
Gemini 2.5 Flash API to najnowszy multimodalny model sztucznej inteligencji firmy Google, zaprojektowany do szybkich i ekonomicznych zadań z kontrolowanymi możliwościami rozumowania, umożliwiający programistom włączanie i wyłączanie zaawansowanych funkcji „myślenia” za pośrednictwem Gemini API.Najnowsze modele to gemini-2.5-flash.
Przegląd Gemini 2.5 Flash
Gemini 2.5 Flash został zaprojektowany tak, aby dostarczać szybkie odpowiedzi bez uszczerbku dla jakości wyników. Obsługuje multimodalne dane wejściowe, w tym tekst, obrazy, dźwięk i wideo, dzięki czemu nadaje się do różnych zastosowań. Model jest dostępny za pośrednictwem platform takich jak Google AI Studio i Vertex AI, zapewniając programistom narzędzia niezbędne do bezproblemowej integracji z różnymi systemami.
Informacje podstawowe (funkcje)
Gemini 2.5 Flash wprowadza kilka wyróżniających się funkcji cechy które wyróżniają go w rodzinie Gemini 2.5:
- Hybrydowe rozumowanie:Deweloperzy mogą ustawić myślenie_budżetowe parametr umożliwiający precyzyjną kontrolę liczby tokenów, które model przeznacza na wewnętrzne rozumowanie przed wyjściem.
- Granica Pareto:Położony w optymalny punkt kosztowo-efektywnyFlash oferuje najlepszy stosunek ceny do inteligencji wśród modeli 2.5.
- Wsparcie multimodalne: Procesy XNUMX, zdjęcia, wideo, audio natywnie, umożliwiając bogatsze możliwości konwersacyjne i analityczne.
- Kontekst 1 miliona tokenów:Niezrównana długość kontekstu pozwala na dogłębną analizę i zrozumienie obszernego dokumentu w ramach jednego żądania.
Wersje modelu
Gemini 2.5 Flash przeszedł przez następujące kluczowe etapy Wersje:
- gemini-2.5-flash-lite-preview-09-2025: Lepsza użyteczność narzędzia: Lepsza wydajność w przypadku złożonych, wieloetapowych zadań, z 5% wzrostem wyników w teście SWE-Bench Verified (z 48.9% do 54%). Większa wydajność: Włączenie wnioskowania pozwala uzyskać wyższą jakość wyników przy użyciu mniejszej liczby tokenów, co zmniejsza opóźnienia i koszty.
- Podgląd 04-17:Wczesna wersja dostępu z możliwością „myślenia”, dostępna za pośrednictwem gemini-2.5-flash-podgląd-04-17.
- Stabilna ogólna dostępność (GA):Od 17 czerwca 2025 r. stabilny punkt końcowy gemini-2.5-błysk zastępuje wersję zapoznawczą, zapewniając niezawodność na poziomie produkcyjnym bez zmian w interfejsie API w stosunku do wersji zapoznawczej z 20 maja.
- Wycofanie wersji zapoznawczej:Wyłączenie punktów końcowych w wersji zapoznawczej zaplanowano na 15 lipca 2025 r.; użytkownicy muszą dokonać migracji do punktu końcowego w wersji ogólnej przed tą datą.
Od lipca 2025 r. Gemini 2.5 Flash jest publicznie dostępny i stabilny (bez zmian w stosunku do wersji XNUMX). gemini-2.5-flash-podgląd-05-20 ).Jeśli używasz gemini-2.5-flash-preview-04-17Aktualne ceny wersji zapoznawczej będą obowiązywać do planowanego wycofania modelu końcowego 15 lipca 2025 r., kiedy to zostanie on wyłączony. Możesz dokonać migracji do ogólnie dostępnego modelu.gemini-2.5-flash".
Szybciej, taniej, mądrzej:
- Cele projektowe: niskie opóźnienie + wysoka przepustowość + niskie koszty;
- Ogólne przyspieszenie rozumowania, przetwarzania multimodalnego i zadań wymagających dużej ilości tekstu;
- Wykorzystanie tokenów zostaje ograniczone o 20–30%, co znacznie obniża koszty wnioskowania.
Specyfikacja techniczna
Okno kontekstu wejściowego: do 1 miliona tokenów, co pozwala na obszerne przechowywanie kontekstu.
Tokeny wyjściowe: Możliwość wygenerowania do 8,192 tokenów na odpowiedź.
Obsługiwane formy przekazu: tekst, obrazy, dźwięk i wideo.
Platformy integracyjne: dostępne za pośrednictwem Google AI Studio i Vertex AI.
Ceny: Konkurencyjny model cenowy oparty na tokenach, umożliwiający opłacalne wdrożenie.
Dane Techniczne
Pod maską Gemini 2.5 Flash znajduje się oparty na transformatorze duży model językowy trenowany na mieszance danych internetowych, kodowych, graficznych i wideo. Klucz technical specyfikacje obejmują:
Szkolenie multimodalne:Wyszkolony w dopasowywaniu wielu modalności, Flash może płynnie łączyć tekst z zdjęcia, wideolub audio, przydatne do takich zadań, jak podsumowania wideo lub dodawanie napisów audio.
Dynamiczny proces myślenia:Implementuje wewnętrzną pętlę rozumowania, w której model plany oraz rozkłada złożone monity przed ostatecznym wyjściem.
Konfigurowalne budżety myślowe: the myślenie_budżetowe można ustawić z 0 (bez uzasadnienia) do Tokeny 24,576, umożliwiając kompromis między opóźnieniem a jakością odpowiedzi.
Integracja narzędzi: Obsługuje Uziemienie z wyszukiwarką Google, Wykonanie kodu, Kontekst adresu URL, Wywołanie funkcji, umożliwiając wykonywanie rzeczywistych działań bezpośrednio na podstawie podpowiedzi w języku naturalnym.
Wydajność wzorcowa
W rygorystycznych ocenach Gemini 2.5 Flash wykazuje wiodący w branży wydajność:
- Podpowiedzi LMArena Hard: Zdobył punkty drugi po 2.5 Pro w wymagającym teście Hard Prompts, wykazując się silnymi zdolnościami rozumowania wieloetapowego.
- Wynik MMLU 0.809:Przewyższa średnią wydajność modelu dzięki 0.809 Dokładność MMLU odzwierciedla jego szeroką wiedzę przedmiotową i zdolność rozumowania.
- Opóźnienie i przepustowość:Osiąga 271.4 tokenów/sek. prędkość dekodowania z 0.29 s Czas do pierwszego tokena, co czyni go idealnym rozwiązaniem dla obciążeń wrażliwych na opóźnienia.
- Lider w zakresie stosunku ceny do wydajności: W $0.26/1 mln tokenówFlash bije na głowę wielu konkurentów, jednocześnie dorównując im lub przewyższając ich w kluczowych testach.
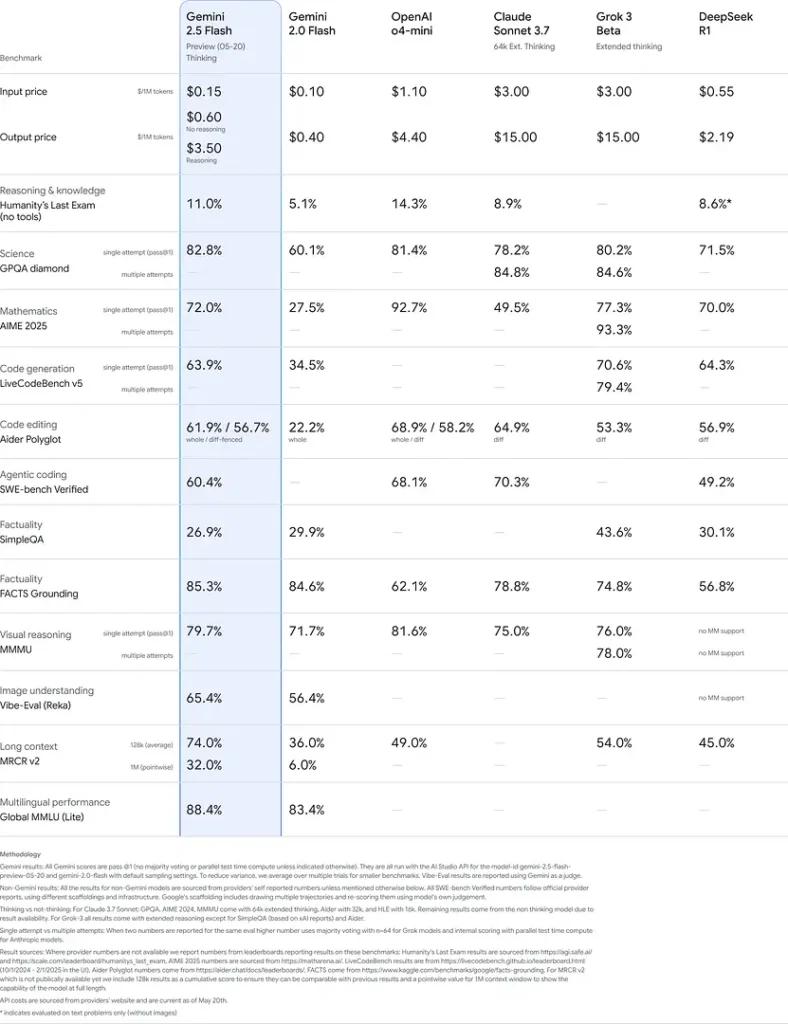
Wyniki te wskazują na przewagę Gemini 2.5 Flash w zakresie rozumowania, zrozumienia naukowego, rozwiązywania problemów matematycznych, kodowania, interpretacji wizualnej i obsługi wielu języków:
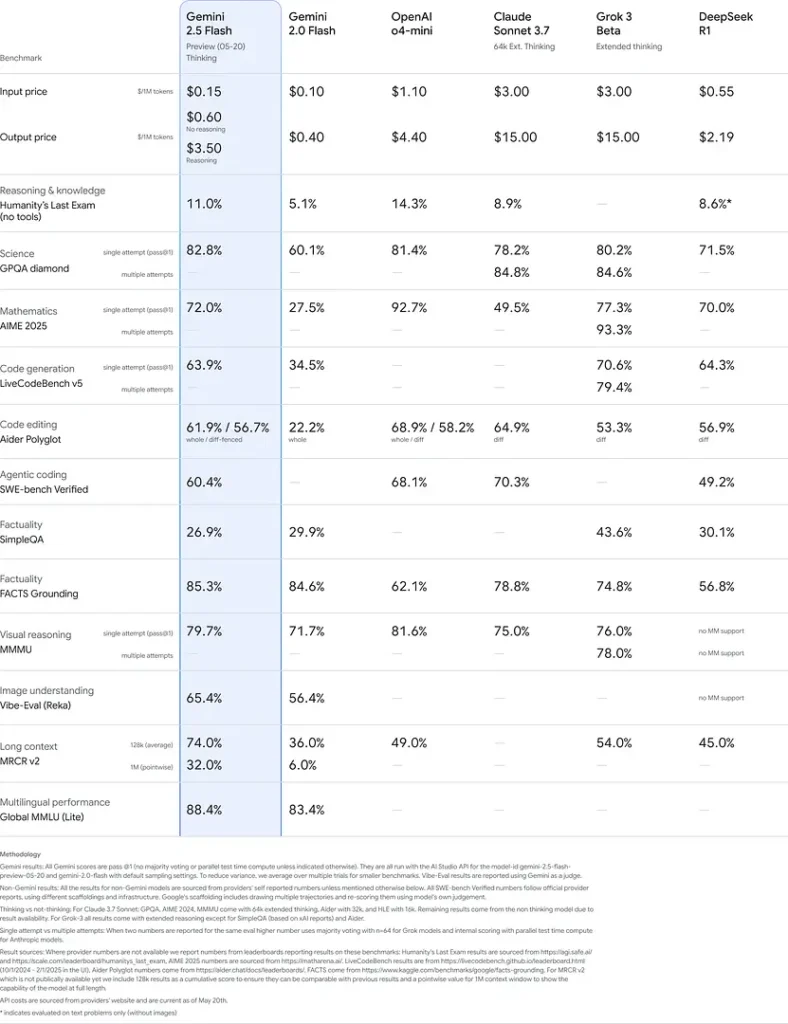
Ograniczenia
Choć Gemini 2.5 Flash jest wydajny, posiada pewne Ograniczenia:
- Zagrożenia bezpieczeństwa:Model może wykazywać ton „kaznodziejski” i może generować wiarygodnie brzmiące, ale niepoprawne lub stronnicze wyniki (halucynacje), szczególnie w przypadku zapytań skrajnych. Rygorystyczny nadzór ludzki pozostaje niezbędny.
- Limity szybkości:Użycie interfejsu API jest ograniczone limitami szybkości (10 RPM, 250,000 250 TPM, XNUMX RPD w przypadku domyślnych warstw), co może mieć wpływ na przetwarzanie wsadowe lub aplikacje o dużej objętości.
- Piętro wywiadu:Choć wyjątkowo zdolny do lampa błyskowa model pozostaje mniej dokładny niż 2.5 Pro w najbardziej wymagających zadaniach agentowych, takich jak zaawansowane kodowanie czy koordynacja wielu agentów.
- Kompromisy kosztowe:Chociaż oferuje najlepsze cena-wydajność, szerokie wykorzystanie myślenia tryb ten zwiększa ogólne zużycie tokenów, podnosząc koszty monitów wymagających głębokiego rozumowania.
Zobacz także Interfejs API Gemini 2.5 Pro
Podsumowanie
Gemini 2.5 Flash jest dowodem zaangażowania Google w rozwój technologii AI. Dzięki solidnej wydajności, możliwościom multimodalnym i wydajnemu zarządzaniu zasobami oferuje kompleksowe rozwiązanie dla programistów i organizacji, które chcą wykorzystać moc sztucznej inteligencji w swoich działaniach.
Jak zadzwonić Gemini 2.5 Flash API z CometAPI
Gemini 2.5 Flash Ceny API w CometAPI, 20% zniżki od ceny oficjalnej:
- Żetony wejściowe: 0.24 USD / mln żetonów
- Tokeny wyjściowe: 0.96/M tokenów
Wymagane kroki
- Zaloguj się do pl.com. Jeśli jeszcze nie jesteś naszym użytkownikiem, zarejestruj się najpierw
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.
- Uzyskaj adres URL tej witryny: https://api.cometapi.com/
Metody użytkowania
- Wybierz "
gemini-2.5-flash” punkt końcowy do wysłania żądania API i ustawienia treści żądania. Metoda żądania i treść żądania są pobierane z naszej witryny internetowej API doc. Nasza witryna internetowa udostępnia również test Apifox dla Twojej wygody. - Zastępować za pomocą aktualnego klucza CometAPI ze swojego konta.
- Wpisz swoje pytanie lub prośbę w polu treści — model odpowie właśnie na tę wiadomość.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
Aby uzyskać informacje o modelu uruchomionym w interfejsie API Comet, zobacz https://api.cometapi.com/new-model.
Informacje o cenie modelu w interfejsie API Comet można znaleźć tutaj https://api.cometapi.com/pricing.
Przykład użycia API
Programiści mogą wchodzić w interakcje z gemini-2.5-błysk poprzez API CometAPI, umożliwiając integrację z różnymi aplikacjami. Poniżej znajduje się przykład Pythona:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Ten skrypt wysyła monit do Gemini 2.5 Flash modeluje i drukuje wygenerowaną odpowiedź, pokazując, jak ją wykorzystać Gemini 2.5 Flash dla skomplikowanych wyjaśnień.