

GLM-4.6 jest najnowszą główną wersją rodziny GLM firmy Z.ai (dawniej Zhipu AI): czwartą generacją oprogramowania w wielu językach Model MoE (mieszanka ekspertów) dostrojony do przepływy pracy agentowe, wnioskowanie długokontekstowe i kodowanie w świecie rzeczywistymW wydaniu położono nacisk na praktyczną integrację agenta/narzędzia, bardzo dużą okno kontekstowei dostępność wersji otwartej do wdrożenia lokalnego.
Główne cechy
- Długi kontekst - rodzinny Token 200K okno kontekstowe (rozszerzone z 128 KB). ()
- Kodowanie i możliwości agenta — wprowadził ulepszenia dotyczące zadań związanych z kodowaniem w warunkach rzeczywistych i lepsze wywoływanie narzędzi przez agentów.
- Wydajność: — zgłoszono ~30% niższe zużycie tokenów vs GLM-4.5 w testach Z.ai.
- Wdrażanie i kwantyzacja — po raz pierwszy ogłoszono integrację FP8 i Int4 dla układów Cambricon; natywne wsparcie FP8 na wątkach Moore za pośrednictwem vLLM.
- Rozmiar modelu i typ tensora — opublikowane artefakty wskazują na ~357B-parametr model (tensory BF16 / F32) na Hugging Face.
Szczegóły techniczne
Modalności i formaty. GLM-4.6 to tylko tekst LLM (modalności wejścia i wyjścia: tekst). Długość kontekstu = 200 tys. tokenów; maksymalna wydajność = 128 tys. tokenów.
Kwantyzacja i wsparcie sprzętowe. Zespół raportuje Kwantyzacja FP8/Int4 na chipsach Cambricon i natywny FP8 wykonywanie na procesorach graficznych Moore Threads przy użyciu vLLM do wnioskowania — co ma znaczenie dla obniżenia kosztów wnioskowania i umożliwienia wdrożeń lokalnych i w chmurze krajowej.
Narzędzia i integracje. GLM-4.6 jest dystrybuowany za pośrednictwem interfejsu API firmy Z.ai, sieci zewnętrznych dostawców (np. CometAPI) i integrowany z agentami kodującymi (Claude Code, Cline, Roo Code, Kilo Code).
Szczegóły techniczne
Modalności i formaty. GLM-4.6 to tylko tekst LLM (modalności wejścia i wyjścia: tekst). Długość kontekstu = 200 tys. tokenów; maksymalna wydajność = 128 tys. tokenów.
Kwantyzacja i wsparcie sprzętowe. Zespół raportuje Kwantyzacja FP8/Int4 na chipsach Cambricon i natywny FP8 wykonywanie na procesorach graficznych Moore Threads przy użyciu vLLM do wnioskowania — co ma znaczenie dla obniżenia kosztów wnioskowania i umożliwienia wdrożeń lokalnych i w chmurze krajowej.
Narzędzia i integracje. GLM-4.6 jest dystrybuowany za pośrednictwem interfejsu API firmy Z.ai, sieci zewnętrznych dostawców (np. CometAPI) i integrowany z agentami kodującymi (Claude Code, Cline, Roo Code, Kilo Code).
Wydajność wzorcowa
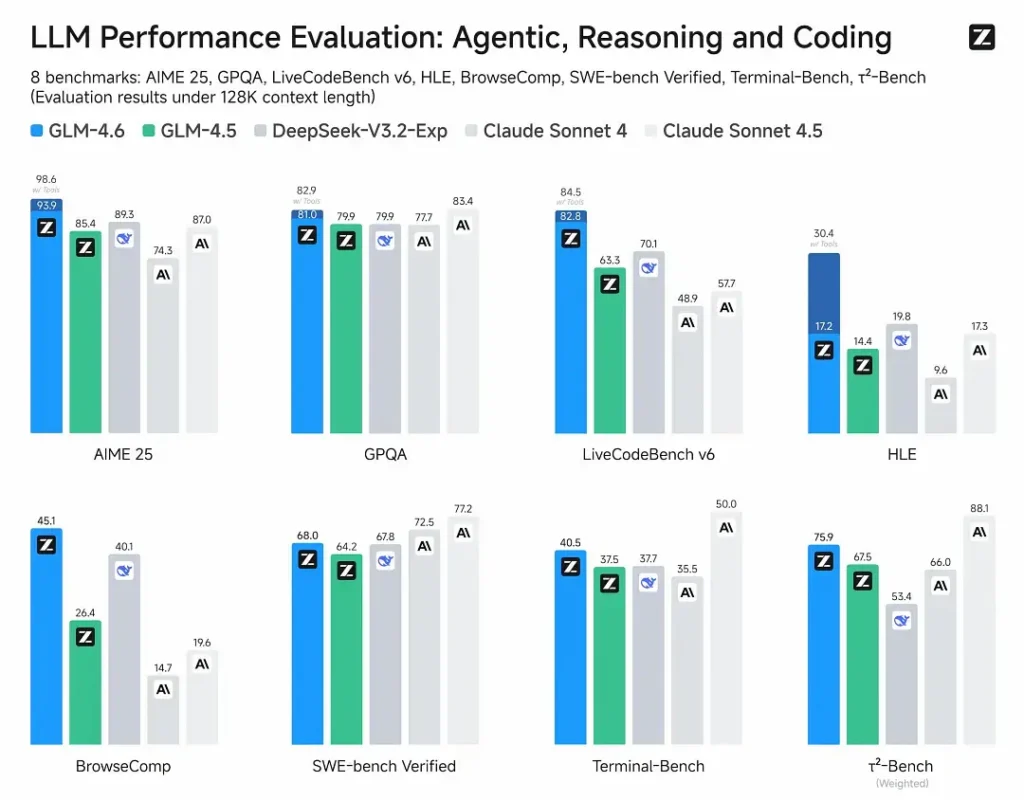
- Opublikowane oceny: GLM-4.6 został przetestowany w ośmiu publicznych testach porównawczych obejmujących agentów, wnioskowanie i kodowanie, co wykazało wyraźne zyski w porównaniu z GLM-4.5W testach kodowania w warunkach rzeczywistych, ocenianych przez ludzi (rozszerzony CC-Bench), GLM-4.6 wykorzystuje ~15% mniej tokenów w porównaniu z GLM-4.5 i publikuje ~48.6% wskaźnik wygranych vs Anthropic's Sonet Claude'a 4 (prawie równorzędne wyniki w wielu rankingach).
- Pozycjonowanie: wyniki wskazują, że GLM-4.6 jest konkurencyjny w stosunku do wiodących modeli krajowych i międzynarodowych (podano przykłady DeepSeek-V3.1 i Claude Sonnet 4).
Ograniczenia i ryzyko
- Halucynacje i błędy: Podobnie jak wszystkie obecne programy LLM, GLM-4.6 może zawierać i zawiera błędy merytoryczne — dokumentacja Z.ai wyraźnie ostrzega, że wyniki mogą zawierać błędy. Użytkownicy powinni stosować weryfikację i pobieranie/RAG w przypadku treści krytycznych.
- Złożoność modelu i koszt obsługi: Kontekst 200K i bardzo duże dane wyjściowe drastycznie zwiększają zapotrzebowanie na pamięć i opóźnienia, a także mogą podnieść koszty wnioskowania; do działania na dużą skalę wymagana jest inżynieria kwantowa/wnioskowania.
- Luki w domenach: chociaż GLM-4.6 informuje o wysokiej wydajności agenta/kodowania, niektóre publiczne raporty nadal wskazują, opóźnienia w niektórych wersjach Konkurujących modeli w określonych mikrotestach (np. niektóre metryki kodowania w porównaniu z Sonnet 4.5). Oceń je dla każdego zadania przed wymianą modeli produkcyjnych.
- Bezpieczeństwo i polityka: otwarte obciążenia zwiększają dostępność, ale także rodzą pytania dotyczące zarządzania (łagodzenie, zabezpieczenia i red-teaming pozostają odpowiedzialnością użytkownika).
Przykłady użycia
- Systemy agentowe i orkiestracja narzędzi: długie ślady agentów, planowanie przy użyciu wielu narzędzi, dynamiczne wywoływanie narzędzi; kluczowym argumentem sprzedaży jest dostrajanie agentowe modelu.
- Asystenci kodowania w świecie rzeczywistym: generowanie kodu wieloobrotowego, przegląd kodu i interaktywni asystenci IDE (zintegrowani z Claude Code, Cline, Roo Code — według Z.ai). Poprawa wydajności tokenów uczynić go atrakcyjnym dla intensywnie użytkowanych planów deweloperskich.
- Przepływy pracy z długimi dokumentami: podsumowanie, synteza wielu dokumentów, długie analizy prawne/techniczne ze względu na okno 200K.
- Tworzenie treści i postaci wirtualnych: rozbudowane dialogi, spójne utrzymanie osobowości w scenariuszach wieloetapowych.
Porównanie GLM-4.6 z innymi modelami
- GLM-4.5 → GLM-4.6: zmiana skokowa w rozmiar kontekstu (128 KB → 200 KB) oraz wydajność tokenów (~15% mniej tokenów na CC-Bench); ulepszone wykorzystanie agentów/narzędzi.
- GLM-4.6 kontra Claude Sonnet 4 / Sonnet 4.5: Z.ai raportuje niemalże parytet w kilku rankingach i ~48.6% wskaźnik wygranych w rzeczywistych zadaniach programistycznych CC-Bench (czyli ostra konkurencja, z kilkoma mikrobenchmarkami, w których Sonnet nadal prowadzi). Dla wielu zespołów inżynierskich GLM-4.6 jest pozycjonowany jako ekonomiczna alternatywa.
- GLM-4.6 a inne modele długoterminowego kontekstu (DeepSeek, warianty Gemini, rodzina GPT-4): GLM-4.6 kładzie nacisk na przepływy pracy kodowania w szerokim kontekście i agentowego; względne zalety zależą od metryki (efektywność tokenów/integracja agentów w porównaniu z dokładnością syntezy kodu źródłowego lub potokami bezpieczeństwa). Wybór empiryczny powinien być oparty na konkretnym zadaniu.
Najnowszy flagowy model Zhipu AI, GLM-4.6, wydany: 355 mld parametrów całkowitych, 32 mld aktywnych. Przewyższa GLM-4.5 pod względem wszystkich podstawowych możliwości.
- Kodowanie: zgodne z Sonet Claude'a 4, najlepszy w Chinach.
- Kontekst: Rozszerzono do 200 tys. (z 128 tys.).
- Rozumowanie: Ulepszone, obsługuje wywoływanie narzędzi podczas wnioskowania.
- Wyszukaj: Ulepszone wywoływanie narzędzi i wydajność agenta.
- Pisanie: Lepiej odpowiada ludzkim preferencjom w zakresie stylu, czytelności i odgrywania ról.
- Wielojęzyczność: Ulepszone tłumaczenie międzyjęzykowe.
Jak zadzwonić GLM-**4.**6 API z CometAPI
GLM‑4.6 Ceny API w CometAPI, 20% zniżki od ceny oficjalnej:
- Tokeny wejściowe: 0.64 mln tokenów
- Tokeny wyjściowe: 2.56/M tokenów
Wymagane kroki
- Zaloguj się do pl.com. Jeżeli jeszcze nie jesteś naszym użytkownikiem, najpierw się zarejestruj.
- Zaloguj się na swoje Konsola CometAPI.
- Pobierz klucz API uwierzytelniania dostępu do interfejsu. Kliknij „Dodaj token” przy tokenie API w centrum osobistym, pobierz klucz tokena: sk-xxxxx i prześlij.

Użyj metody
- Wybierz "
glm-4.6” punkt końcowy do wysłania żądania API i ustawienia treści żądania. Metoda żądania i treść żądania są pobierane z naszej witryny internetowej API doc. Nasza witryna internetowa udostępnia również test Apifox dla Twojej wygody. - Zastępować za pomocą aktualnego klucza CometAPI ze swojego konta.
- Wpisz swoje pytanie lub prośbę w polu treści — model odpowie właśnie na tę wiadomość.
- . Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
CometAPI zapewnia w pełni kompatybilne API REST, co umożliwia bezproblemową migrację. Kluczowe szczegóły Dokumentacja API:
- Adres URL bazowy: https://api.cometapi.com/v1/chat/completions
- Nazwy modeli: "
glm-4.6" - Poświadczenie:
Bearer YOUR_CometAPI_API_KEYnagłówek - Typ zawartości:
application/json.
Integracja API i przykłady
Poniżej znajduje Python Fragment kodu demonstrujący, jak wywołać GLM‑4.6 za pomocą API CometAPI. Zastąp <API_KEY> oraz <PROMPT> odpowiednio:
import requests
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": "Bearer <API_KEY>",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "<PROMPT>"}
],
"max_tokens": 512,
"temperature": 0.7
}
response = requests.post(API_URL, json=payload, headers=headers)
print(response.json())
Kluczowe parametry:
- model:Określa wariant GLM‑4.6
- max_tokens: Kontroluje długość wyjściową
- temperatura:Dostosowuje kreatywność kontra determinizm
Zobacz też Sonet Claude'a 4.5