruchamianie wielu instancji modelu w tym samym wierszu poleceń i porównywanie wyników w edytorze. ()
GPT-5-Codex jest wdrażany w ofercie Codex firmy OpenAI oraz rodzinie produktów ChatGPT, a dostępność w ramach płatnych pakietów ChatGPT i API sprawia, że platformy zewnętrzne, takie jak CometAPI, oferują lepszy stosunek jakości do ceny. OpenAI integruje również Codex z narzędziami dla programistów i procesami pracy partnerów chmurowych (na przykład integracje Visual Studio Code/GitHub Copilot).
W jakim kierunku Composer i GPT-5-Codex mogą posunąć branżę?
Efekty krótkoterminowe
- Szybsze cykle iteracji: Modele osadzone w edytorze, takie jak Composer, redukują tarcia przy drobnych poprawkach i generowaniu PR.
- Rosnące oczekiwania dotyczące weryfikacji: Nacisk, jaki Codex kładzie na testy, logi i możliwości autonomiczne, zmusi dostawców do zapewnienia skuteczniejszej weryfikacji kodu generowanego przez model już od samego początku.
Średnio- i długoterminowo
- Orkiestracja wielomodelowa staje się normą: Wieloagentowy interfejs graficzny Cursora to wczesna wskazówka, że inżynierowie wkrótce będą oczekiwać równoległego uruchamiania kilku wyspecjalizowanych agentów (linting, bezpieczeństwo, refaktoryzacja, optymalizacja wydajności) i akceptowania najlepszych wyników.
- Bardziej ścisłe pętle sprzężenia zwrotnego CI/AI: W miarę doskonalenia modeli procesy ciągłej integracji (CI) będą coraz częściej uwzględniać generowanie testów sterowanych przez model oraz automatyczne sugestie napraw — kluczowe pozostają jednak przegląd ręczny i etapowe wdrażanie.
Podsumowanie
Composer i GPT-5-Codex to nie to samo narzędzie w tym samym wyścigu zbrojeń; to komplementarne narzędzia zoptymalizowane pod kątem różnych etapów cyklu życia oprogramowania. Propozycja wartości Composera to prędkość: szybka iteracja oparta na środowisku roboczym, która utrzymuje programistów w płynności. Wartością GPT-5-Codex jest głębia: agentowa trwałość, poprawność sterowana testami i audytowalność dla zaawansowanych transformacji. Pragmatyczny podręcznik inżynierii to: zorganizowanie obu: agenci o krótkiej pętli, przypominający Composera, do codziennego użytku oraz agenci w stylu GPT-5-Codex do bramkowanych operacji o wysokiej niezawodności. Wczesne testy porównawcze sugerują, że oba te rozwiązania staną się częścią krótkoterminowego zestawu narzędzi dla programistów, a nie zastąpią jednego.
Nie ma jednego obiektywnego zwycięzcy we wszystkich wymiarach. Modele mają swoje mocne strony:
- Kodeks GPT-5: Silniejszy w dogłębnych testach poprawności, rozumowaniu na szeroką skalę i autonomicznych, wielogodzinnych przepływach pracy. Sprawdza się doskonale, gdy złożoność zadań wymaga długiego rozumowania lub intensywnej weryfikacji.
- Kompozytor: Lepsze w zastosowaniach ściśle zintegrowanych z edytorem, spójności kontekstu wielu plików i szybkiej iteracji w środowisku Cursora. Może to być lepsze dla codziennej produktywności programistów, gdzie potrzebne są natychmiastowe, precyzyjne edycje uwzględniające kontekst.
Zobacz też Cursor 2.0 i Composer: jak wieloagentowe podejście do zaskakującego kodowania sztucznej inteligencji
Jak zacząć
CometAPI to ujednolicona platforma API, która agreguje ponad 500 modeli AI od wiodących dostawców — takich jak seria GPT firmy OpenAI, Gemini firmy Google, Claude firmy Anthropic, Midjourney, Suno i innych — w jednym, przyjaznym dla programistów interfejsie. Oferując spójne uwierzytelnianie, formatowanie żądań i obsługę odpowiedzi, CometAPI radykalnie upraszcza integrację możliwości AI z aplikacjami. Niezależnie od tego, czy tworzysz chatboty, generatory obrazów, kompozytorów muzycznych czy oparte na danych potoki analityczne, CometAPI pozwala Ci szybciej iterować, kontrolować koszty i pozostać niezależnym od dostawcy — wszystko to przy jednoczesnym korzystaniu z najnowszych przełomów w ekosystemie AI.
Deweloperzy mogą uzyskać dostęp API GPT-5-Codexpoprzez CometAPI, najnowsza wersja modelu jest zawsze aktualizowany na oficjalnej stronie internetowej. Na początek zapoznaj się z możliwościami modelu w Plac zabaw i zapoznaj się z Przewodnik po API aby uzyskać szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. Interfejs API Comet zaoferuj cenę znacznie niższą niż oficjalna, aby ułatwić Ci integrację.
Gotowy do drogi?→ Zarejestruj się w CometAPI już dziś !
Jeśli chcesz poznać więcej wskazówek, poradników i nowości na temat sztucznej inteligencji, obserwuj nas na VK, X oraz Discord!