

Google i jego ramię badawcze DeepMind po cichu (a potem już mniej po cichu) wykonały kolejny duży krok w mapie rozwoju Gemini: Gemini 3.1 Pro. To wydanie, udostępnione na konsumenckich powierzchniach oraz w CometAPI, pozycjonowane jest jako ulepszenie wydajności i rozumowania w rodzinie Gemini 3 — obiecujące wyraźnie silniejsze rozumowanie w długiej formie, lepsze zrozumienie multimodalne i większą skalowalność dla zastosowań w rzeczywistych warunkach.
Najnowszy model Google — czym jest Gemini 3.1 Pro?
Gemini 3.1 Pro to pierwsza przyrostowa aktualizacja w rodzinie Gemini 3, pozycjonowana jako „najbardziej kompetentny” model do rozumowania, zoptymalizowany pod zadania wieloetapowe, multimodalne i agentowe. Udostępniony w publicznym podglądzie w połowie lutego 2026 r. (zapowiedź 19–20 lutego 2026), model jest jawnie ukierunkowany na scenariusze wymagające utrzymanych łańcuchów rozumowania, użycia narzędzi i rozumienia długiego kontekstu — na przykład: szerokozakrojona synteza badań, agenci inżynieryjni koordynujący narzędzia i systemy oraz multimodalna analiza dokumentów łączących tekst, obrazy, audio i wideo.
Na wysokim poziomie twórcy opisują Gemini 3.1 Pro jako:
- Natywnie multimodalny — zdolny przyjmować i rozumować na podstawie tekstu, obrazów, dźwięku i wideo.
- Zbudowany pod długi kontekst — obsługujący bardzo duże okna kontekstu, odpowiednie dla całych baz kodu, teczek wielodokumentowych czy długich transkryptów.
- Zoptymalizowany pod niezawodne rozumowanie i agentowe przepływy pracy, co oznacza, że jest strojon y do planowania, wywoływania narzędzi i weryfikacji wyników w zadaniach wieloetapowych.
Dlaczego to teraz ma znaczenie: organizacje i deweloperzy przechodzą od „dobrych asystentów konwersacyjnych” do „wysokostawkowych agentów wspierających decyzje i badania” (tworzenie dokumentów prawnych, synteza B+R, zrozumienie multimodalnych dokumentów). Gemini 3.1 Pro jest zaprojektowany właśnie do tego korytarza — by ograniczać halucynacje, zapewniać śledzalne rozumowanie i integrować się z CometAPI zarówno do prototypowania, jak i produkcji.
Jakie są techniczne wyróżniki i funkcje Gemini 3.1 Pro?
Wbudowana multimodalność i ekstremalne okna kontekstu
Gemini 3.1 Pro kontynuuje nacisk linii Gemini na multimodalność. Zgodnie z kartą modelu i notatkami produktowymi, model przyjmuje i rozumuje na podstawie tekstu, obrazów, dźwięku i wideo w tym samym potoku — co upraszcza przepływy pracy, w których typy danych są mieszane (np. zeznania prawne z audio + transkryptem + skanami). Co istotne, model obsługuje okno kontekstu o wielkości 1,000,000 tokenów i potrafi generować długie wyjścia (opublikowane informacje wskazują na bardzo duże limity wyjściowe, odpowiednie dla zadań długiej formy). Ta skala sprawia, że nadaje się do zastosowań takich jak analiza całych repozytoriów kodu, wielorozdziałowych dokumentów czy długich transkryptów bez potrzeby dzielenia na fragmenty.
„Dynamiczne myślenie”: ulepszone rozumowanie i planowanie krokowe
Google opisuje 3.1 Pro jako mający ulepszone „myślenie” — tj. lepszą wewnętrzną obsługę łańcucha rozumowania i dynamiczny dobór strategii wnioskowania zależnie od złożoności zadania. Model jest dostrojony tak, by uruchamiać jawne, wieloetapowe planowanie, gdy jest to potrzebne, i robić to oszczędnie w tokenach. W praktyce przekłada się to na mniej halucynacji przy złożonych, krokowych problemach oraz lepszą spójność faktograficzną na benchmarkach wieloetapowego rozumowania.
Przepływy pracy agentowe i użycie narzędzi
Głównym celem projektowym 3.1 Pro jest wydajność agentowa: koordynowanie narzędzi, wywoływanie ugruntowania w sieci lub wyszukiwania, pisanie i wykonywanie fragmentów kodu oraz weryfikacja wyników w drugich przebiegach. Google zintegrowało 3.1 Pro z produktami nastawionymi na agentów (np. środowisko deweloperskie Antigravity), aby umożliwić modelom wykonywanie zadań obejmujących edytor, terminal i przeglądarkę — oraz rejestrowanie artefaktów takich jak zrzuty ekranu i nagrania z przeglądarki w celu potwierdzania postępu. Funkcje te mają zmniejszyć lukę między modelami „udzielającymi porad” a modelami, które rzeczywiście niezawodnie realizują wielonarzędziowe przepływy pracy.
Specjalizowane tryby (Deep Research, Deep Think)
Google łączy 3.1 Pro z „Deep Research” i zapowiada nadchodzący wariant „Deep Think”. Te podtryby są skierowane odpowiednio do zadań badawczych wymagających wysokiej kompletności oraz do maksymalnej głębokości rozumowania (kosztem większych nakładów obliczeń i opóźnień). Mają służyć analitykom, badaczom i deweloperom, którzy potrzebują bardziej rozważnych, wyższej jakości wyników zamiast najszybszych i najtańszych odpowiedzi.
Jak Gemini 3.1 Pro wypada na benchmarkach?
Gemini 3.1 Pro osiąga silne zyski względem wcześniejszych wyników Gemini 3 Pro, często obejmując prowadzenie w szerokim zestawie miar wieloetapowego rozumowania i multimodalności — ale ustępując niektórym konkurentom w określonych, specjalistycznych zadaniach (zwłaszcza w niektórych zaawansowanych zadaniach kodowania lub pakietach pytań eksperckich). Krótko: szerokie ulepszenia z wąskimi przewagami konkurencji w niszowych benchmarkach.
Kluczowe deklaracje benchmarkowe i najważniejsze liczby
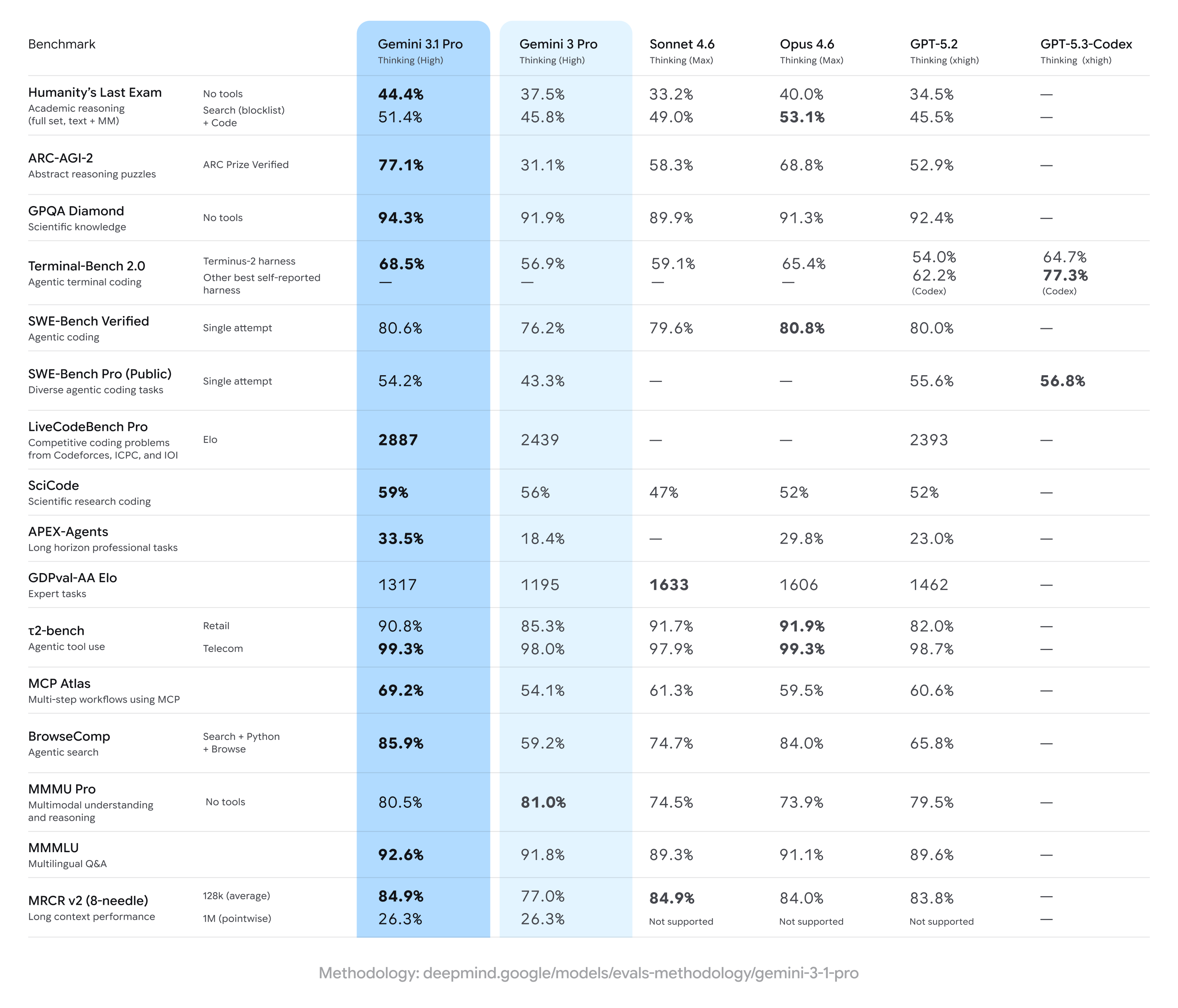
- ARC-AGI-2 (rozumowanie abstrakcyjne / wieloetapowe łamigłówki naukowe): Zgłoszone wzrosty dla Gemini 3.1 Pro pokazują znaczącą poprawę względem wcześniejszych wersji Gemini 3 Pro; jeden zestaw testów społeczności wskazał ponad dwukrotną poprawę na ARC-AGI-2 względem bazowego Gemini 3 Pro w krótkich, ukierunkowanych testach. Konkretnie zgłaszane wyniki (testy społeczności) umieszczają Gemini 3.1 Pro na poziomie ~77.1% w niektórych agregacjach w stylu ARC (raporty publiczne).
- GPQA Diamond i benchmarki naukowe na poziomie magisterskim: Dane wskazują, że Gemini 3.1 Pro osiągnął rekordowe wyniki na GPQA Diamond (benchmark pytań naukowych na poziomie studiów magisterskich), przewyższając wcześniejsze modele Gemini i ustanawiając nowy punkt odniesienia dla rodziny w niezależnych przebiegach. Te zyski odzwierciedlają ulepszony łańcuch rozumowania i strojenie rozumowania krokowego.
- „Humanity’s Last Exam” z włączonymi narzędziami (wielonarzędziowe, ugruntowane rozumowanie): W bezpośrednich porównaniach z Claude Opus 4.6 od Anthropic, Claude osiągnął 53.1% na tym złożonym teście z narzędziami, podczas gdy Gemini 3.1 Pro uzyskał 51.4% w tej samej rundzie — pokazując, że Gemini jest blisko, ale nie na szczycie w tym konkretnym egzaminie wielonarzędziowym.
- Benchmarki kodowania i terminala (Terminal-Bench 2.0, SWE-Bench Pro): Specjalistyczne benchmarki kodowania pokazały większe różnice. Na Terminal-Bench 2.0 z określonymi harnessami, warianty GPT-5.3-Codex osiągnęły około 77.3% vs ~68.5% dla Gemini 3.1 Pro w tych samych porównaniach. Na publicznie raportowanych wynikach SWE-Bench Pro, Gemini 3.1 Pro uzyskał ~54.2% vs 56.8% dla GPT-5.3-Codex — bliżej, ale rodzina Codex od OpenAI utrzymuje przewagę w specjalistycznych zadaniach programistycznych w tych przebiegach.
- GDPval-AA Elo (ocena zadań eksperckich): W zagregowanym rankingu w stylu Elo dla zadań eksperckich, warianty Claude Sonnet/Opus osiągnęły wyższe wyniki (np. ~1606–1633 punktów), podczas gdy jeden raport publiczny umieścił Gemini 3.1 Pro na poziomie ~1317 punktów w tym samym zbiorze — wskazując pole do poprawy w określonych wąskich domenach eksperckich.
Wyniki prób w realnych warunkach i testy praktyczne
Opracowania analityków pokazują, że Gemini 3.1 Pro szczególnie wyróżnia się w:
- Podsumowywaniu długiego kontekstu i syntezie wielodokumentowej, gdzie okno 1M tokenów eliminuje artefaktogenne dzielenie.
- Zadaniach rozumienia multimodalnego, gdzie powiązanie obrazu z tekstem poprawia ekstrakcję faktów.
- Automatyzacji agentowej (np. koordynowaniu prostych łańcuchów narzędzi) — próby w Antigravity demonstrują, że orkiestracja zadań wieloagentowych jest wykonalna, z artefaktami dokumentującymi każdy krok.
Gdzie Gemini 3.1 Pro wciąż odstaje (co mówią liczby)
Żaden model nie jest najlepszy we wszystkim. Niezależne komentarze i testy społeczności wskazują konkretne luki:
- Benchmarki inżynierii oprogramowania i utrzymania kodu (SWE-Bench Pro i podobne) — Gemini 3.1 Pro ustępuje konkurentowi (Claude Opus 4.6 od Anthropic) w zadaniach sprawdzających praktyczne umiejętności inżynierskie: szerokie refaktoryzacje, triage błędów w nieuporządkowanych bazach kodu i niektóre typy automatycznej naprawy programów. Innymi słowy, dla codziennego utrzymania inżynierskiego modele wyspecjalizowane nadal mają przewagę w niektórych środowiskach testowych.
- Mikrozadania wrażliwe na opóźnienia — ponieważ Gemini 3.1 Pro jest strojony pod głębię, zadania wymagające ultraniskich opóźnień i wysokiej przepustowości (np. mikroinfernencja dla lekkich interfejsów konwersacyjnych) mogą lepiej obsługiwać warianty „Flash” lub inne zoptymalizowane w rodzinie Gemini.
Jaki jest cennik Gemini 3.1 Pro?
możesz uzyskać dostęp do Gemini 3.1 Pro na dwa sposoby — subskrypcja konsumencka lub deweloperskie API — a ceny różnią się w obu przypadkach.
- Konsument (aplikacja Gemini / Google AI Pro): Dostęp do Gemini 3.1 Pro jest wliczony w subskrypcję Google AI Pro, która w USA wynosi $19.99 / miesiąc (Google oferuje też niższy poziom „AI Plus” i wyższy poziom „AI Ultra”). Google.
- Deweloper / API (rozliczanie tokenowe): Jeśli wywołujesz modele Gemini przez Gemini/AI developer API, rozliczenie odbywa się wg tokenów. Dla podglądu Gemini 3.x Pro opublikowane ceny deweloperskie to w przybliżeniu: $2.00 za 1M tokenów wejściowych oraz $12.00 za 1M tokenów wyjściowych dla standardowego pasma (≤200k promptów) — z wyższymi progami (np. $4/$18 za 1M) dla bardzo dużych kontekstów. (Zobacz tabelę cen Gemini API dla pełnych szczegółów i cen wsadowych.)
- Jeśli korzystasz z Gemini 3.1 Pro poprzez CometAPI:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Wejście:$1.6/M; Wyjście:$9.6/M | Wejście:$2/M; Wyjście:$12/M |
Cennik subskrypcji konsumenckiej (aplikacja Gemini)
Dla planów końcowych użytkowników w aplikacji Gemini, Google strukturyzuje poziomy, które ograniczają dostęp do wariantów modeli i dodatkowych funkcji: Google AI Pro i Google AI Ultra. Ceny różnią się w zależności od rynku i waluty; opublikowane przykłady pokazują Google AI Pro za $19.99/miesiąc (z dostępnymi promocjami na okres próbny), a taryfy walutowe są pokazane na stronie produktu (w tym oferty próbne i krótkoterminowe obniżki). AI Ultra obejmuje wyższy poziom dostępu (np. priorytet do nowych innowacji, wyższe pule kredytów na generowanie wideo) za wyższą miesięczną opłatą. Te plany konsumenckie są konkurencyjne wobec innych wysokiej klasy subskrypcji AI i mają zapewnić indywidualnym użytkownikom zaawansowanym lub małym zespołom dostęp do funkcji 3.1 Pro bez integracji API.
Praktyczne wskazówki dot. promptów i użycia (co bym zrobił)
Użyj ich, aby uzyskiwać wiarygodne, powtarzalne wyniki:
- Jawny plan kroków
Wzorzec promptu:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.
To wykorzystuje silniejszą realizację krokową 3.1 Pro i daje punkty kontrolne. - Strukturalne wyjście ze schematami
Poproś o JSON ze schematem istrict: true. Ponieważ 3.1 Pro częściej generuje długie, zgodne ze schematem wyjścia, dostaniesz większe pojedyncze odpowiedzi możliwe do dalszego parsowania. - „Kanapka” ze sprawdzaniem narzędzia
Przy wywoływaniu zewnętrznych narzędzi (API, uruchamiacze kodu) poproś model o: plan → dokładne wywołanie narzędzia (do skopiowania/wklejenia) → kroki walidacyjne. Następnie zweryfikuj kroki walidacyjne poza modelem przed kontynuacją. - Uważaj na zaufanie do pojedynczego kroku
Nawet jeśli model napisze kod lub polecenia wyglądające perfekcyjnie, uruchom niezależną walidację (testy, lintery, wykonanie w piaskownicy) — zwłaszcza dla działań agentowych/autonomicznych.
Praktycznie z Gemini 3.1 Pro
Przypadek testowy 1: Asystent badawczy dla długiego kontekstu (NotebookLM / Deep Research)
Cel: Ocenić zdolność modelu do syntezy 10–50 długich dokumentów (np. raporty, whitepapery) w wielostronicowe podsumowanie dla zarządu z cytowaniami i listą działań.
Konfiguracja: Podaj korpus o łącznej wielkości 200k–800k tokenów; zleć modelowi przygotowanie 2–4-stronicowego podsumowania z jawnymi cytowaniami i rekomendacjami „następnych kroków”. Użyj powtarzalnego szablonu promptu i mierz czas, zużycie tokenów (koszt) oraz dokładność faktograficzną.
Wyniki: Szybsza synteza end-to-end z mniejszą liczbą artefaktów wynikających z dzielenia względem starszych modeli, większa wierność cytowań w podsumowaniu i poprawiona spójność w dużej skali — kosztem istotnego zużycia tokenów (zaplanować budżet). Benchmarki i testy praktyczne pokazują, że Gemini 3.1 Pro wyróżnia się w syntezie wielodokumentowej dzięki oknu 1M tokenów.
Przypadek testowy 2: Agentowy asystent kodowania (Antigravity + GitHub Copilot)
Cel: Zmierzyć redukcję czasu realizacji wieloetapowych zadań deweloperskich (np. wdrożenie funkcji w kilku plikach, uruchomienie testów, naprawa testów niezdanych).
Konfiguracja: Użyj Antigravity lub GitHub Copilot w podglądzie z wybranym Gemini 3.1 Pro. Zdefiniuj odtwarzalne zadania (utworzenie zgłoszenia → implementacja → uruchomienie testów), loguj kroki i artefakty agenta oraz porównaj z bazową realizacją wyłącznie przez człowieka.
Wyniki: Ulepszona orkiestracja zadań wieloetapowych (rejestrowanie artefaktów, automatyczne propozycje poprawek), lepsze rozumowanie wieloplikowe niż w poprzednim Gemini 3 Pro oraz mierzalne oszczędności czasu przy rutynowych pracach nad funkcjami. Specjalistyczne, niskopoziomowe debugowanie systemów może nadal faworyzować modele „code-first” (wyniki społeczności pokazują lukę względem niektórych wariantów GPT-Codex na wybranych benchmarkach terminalowych).
Przypadek testowy 3: Multimodalna analiza dokumentów prawnych/medycznych
Cel: Użyć modelu do załadowania mieszanego korpusu (skanowane PDF-y, obrazy, transkrypty audio), wyekstrahować kluczowe fakty i przygotować macierz ryzyka oraz priorytety działań.
Konfiguracja: Dostarcz zbiór z obrazami skanów i tekstem z OCR, plus wspierające audio. Mierz precyzję w rozpoznawaniu nazwanych encji, odsetek fałszywie pozytywnych i zdolność modelu do odwoływania się do artefaktów źródłowych.
Wyniki: Silniejsze zintegrowane rozumowanie między modalnościami i lepiej śledzalne wyniki (zdolność wskazania obrazu/strony/znacznika czasu w audio, które wspierają twierdzenie). Długie okno kontekstu ogranicza potrzebę ręcznego dzielenia i krzyżowego odwoływania. Jednak w domenach regulowanych wyniki powinny być weryfikowane przez ekspertów dziedzinowych i należy stosować potok uwiarygadniania i weryfikacji.
Pierwsze wrażenia (co się różni)
- Głębsze rozumowanie krok po kroku. Zadania, które wcześniej wymagały wielu iteracji — np. synteza wielodokumentowa, wieloetapowa matematyka/logika — częściej kończą się w mniejszej liczbie przebiegów i z wyraźniejszymi wyjściami w stylu łańcucha rozumowania (bez ujawniania wewnętrznych instrukcji).
- Dłuższe, wyższej jakości wyjścia strukturalne. JSON i długie automatyzacje są bardziej spójne i często znacznie dłuższe (niektórzy użytkownicy zgłaszali wielkości wyjść zdecydowanie większe niż w 3.0). To świetne dla zadań generatywnych, w których chcesz jeden, duży ładunek danych. Spodziewaj się większych wyjść i strumieniowania.
- Bardziej efektywne gospodarowanie tokenami/kontekstem. Poprawiona efektywność tokenowa i bardziej „ugruntowane, spójne faktograficznie” zachowanie w scenariuszach z użyciem narzędzi. Przekłada się to na mniej halucynacji przy krótkich, faktograficznych zapytaniach.
Ostateczna ocena: czy warto wdrożyć Gemini 3.1 Pro już teraz?
Gemini 3.1 Pro stanowi istotny krok naprzód w rodzinie Gemini, z wykazanymi ulepszeniami w rozumowaniu, kodowaniu i benchmarkach agentowych — potwierdzonymi kartą modelu Google i niezależnymi trackerami, które odnotowują duże skoki na wybranych listach liderów. Dla zespołów potrzebujących zaawansowanego rozumowania, koordynacji narzędzi agentowych lub długokontextowych możliwości multimodalnych, 3.1 Pro to mocny kandydat.
Deweloperzy mogą uzyskać dostęp do Gemini 3.1 Pro przez CometAPI już teraz. Aby zacząć, poznaj możliwości modelu w Playground i zapoznaj się z przewodnikiem API po szczegółowe instrukcje. Przed uzyskaniem dostępu upewnij się, że zalogowałeś się do CometAPI i uzyskałeś klucz API. CometAPI oferuje cenę znacznie niższą niż oficjalna, aby ułatwić integrację.
Gotowy do startu?→ Zarejestruj się do Gemini 3.1 pro już dziś !
Jeśli chcesz poznać więcej wskazówek, przewodników i nowości o AI, obserwuj nas na VK, X i Discord!